תיאוריה -אשכול
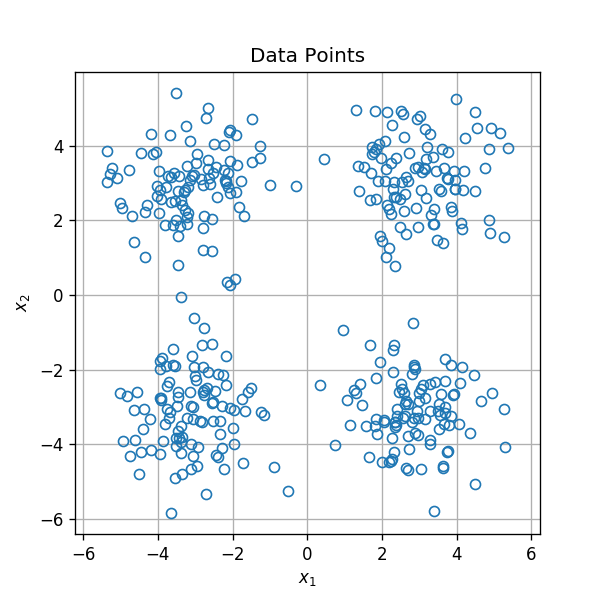
המטרה באלגוריתמי אשכול הינה לחלק אוסף של פרטים לקבוצות המכונים אשכולות (clusters), כאשר לכל קבוצה איזשהן תכונות דומות.
 ⇦
⇦ 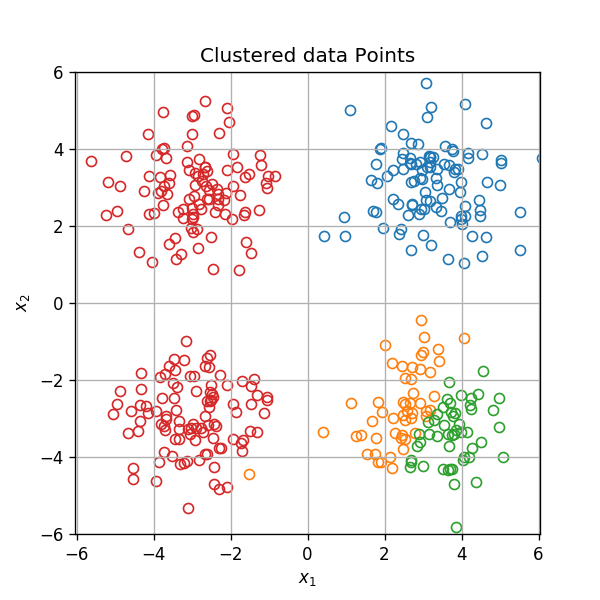
2 דוגמאות למקרים שבהם נרצה לאשכל אוסף נתונים:
- על מנת לבצע הנחות על אחד מהפרטים באשכול על סמך פרטים אחרים באשכול. לדוגמא: להציע ללקוח מסויים בחנות אינטרנט מוצרים על סמך מוצרים שקנו לקוחות אחרים באשכול שלו.
- לתת טיפול שונה לכל אשכול. לדוגמא משרד ממשלתי שרוצה להפנות קבוצות שונות באוכלוסיה לערוצי מתן שירות שונים: אפליקציה, אתר אינטרנט, נציג טלפוני או הפניה פיסית למוקד שירות.
אלגוריתמי אשכול שונים
קיימות דרכים רבות לבצע אישכול לאוסף של נתונים. בהתאם לכך קיימים גם מספר רב של אלגוריתמים לעשות כן. בתיעוד של החבילה הפייתונית scikit-learn, בה נעשה שימוש רב בתרגילים הרטובים בקורס, ישנה השוואה בין האשכולות המתקבלים מאלגוריתמים האישכול השונים בחבילה, בעבור שישה toy models דו מימדיים:
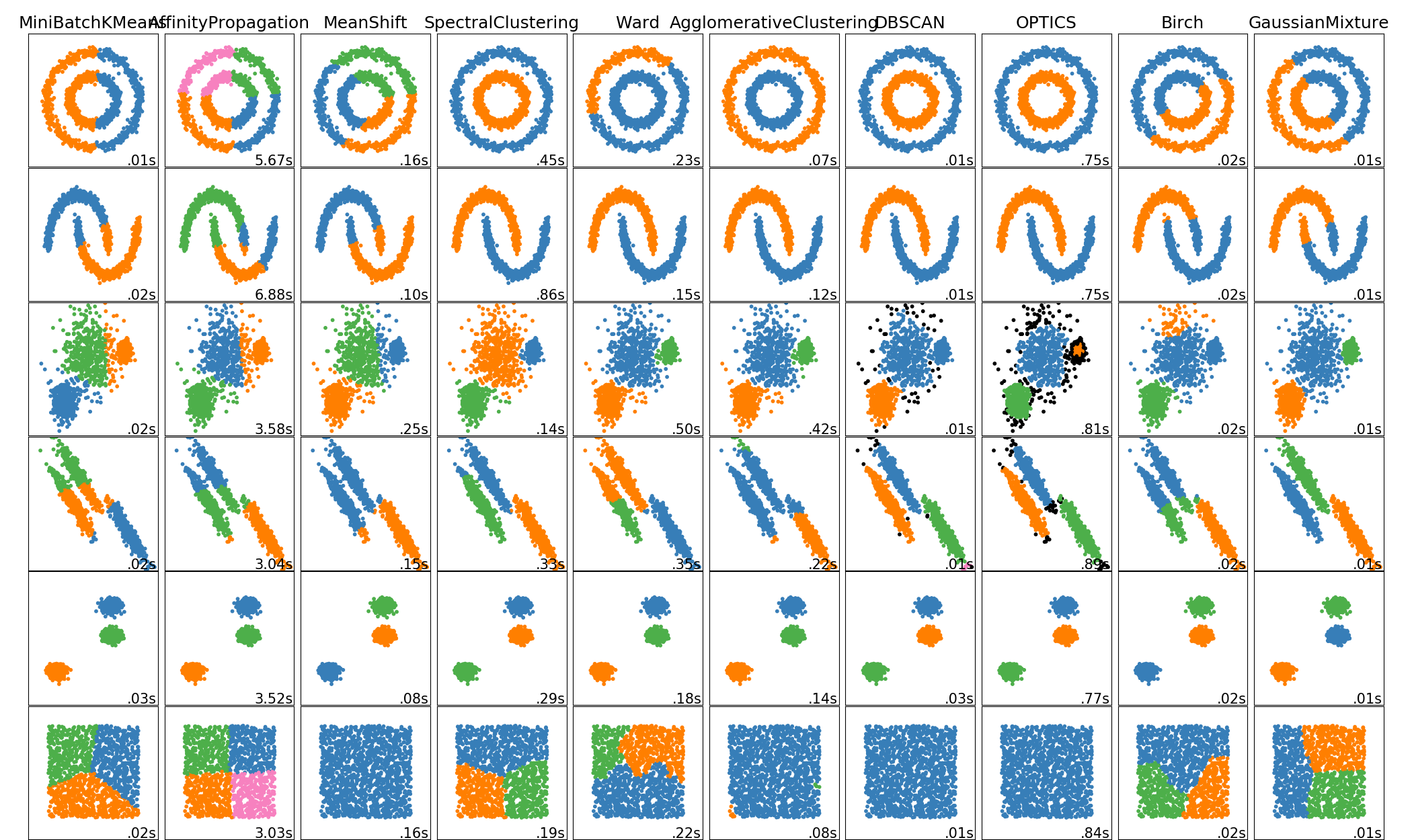
נציין כי לרוב נעבוד עם נתונים ממימד גבוה, שם לא נוכל, כמו כאן, לצייר את האשכולות על מנת להבין את אופי החלוקה.
בקורס זה נלמד על האלגוריתם K-means (העמודה השמאלית ביותר).
האלגוריתם K-means
סימונים:
- - מספר האשכולות (גודל אשר נקבע מראש).
- - אוסף האינדקסים של האשכול ה-. לדוגמא:
- - גודל האשכול ה- (מספר הפרטים בקבוצה)
- - חלוקה מסויימת לאשכולות
- - החלוקה האופטימאלית (תחת קריטריון מסויים)
בהינתן אוסף של וקטורים, האלגוריתם K-Means מנסה למצוא את החלוקה של הוקטורים לאשכולות, שבעבורה הסכום על פני כל הוקטורים של המרחק הריבועי הממוצע בין הוקטור לבין שאר חברי האשכול שלו, יהיה מינמאלי. זאת אומרת, K-means, מנסה לפתור את הבעיה הבאה :
(ה2 במכנה אינו משפיע על בעיית האופטימיזציה, והוא שם על מנת לבטל את הסכימה הכפולה על כל זוג פרטים)
הבעיה השקולה
מרכז המסה (center of mass or centroid) או המרכז של אשכול מוגדר כנקודה הממוצעת של כל הפריטים בו:
ניתן להראות כי בעיית האופטימיזציה לעיל, שקולה לבעיה של מיזעור הסכום על פני כל הוקטורים של המרחק הריבועי בין הוקטור למרכז המסה של האשכול שלו:
שלבי האלגוריתם
האלגוריתם K-Means הוא אלגוריתם איטרטיבי אשר מופעל באופן הבא:
- איתחול: , בחירת מרכזי אשכולות
- חזרה עד להתכנסות (עד אשר ):
-
שיוך כל נקודה לאשכול, על פי המרכז הקרוב עליו ביותר, כלומר, שייך לקבוצה אם :
(במקרה של שני מרכזים במרחק זהה נבחר בזה בעל האינדקס הנמוך יותר).
