סימונים: תזכורת
- - מספר הדגימות במדגם
- - הדגם ה
- , - משתנים/וקטורים אקראיים
- - הריאליזציה שמיוחסת לדגם . ערכים אלו נקראים לרוב .data points.
- - המדגם (אשר כולל ריאליזציות של וקטורים אקראיים בלתי תלויים סטטיסטית ובעלי פילוג זהה, i.i.d)
- - פונקציית ההסתברות (PMF) או הצפיפות ההסתברות (PDF) של משתנה/וקטור אקראי.
- - פנקציית הפילוג המצרפי של משתנה/וקטור אקראי.
- - פונקציית אינדיקטור של האם המאורע התרחש, לדוגמא: .
- אנו נשתמש בסימון “כובע” (“hat”) על מנת לציין שערוך של ערך בלתי ידוע. לדוגמא נסמן לשערוך של
מכאן והלאה נשמיט לרוב את שם המשתנה בפונקציות הפילוג במקרים בהם ברור באיזה משתנה אקראי מדובר:
תיאוריה
המטרה
להעריך את מתוך הדוגמאות במדגם .
כפי שנלמד בהרצאה, ניתן להבחין בין הגישות הבאות להסקה סטטיסטית:
-
גישה פרמטרית לעומת גישה לא-פרמטרית (א-פרמטרית)
-
גישה בייסיאנית לעומת גישה לא-בייסיאנית (קלאסית \ תדירותית).
הגישה הפרמטרית והלא פרמטרית
הבעיה בגישה הלא פרמטרית
בתרגול הקודם התמקדנו בשיטות לשיערוך פילוג המכונות שיטות לא פרמטריות (או א-פרמטריות). לשיטות אלו מספר בעיות:
- שיטות אלו מניחות כי יש בידינו כמות מספקת של דגימות בכל איזור שבו ישנה הסתברות גדולה מאפס. הבעיה העיקרית עם הנחה זו הינה, שגודל המדגם שאנו צריכים על מנת לקבל שיערוך טוב גדל באופן אקספונציאלי עם מספר המשתנים האקראיים בבעיה. קל להבין זאת במקרה של משתנים בינאריים: עבור משתנה בינארי אחד ישנן שני תוצאות אפשריות, עבור משתנים ישנם תוצאות אפשריות, בכדי לשערך את ההסתברות של כל תוצאות האפשריות אנו צריכים מספיק דגימות שיכסו כל קומבינציה אפשרית של המשתנים.
- התוצאה המתקבלת בשיערוך לא פרמטרי אינה פונקציה שנוח לעבוד איתה, אלא נוסחא בשעזרתה ניתן לחשב את הפילוג בנקודה כלשהי.
הגישה הפרמטרית
נציג כעת גישה פופולרית ושימושית יותר המכונה הגישה הפרמטרית. בגישה זו אנו מניחים כי הפילוג הנדרש הינו בעל צורה ידועה, המוגדרת עד כדי וקטור פרמטרים , כלומר בהינתן המודל הפרמטרי, אנו נרצה למצוא את סט הפרמטרים שיתאים בצורה הטובה ביותר ל-dataset.
במילים אחרות: בגישה זו אנו נציע משפחה של פונקציות פרמטריות, לדוגמא משפחת הגאוסיאנים עם תוחלת ושונות כלשהם, בתקווה כי נוכל לקרב את פונקציית הפילוג בעזרת אחת הפונקציות מהמשפחה על ידי בחירה מתאימה של הפרמטרים. את משפחת הפונקציות הזו אנו מכנים המודל, או המודל הפרמטרי. את סט הפרמטרים של המודל נהוג לייצג כוקטור ולסמנו ב-. המטרה שלנו, אם כן, הינה בהינתן מודל פרמטרי כלשהו, לשערך את וקטור הפרמטרים האופטימאלי שבעבורו המודל מתאים בצורה מיטבית למדגם הנתון.
הערה: שימו לב כי מימד וקטור הפרמטרים מוגדר מראש ואינו תלוי ב-dataset.