- עדכון מרכזי האשכולות על פי: (אם אז )
- קידום:
-
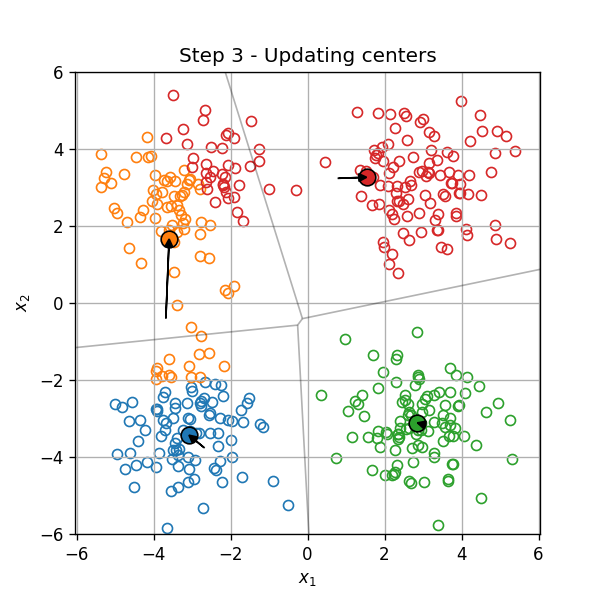
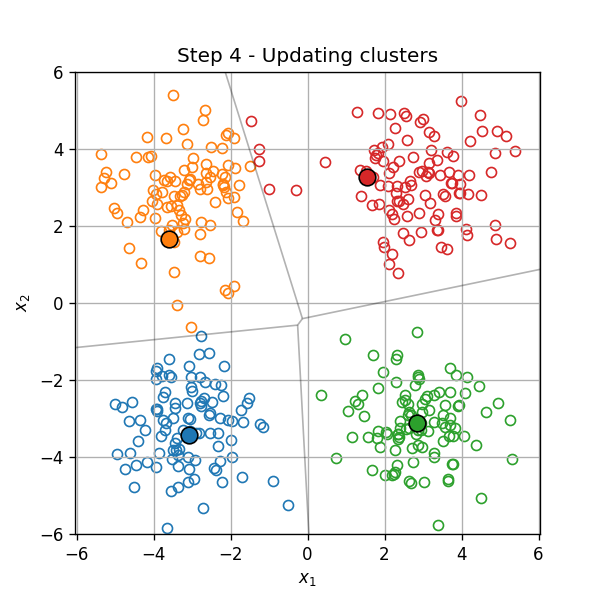
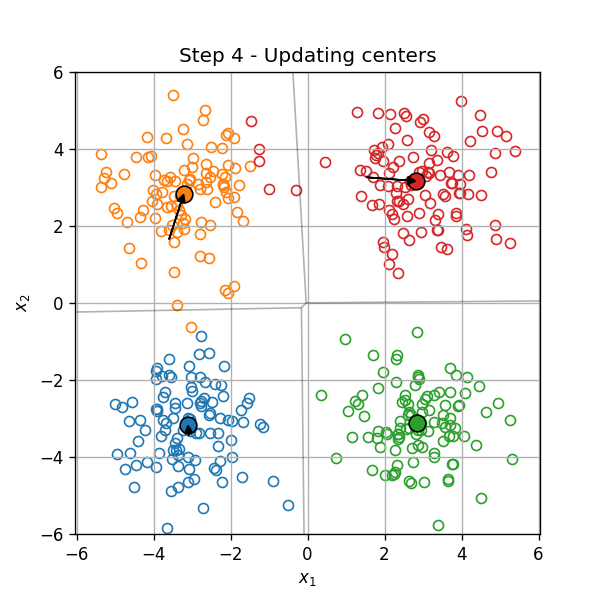
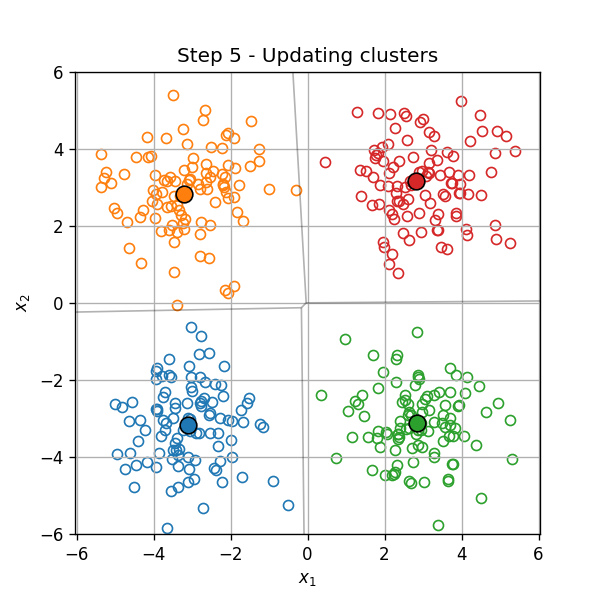
דוגמא
אתחול (וחלוקה ראשונית לאשכולות):
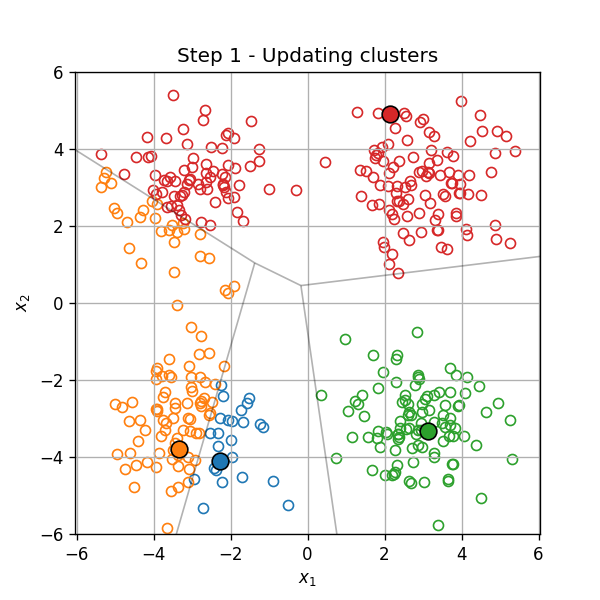
עדכון המרכזים:
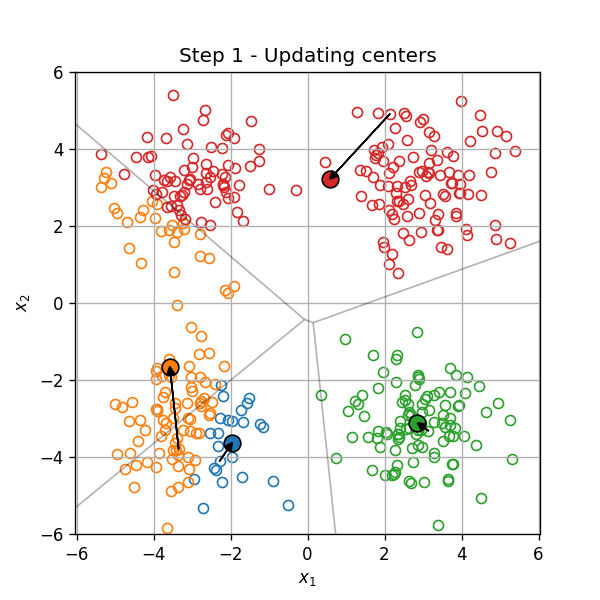
עדכון האשכולות:
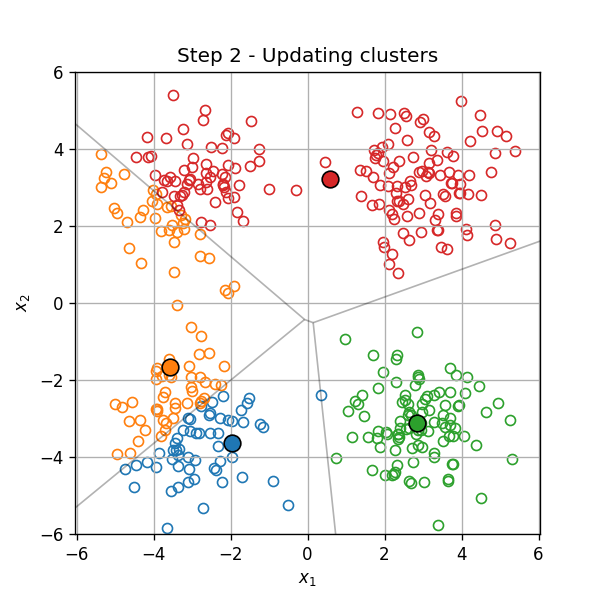
עדכון המרכזים:
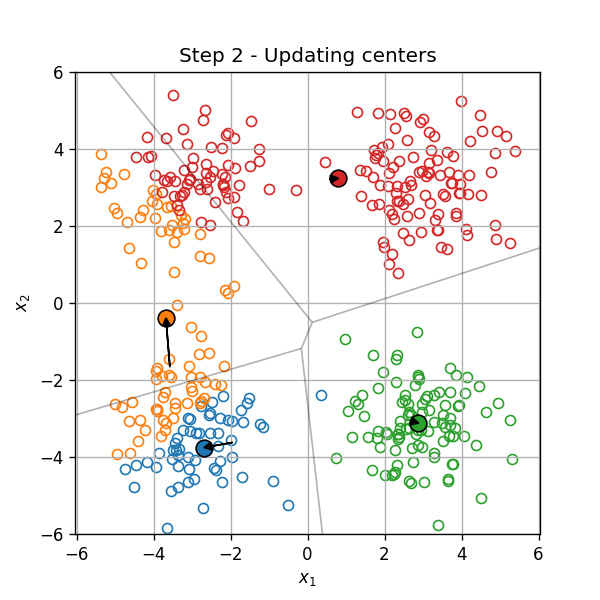
וחוזר חלילה (הסדר הוא מימין לשמאל):
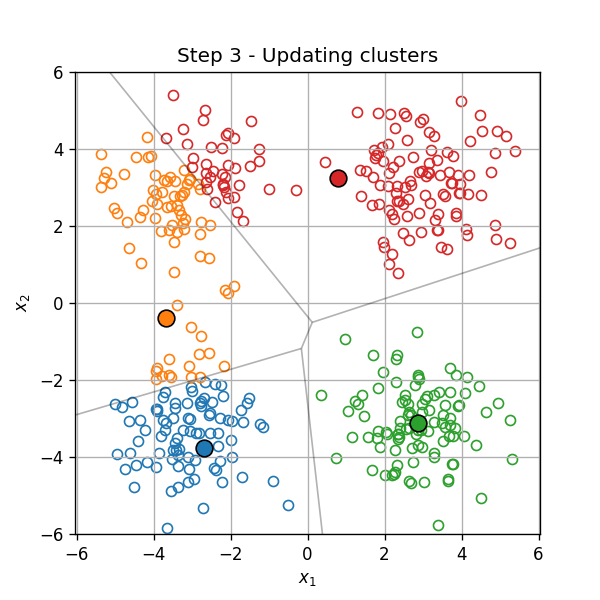
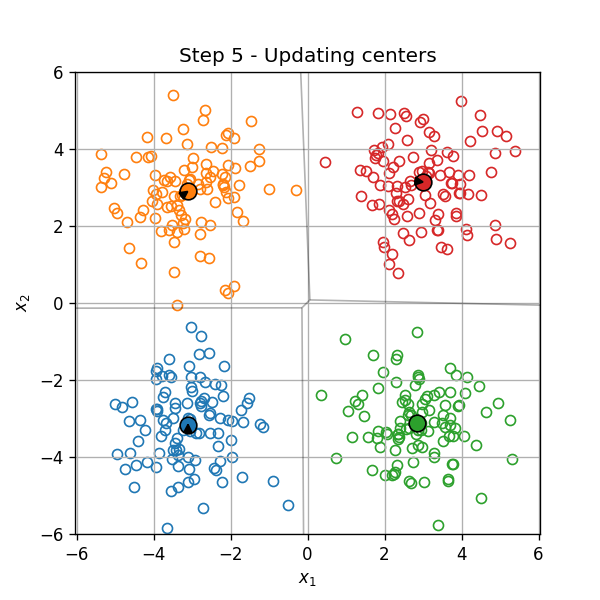
תכונות
- מובטח כי פונקציית המטרה (סכום המרחקים מהממוצעים) תקטן בכל צעד (אלגוריתם חמדן Greedy).
- מובטח כי האלגוריתם יתכנס למינימום מקומי. זאת אומרת שהוא יעצר לאחר מספר סופי של עדכונים.
- לא מובטח כי האלגוריתם יתכנס לפתרון האופטימאלי. אם כי בפועל במרבית המקרים האלגוריתם מתכנס לפתרון אשר קרוב מאד לאופטימאלי.
- אתחולים שונים יכולים להוביל לתוצאות שונות.
בחירת מספר האשכולות K
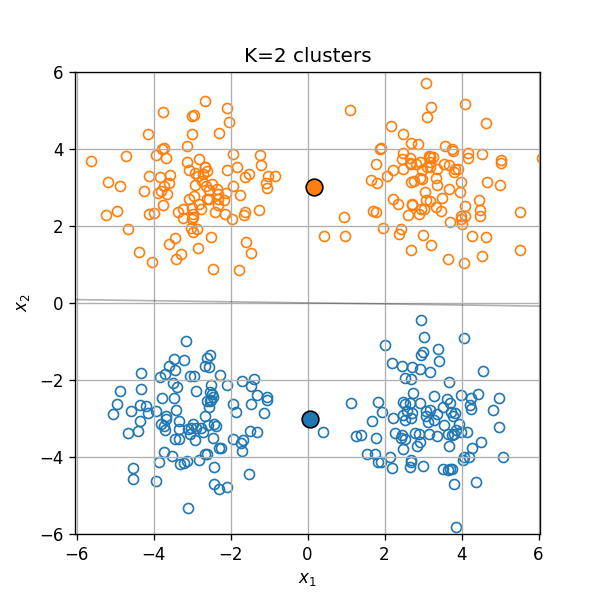
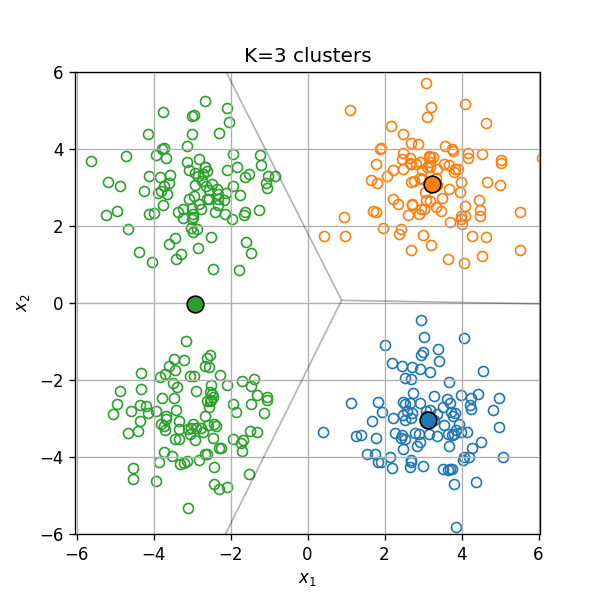
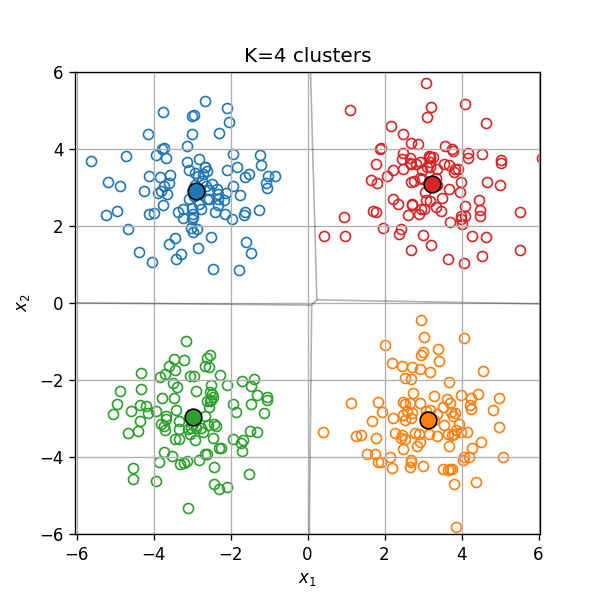
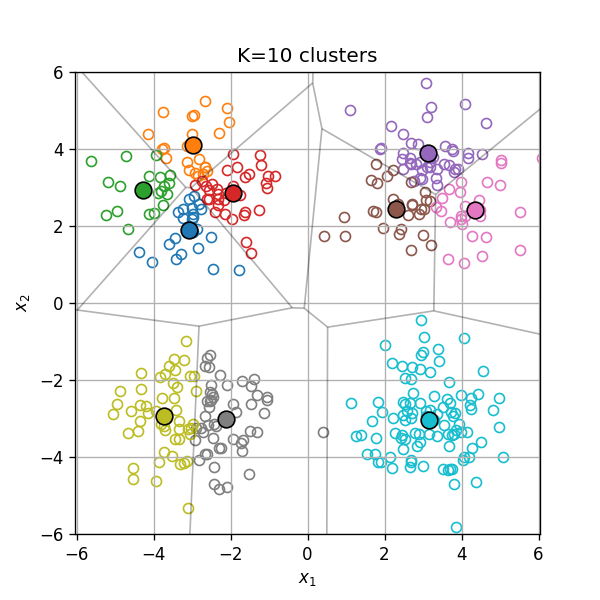
בבעיות מסויימות מספר האשכולות בו נרצה להשתמש הינו ידוע מראש, אחר במקרים אחרים יהיה עלינו לקבוע אותו כתלות בנתונים.
שיטה לקביעת מספר האשכולות: שיפור יחסי קטן
נגדיר את שגיאת האשכול בתור שורש ממוצע הריבועים Root Mean Square (RMS) של המרחקים מהממוצעים:
(זוהי למעשה פונקציית המטרה בתוספת חלוקה ב והוצאת שורש. נוח לעבוד עם גודל זה משום שהוא פחות מושפע מגודל המדגם והוא ביחידות של מרחק ולא מרחק ריבועי). שגיאה זו תלך ותקטן ככל שנגדיל את מספר האשכולות .
דרך אחת לבחירת מספר האשכולות הינה למצוא את הנקודה שבה הגדלת מספר האשכולות ב1 תוביל לשיפור יחסי זניח בשגיאת האשכול. זאת אומרת:
נראה זאת על הדוגמא הקודמת. נשרטט את השגיאה כתלות במספר האשכולות:
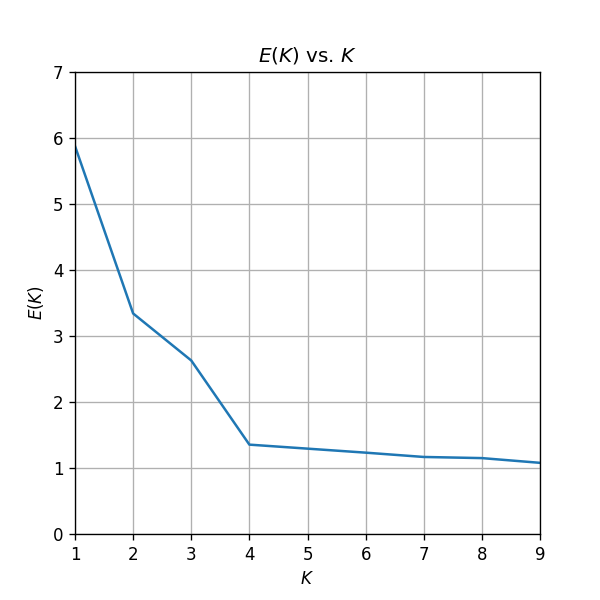
הגדלה סביב :
נשרטט את השיפור היחסי, , המתקבל מההוספה של כל אשכול שאנו מוסיפים:
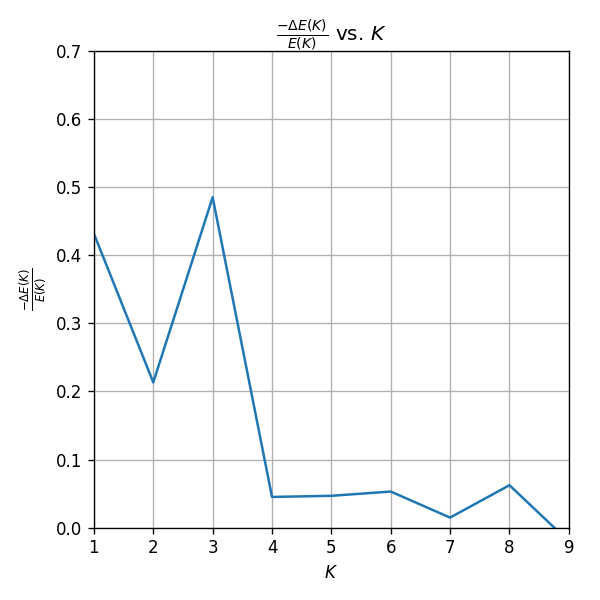
ניתן לראות כי אכן בנקודה ישנו שינו גדול בשיפוע של הגרף וכמו כן השיפור היחסי צונח משמעותית. לכן במקרה זה, הגיוני במקרה זה לבחור 4 אשכולות.
תרגילים
✍️ תרגיל 4.1
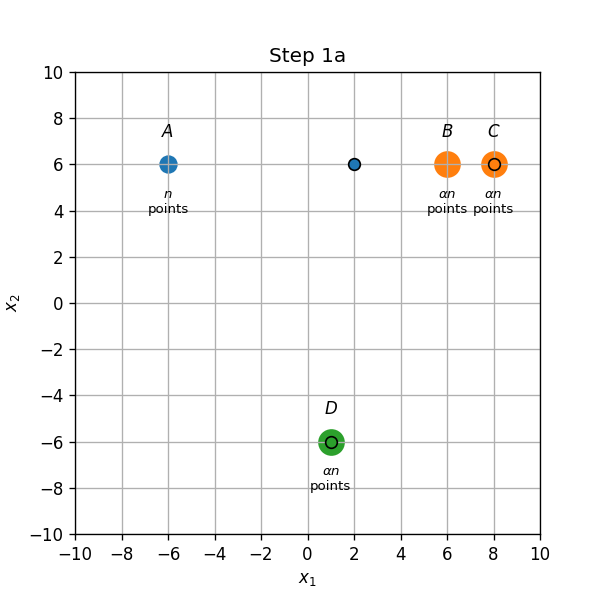
נתונות נקודות שונות:
- נקודות בקואורדינאטות
- נקודות בכל אחת מהקואורדינאטות
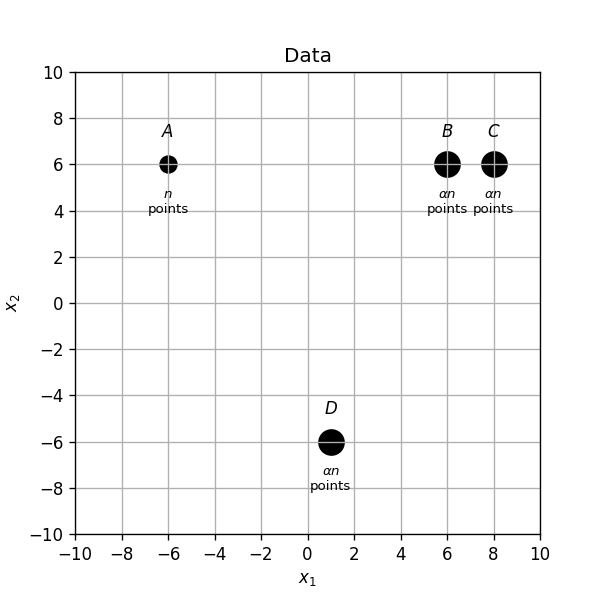 (הנקודות יושבות אחת על השניה בכל קואורדינטה, ומצויירות כעיגולים רק לצורך השרטוט). רוצים לבצע אשכול של הנקודות ל3 אשכולות בעזרת K-Means.
(הנקודות יושבות אחת על השניה בכל קואורדינטה, ומצויירות כעיגולים רק לצורך השרטוט). רוצים לבצע אשכול של הנקודות ל3 אשכולות בעזרת K-Means.
א) מאתחלים את המרכזים על ידי בחירה אקראית של 3 מתוך ארבעת הנקודות A,B,C,D. לאילו חלוקות יתכנס האלגוריתם בעבור כל אחת מארבעת האתחולים האפשריים.
ב) מהו האשכול האופטימאלי (הממזער של פונקציית המטרה)? רשמו את הפתרון כתלות בפרמטר . (ניתן להניח כי בפתרון האופטימאלי כל הנקודות שנמצאות באותו המקום משוייכות לאותו האשכול)
ג) האם קיים אתחול אשר בעבורו האלגוריתם לא יתכנס לפתרון בעל הערך המינימאלי שמצאתם בסעיף הקודם? הדגימו.
💡 פיתרון
א) נחשב את תוצאת האלגוריתם בעבור כל אחת מארבעת האתחולים:
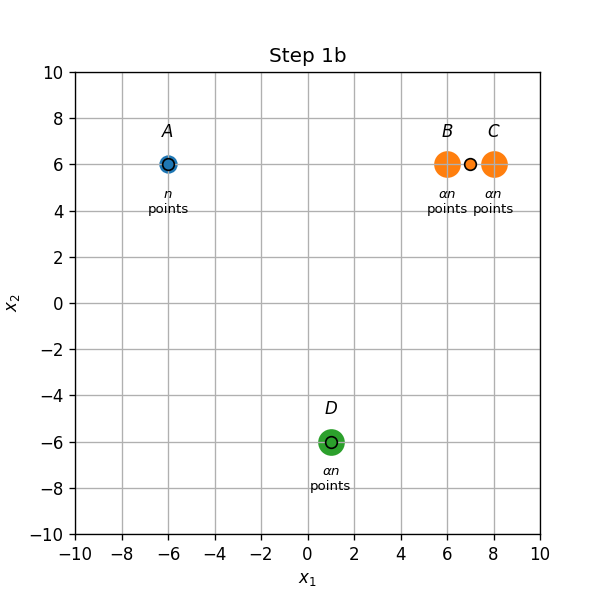
מרכזים ב A,B ו C:
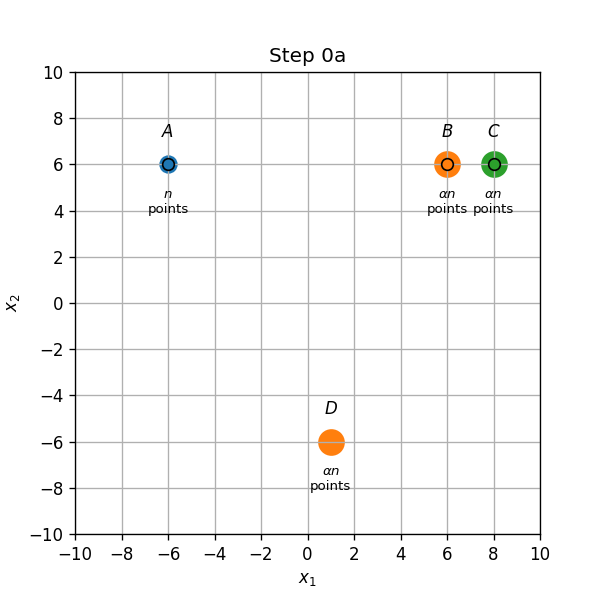
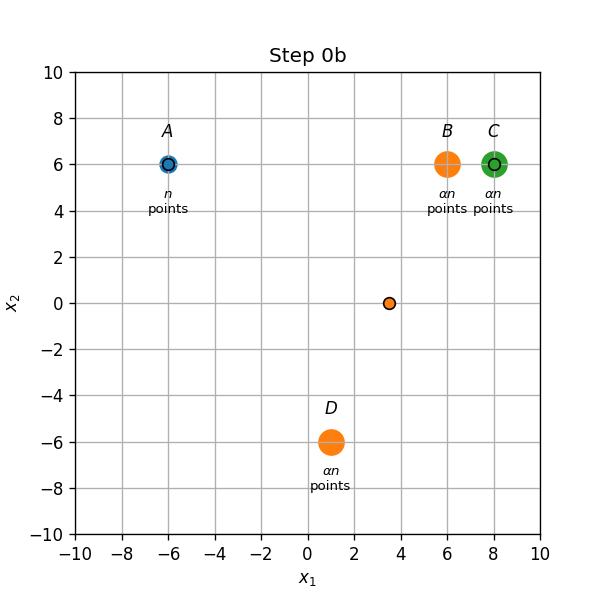
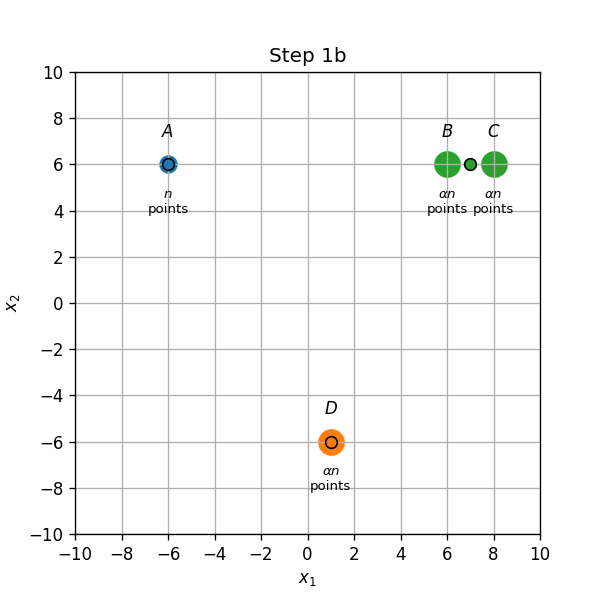
- שיוך התחלתי (0a): נקודות בA,B ו C ישוייכו למרכז אשר הנמצא עליהם, והנקודות בD ישוייכו למרכז שבB.
- עדכון מרכזים (0b): המרכז שב B יזוז לאמצע הדרך שבין הנקודות B ו D.
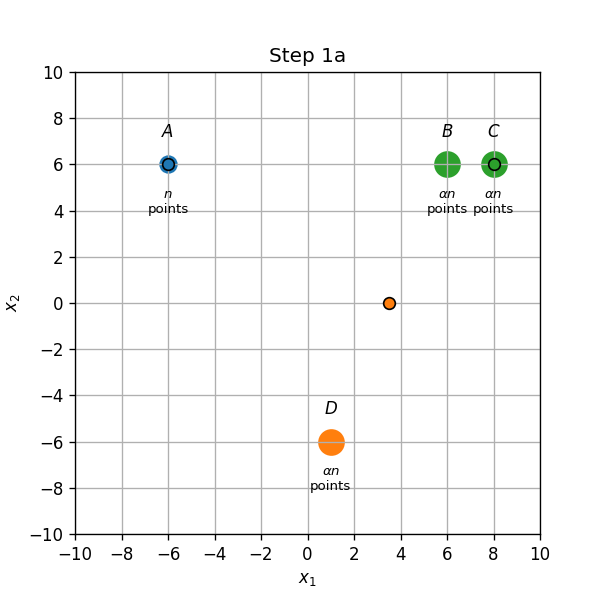
- עדכון אשכולות (1a): הנקודת שבB ישוייכו כעת למרכז שבC.
- עדכון מרכזים (1b): המרכז שבין B ל D יזוז לD, והמרכז שבC יזוז למחצית הדרך שבין B לC.
מרכזים ב A,B ו D:
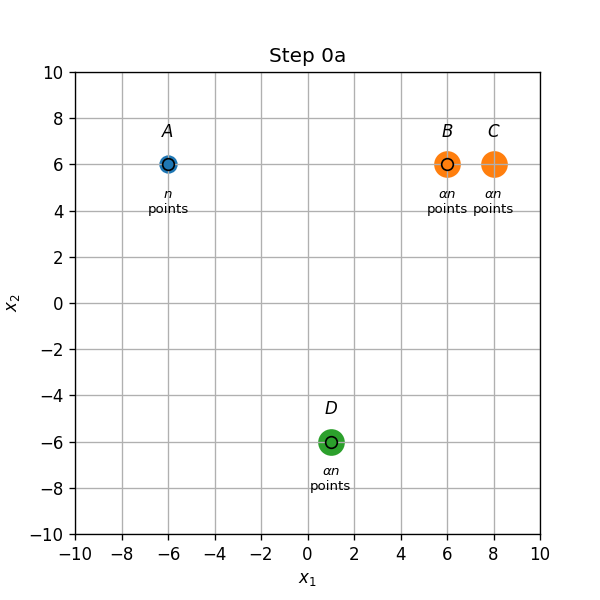
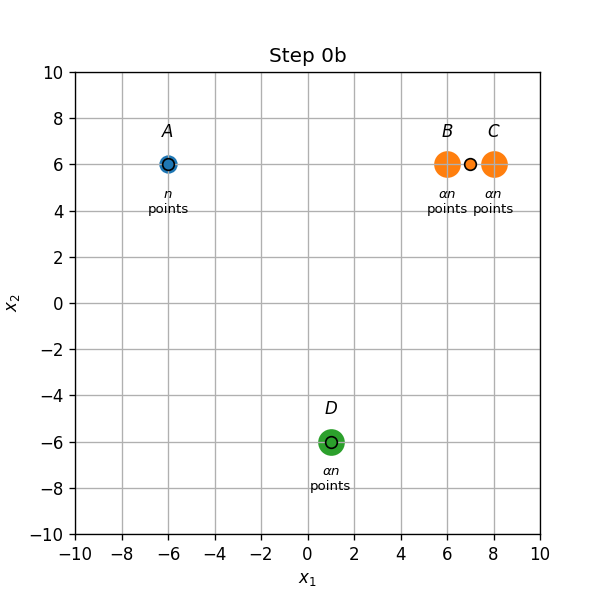
- שיוך התחלתי (0a): נקודות בA,B ו D ישוייכו למרכז אשר נמצא עליהם, והנקודות בC ישוייכו למרכז שבB.
- עדכון מרכזים (0b): המרכז שב B יזוז לאמצע הדרך שבין הנקודות B ו C.
מרכזים ב A,C ו D:
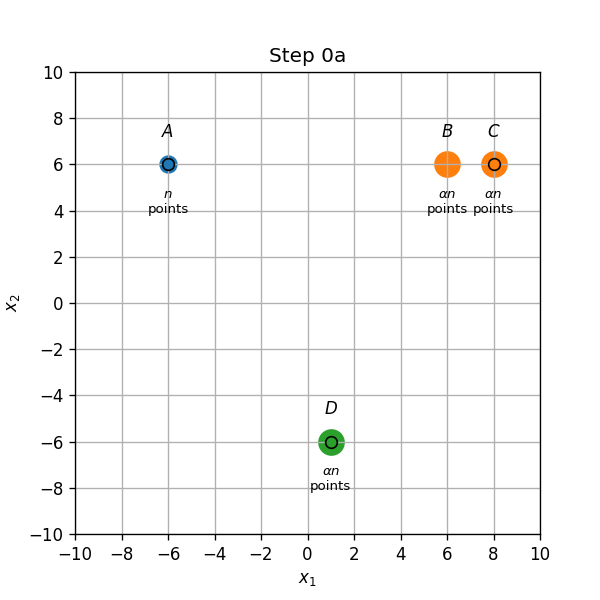
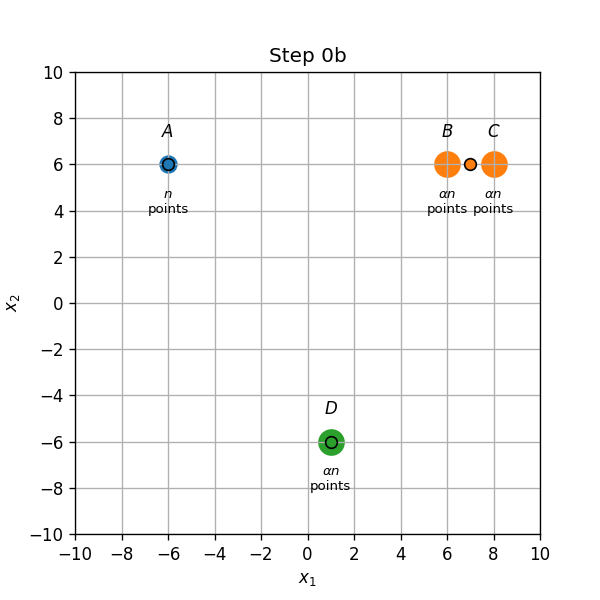
- שיוך התחלתי (0a): נקודות בA,C ו D ישוייכו למרכז אשר נמצא עליהם, והנקודות בB ישוייכו למרכז שבC.
- עדכון מרכזים (0b): המרכז שב C יזוז לאמצע הדרך שבין הנקודות B ו C.
מרכזים ב B,C ו D:
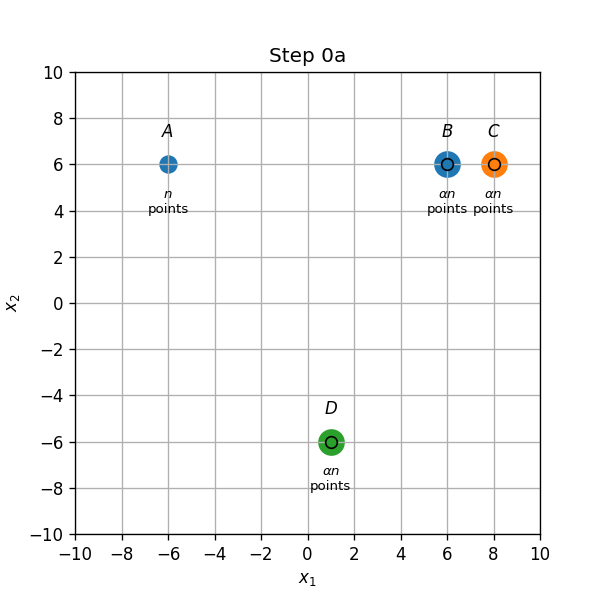
- שיוך התחלתי (0a): נקודות בB,C ו D ישוייכו למרכז אשר נמצא עליהם, והנקודות בA ישוייכו למרכז שבB.
- עדכון מרכזים (0b): המרכז שב B יזוז לנקודה שהיא המרכז של הנקודות A ו B. (משום שכמות הנקודות בשתי הקבוצות שונה, נקודה זו היא לא אמצע הדרך בניהם).
השלב הבא של עידכון האשכולות תלוי במיקום של המרכז החדש.
מקרה 1: הנקודות ב-B קרובות יותר למרכז החדש מאשר למרכז שב-C ולכן האלגוריתם מסתיים.
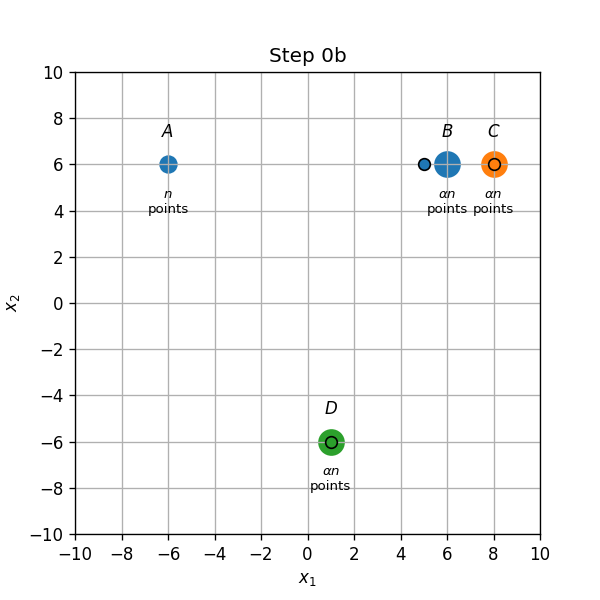
מקרה 2, המרכז החדש רחוק יותר לנקודה B מאשר הנקודה C, אזי הנקודות בB יהיו מושייכות כעת למרכז בנקודה C, והמשך האלגוריתם יהיה:
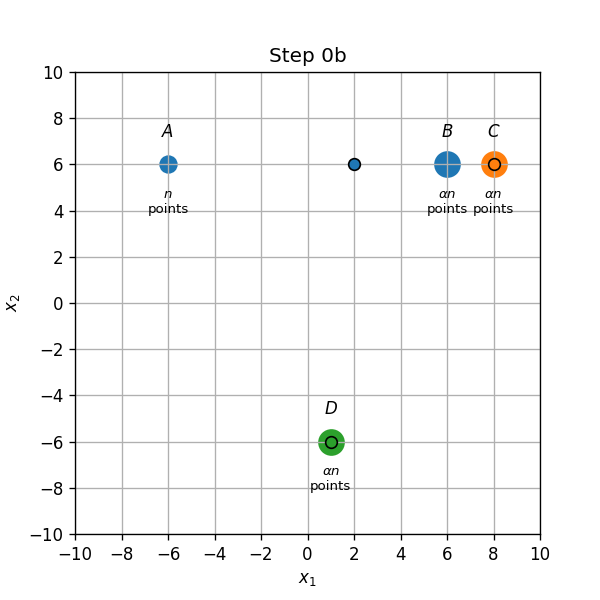
נמצא את התנאי על שבעבורו מתרחש מקרה 2. נסמן ב את המרכז שבין A לB לאחר עדכון המרכזים הראשון. המיקום של נתון על ידי הממוצע המשוכלל של הקואורדיאנטות A ו B:
על מנת שיתרחש עידכון על המרחק בין המרכז החדש נקודה B גדול מ2:
ב) אנו מועניינים למצוא את האשכול אשר מביא למינימום את הפונקציית המטרה הבאה:
נוכל לפסול פתרונות בהן ישנו אשכול ריק, משום שבמקרה זה נוכל לשייך אליו נקודות כלשהן על מנת להקטין את פונקציית המטרה. לכן הפתרון האופטימאלי חייב להיות אחד מששת האישכולים הבאים:
- (A,B), (C), (D)
- (A,C), (B), (D)
- (A,D), (B), (C)
- (B,C), (A), (D)
- (B,D), (A), (C)
- (C,D), (A), (B)
התרומה של האשכולות שמכילים נקודה בודדת לפונקציית המטרה הינה 0, ולכן יש לחשב רק את התרומה של האשכול שמכיל זוג נקודות. למשל, עבור האשכול (A,B), (C), (D) נקבל:
ועבור האשכול (B,C), (A), (D) נקבל:
נחשב את הערך של פונקצייות המטרה בעבור כל אחד מששת האשכולים:
| Clusters | Objective |
|---|---|
| (A,B), (C), (D) | |
| (A,C), (B), (D) | |
| (A,D), (B), (C) | |
| (B,C), (A), (D) | |
| (B,D), (A), (C) | |
| (C,D), (A), (B) |
נשים לב כי הפתרון האופטימאלי יהיה חייב להיות (A,B),(C),(D) או (B,C),(A),(D) (משום שכל השאר בהכרח גדולים מהם). נבדוק בעבור אלו ערכים של האשכול הראשון הינו האופטימאלי:
אם כן, בעבור הפתרון האופטימאלי הינו (A,B),(C),(D) ובעבור הפתרון האופטימאלי הינו (B,C),(A),(D).
נסכם כי עבור אתחול המרכזים בנקודות B,C ו-D נקבל:
- עבור האלגוריתם ישדך את B ו-C וזהו הפתרון האופטימאלי גלובלית.
- עבור האלגוריתם ישדך את A ו-B וזה הפתרון האופטימאלי גלובלית.
- עבור האלגוריתם ישדך את A ו-B אולם זהו אינו הפתרון הגלובלי.
נבדוק בעבור האתחולים מהסעיף הקודם, מהם המקרים שבהם האלגוריתם אינו מתכנס לפתרון האופטימאלי:
- בעבור הפתרון האופטימאלי הינו (A,B),(C),(D), אך עבור 3 מתוך 4 האיחולים שבדקנו האלגוריתם התכנס לפתרון של (B,C),(A),(D).
- בעבור הפתרון האופטימאלי הינו (B,C),(A),(D), אך במקרה של ואתחול של מרכזים ב B,C ו D מתקבל הפתרון של (A,B),(C),(D).
ג) כל מקרים שצויינו בסעיף הקודם. בנוסף,ניתן לדוגמא לאתחל שניים מתוך שלושת המרכזים בנקודות מאד רחוקות, ואז כל הנקודות ישוייכו למרכז השלישי.
בעיה מעשית
![]()
🚖 תזכורת: מדגם נסיעות המונית בNew York
עשרת הדגמים הראשונים במדגם הנסיעות בעיר New York
| passenger_count | trip_distance | payment_type | fare_amount | tip_amount | pickup_easting | pickup_northing | dropoff_easting | dropoff_northing | duration | day_of_week | day_of_month | time_of_day | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 2.768065 | 2 | 9.5 | 0.00 | 586.996941 | 4512.979705 | 588.155118 | 4515.180889 | 11.516667 | 3 | 13 | 12.801944 |
| 1 | 1 | 3.218680 | 2 | 10.0 | 0.00 | 587.151523 | 4512.923924 | 584.850489 | 4512.632082 | 12.666667 | 6 | 16 | 20.961389 |
| 2 | 1 | 2.574944 | 1 | 7.0 | 2.49 | 587.005357 | 4513.359700 | 585.434188 | 4513.174964 | 5.516667 | 0 | 31 | 20.412778 |
| 3 | 1 | 0.965604 | 1 | 7.5 | 1.65 | 586.648975 | 4511.729212 | 586.671530 | 4512.554065 | 9.883333 | 1 | 25 | 13.031389 |
| 4 | 1 | 2.462290 | 1 | 7.5 | 1.66 | 586.967178 | 4511.894301 | 585.262474 | 4511.755477 | 8.683333 | 2 | 5 | 7.703333 |
| 5 | 5 | 1.561060 | 1 | 7.5 | 2.20 | 585.926415 | 4512.880385 | 585.168973 | 4511.540103 | 9.433333 | 3 | 20 | 20.667222 |
| 6 | 1 | 2.574944 | 1 | 8.0 | 1.00 | 586.731409 | 4515.084445 | 588.710175 | 4514.209184 | 7.950000 | 5 | 8 | 23.841944 |
| 7 | 1 | 0.804670 | 2 | 5.0 | 0.00 | 585.344614 | 4509.712541 | 585.843967 | 4509.545089 | 4.950000 | 5 | 29 | 15.831389 |
| 8 | 1 | 3.653202 | 1 | 10.0 | 1.10 | 585.422062 | 4509.477536 | 583.671081 | 4507.735573 | 11.066667 | 5 | 8 | 2.098333 |
| 9 | 6 | 1.625433 | 1 | 5.5 | 1.36 | 587.875433 | 4514.931073 | 587.701248 | 4513.709691 | 4.216667 | 3 | 13 | 21.783056 |
❓️ הבעיה: מציאת חניונים
חברת מוניות רוצה לשכור מגרשי חניה ברחבי העיר NYC בהם יוכלו לחכות המוניות שלה בין הנסיעות.
לשם כך היא מעוניינת לבחור באופן אופטימאלי את המיקומים של מגרשי החניות האלו כך שהמרחק הממוצע מנקודת הורדת הנוסע למרגש החניה הקרוב יהיה מינימאלי.
שדות רלוונטיים
הפעם נתמקד בשתי השדות:
- dropoff_easting - הקואורדינאטה האורכית (מזרח-מערב) של סיום הנסיעה
- dropoff_northing - הקואורדינאטה הרוחבית (צפון-דרום) של סיום הנסיעה
(למתעניינים: הקואורדינאטות נתונות בUTM-WGS84, היחידות הן בקירוב קילומטר).
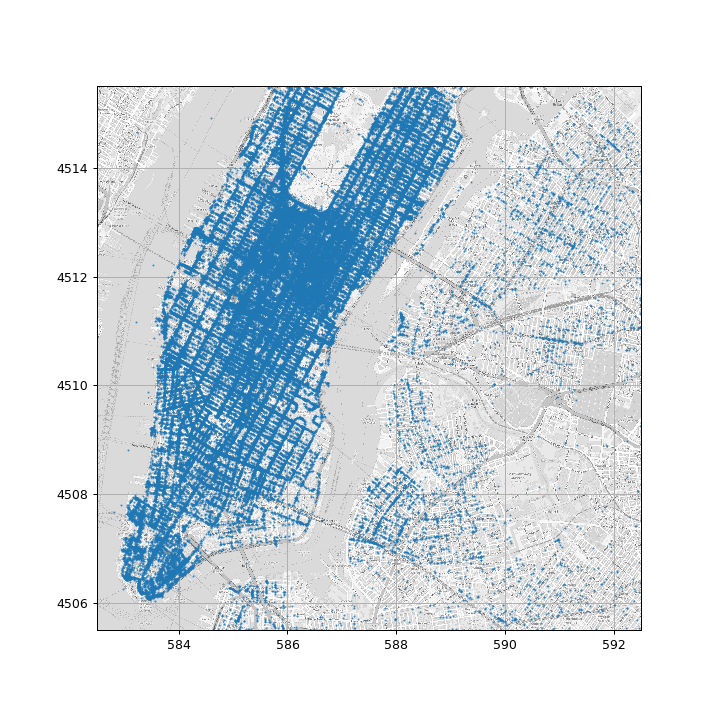
ויזואליזציה של נקודות ההורדה
הגדרה פורמאלית של הבעיה
נשתמש בסימונים הבאים:
- הוקטור האקראי של מיקום סיום הנסיעה
- : המיקום של מגרש החניה ה-.
- : מספר הנסיעות במדגם.
המטרה: למצוא את מיקומי החניונים האופטימאליים אשר ממזערים את:
מכיוון שאנו לא יודעים את הפילוג של נחליף את התוחלת על בתוחלת האמפירית
את הבעיה שקיבלנו ניתן לרשום כבעיית אשכול. נגדיר את האשכול , כאוסף כל הנסיעות שהחניון ה הוא הקרוב ביותר לנקודת הסיום שלהן. באופן זה נוכל לרשום את הפונקציית המטרה שלנו באופן הבא:
פתרון באמצעות K-Means
נשים לב כי הבעיה שקיבלנו דומה מאד לבעיה אותה K-Means מנסה לפתור, עם הבדל משמעותי אחד. K-Means ממזער את המרחק הריבועי הממוצע בעוד שאנו מחפשים למזער את המרחק האוקלידי. ישנם אלגוריתמים מורכבים יותר אשר פותרים את הבעיה שלנו, אך לבינתיים נשאר עם K-Means.
נציין שזהו מצב נפוץ שבו איננו מסוגלים לפתור בעיה מסויימת באופן ישיר אז אנו פותרים בעיה דומה לה בתקווה לקבל תוצאות מספקות, אך לא בהכרח אופטמאליות.
✍️ תרגיל 4.2
1) השתמשו באלגוריתם K-Means על מנת לבחור את המיקום של 10 מגרשי חניה.
2) חשבו את ה- Empirical Risk.
💡 פתרון
תוצאות ההרצה המתקבלות:
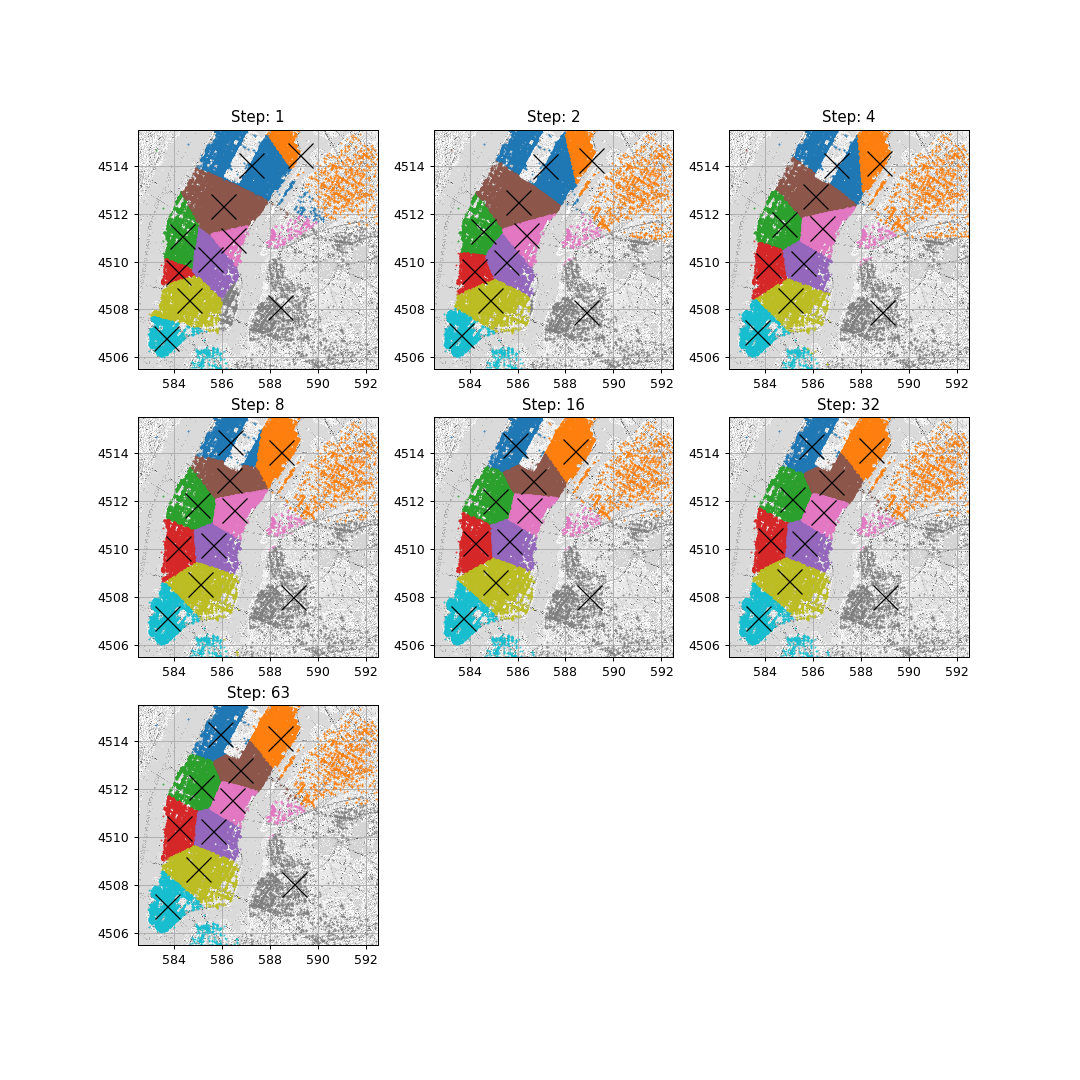
המרחק נסיעה הממוצע המתקבל הינו 700 מ’.
✍️ תרגיל 4.3
1) ציינו שתי סיבות מדוע המיקומים שקיבלנו הם לא בהכרח אופטימאליים
2) הציעו דרכים לשפר את התוצאות על סמך הסיבות מסעיף הקודם.
💡 פתרון
שתי סיבות לחוסר אופטימאליות והצעות לשיפור:
1) K-Mean לא מבטיח התכנסות למינימום הגלובלי. דרך אחת לשפר את תוצאות האלגוריתם הינה להריץ אותו מספר פעמים עם איתחולים שונים.
2) כפי שציינו קודם K-Mean ממזערת את השגיאה הריבועית הממוצעת. ניתן אם כן לשפר קלות את התוצאות על ידי שמירה על האשכולות אך תיקון המרכז לנקודה אשר ממזערת את המרחק עצמו.
הערה הנקודה אשר ממזערת את המרחק עצמו בינה לבין כל שאר הנקודות באשכול נקראת החציון הגיאומטרי The Geometric Median (wiki). ניתן למצוא נקודה זו על ידי שימוש באלגוריתם המוכונה Weiszfeld’s algorithm.
❓️ בעיה 2: מציאת מספר החניונים האופטימאלי
עד כה השתמשנו ב10 חניונים, נרצה כעת לבחור גם מספר זה בצורה מיטבית. באופן כללי ככל שנגדיל את מספר החניונים מרחק הנסיעה לחניונים יקטן, אך מנגד התחזוקה של כל חניון עולה כסף.
נניח כי:
- עלות האחזקה של חניון הינה 10k$ לחודש.
- בכל חודש יהיו בדיוק 100k נסיעות.
- עלות הנסיעה של מונית בדרך לחניון הינה 3$ לקילומטר.
✍️ תרגיל 4.4
- תחת ההנחות, נסחו את פונקציית הסיכון שמתאימה לעלות אחזקת והפעלת מגרשי חניה.
- השתמשו באלגוריתם K-Means ומצאו את ערך ה-K האופטימלי באמצעות Grid search עבור K בין 1 ל-25.
💡 פתרון
נרשום תחת הנחות אלו את העלות החודשית של אחזקת החניונים והנסיעה אליהם:
והמקבילה האמפירית:
מספר החניונים כHyper parameter
כעת עלינו לבצע אופטימיזציה גם על מספר החניונים וגם המיקום שלהם. ראינו כיצד ניתן למצוא פתרון בעבור נתון, אך אין לנו דרך פשוטה להכליל את זה ל כלשהו. כן נוכל אבל לעבור על כל ערכי הרלוונטים, לפתור את הבעיה עבורם ולבסוף לקחת את הפתרון הטוב ביותר.
מקרה זה, שבו יש בידינו שיטה יעילה למצוא את הפתרון האופטימאלי רק אחרי שקיבענו חלק מהפרמטרים, הינו מקרה נפוץ. את אותם פרמטרים שאין לנו שיטה יעילה לבחור אותם אנו מכנים לרוב הHyper-parameters של המודל. שני hyper-parameters בהם כבר נתקלנו בקורס הינם:
- מספר ורוחב התאים של היסטוגרמה
- רוחב וסוג הגרעין בKDE
לרוב נאלץ לבחור את ערכם של הhyper-parameters על ידי:
- חיפוש על גריד (grid search) או מעבר על כל האפשרויות (brute force).
- ניסוי וטעיה. כאשר לרוב נתחיל מאיזשהו ניחוש מושכל.
פתרון באמצעות K-Means וסריקת על K.
נריץ את אלגוריתם הK-Means בעבור כל ערך של בתחום , נשרטט את עלות הנסיעה, עלות אחזקת החניונים והעלות הכוללת:
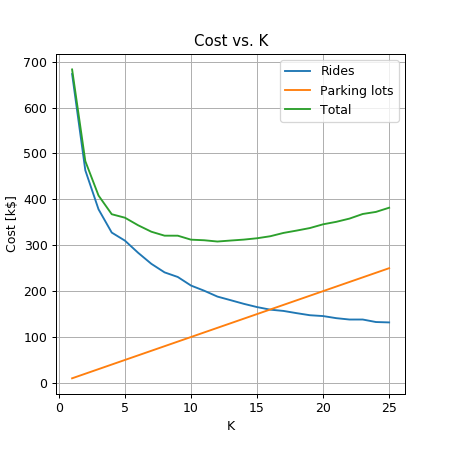
נקבל כי:
- מספר החניונים האופטימאלי הינו: 12.
- מרחק הנסיעה הממוצע יהיה 630 מ’.
- העלות הכוללת תהיה 308.12k$ לחודש.
תרגילים נוספים
✍️ תרגיל 4.5
נתבונן בבעיית “האשכול” החד-מימדית הבאה:

כאשר הנקודות ממוקמות באופן אחיד באינטרוול ומספרן . (וכמובן ).
הראו כי האלגוריתם K-Means עם מתכנס למינימום הגלובלי של השגיאה הריבועית מכל תנאי התחלה סביר (כלומר, המרכזים ההתחלתיים ממוקמים באינטרוול ).
💡 פיתרון
נסמן ב את נקודת ההחלטה באיטרציה וב- את המרכזים באיטרציה . בצעד הראשון נקבל כי:
באיטרציה ה נקבל ש:
נרשום את כלל הרקוסרסיה של :
מכאן שבגבול מתקיים כי , שזהו כמובן הפתרון האופטימאלי (חלוקה של הקטע לשני חלקים שווים).