נבדיל עתה בין הגישה הבייסאנית ללא-בייסיאנית לשערוך פרמטרים:
הגישה הבייסיאנית והלא-בייסיאנית
הגישה הבייסיאנית
בגישה זו אנו מניחים כי וקטור הפרמטרים הינו ריאליזציה של וקטור אקראי בעל פילוג כלשהוא . פילוג זה מכונה הפילוג הפריורי (prior distribution) או הא-פריורי (a priori distribution). מכיוון שאנו מניחים כי וקטור הפרמטרים הינו משתנה אקראי, בהינתן מדגם מסויים נוכל להתייחס לפילוג המותנה של וקטור הפרמטרים בהינתן המדגם . הפילוג המותנה מכונה הפילוג הפוסטריורי (posterior distribution) או א-פוסטריורי (a posteriori distribution) (או הפילוג בדיעבד). מתוך הפילוג המתקבל נוכל לגזור משערכים שונים עבור וקטור פרמטרים (למשל ההסתברות המקסימאלית, התוחלת וכו’).
הגישה הלא-בייסיאנית (המכונה גם: קלאסית או תדירותית (Frequintist))
בגישה זו אנו נניח כי וקטור הפרמטרים הינו גודל קבוע, אך לא ידוע. תחת גישה זו אין כל העדפה של ערך מסויים של הוקטור על פני ערך אחר. במקרה זה נסמן את הפילוג של המדגם ב על מנת לסמן שהפילוג תלוי בפרמטרים (להבדיל מהסימון של פילוג מותנה ). הפונקציה מכונה לרוב פונקציית הסבירות (likelihood), שכן היא מציינת את הסבירות לקבלת המדגם אותו קיבלנו בעבור וקטור פרמטרים מסויים , מוקבל גם לסמן אותה באופן הבא:
שיטות שיערוך
בקורס זה נתמקד בשתי שיטות שיערוך פרמטריות, האחת בייסיאנית והשניה לא.
משערך (Maximum a Posteriori (MAP (שיטה בייסיאנית)
משערך הMAP משתייך לקטגוריה של שערוך בייסיאני. בשיטה זו נבחר את המשערך האופטימאלי כוקטור הפרמטרים אשר ממקסם את צפיפות ההסתברות האפוסטריורית. כלומר:
בפועל, לרוב נשתמש בכלל בייס על מנת לחשב את צפיפות ההסתברות האפוסטריורית. על ידי שימוש בכלל בייס נקבל:
(מדוע המעבר האחרון נכון?)
ניתן לראות שלמעשה אנו מחפשים את הנקודה שמביאה למקסימום את המכפלה של:
-
ה-Likelihood, , הסבירות של המדגם שקיבלנו בהינתן וקטור הפרמטרים
-
צפיפות ההסתברות הא-פריורית, Prior: , שלוקחת בחשבון את ההנחה המקדימה שלנו על הסבירות של ערכים שונים של הפרמטרים.
משערך Maximum Likelihood Estimator (MLE) (שיטה לא בייסיאנית)
משערך הMLE משתייך לקטגוריה של שערוך לא בייסיאני. בשיטה זו נבחר את המשערך האופטימאלי כוקטור הפרמטרים אשר ממקסם את פונקציית הסבירות. כלומר:
הlog-likelihood והנחת הi.i.d.
תחת ההנחה כי הדגמים במדגם הינם i.i.d. (בעלי פילוג זהה ובלתי תלויים סטטיסטית) מתקיים כי:
בנוסף, נשתמש בעובדה של הינה פונקציה מונוטונית עולה ולכן:
מקובל לסמן את ה של פונקציית הסבירות כ
מכאן ש:
באופן זהה:
תרגילים
✍️ תרגיל 3.1 - שיערוך MLE
נתונות דגימות בלתי תלויות של משתנה אקראי : , מצאו את משערך הMLE במקרים הבאים:
א) פילוג נורמלי: עם פרמטרים ו לא ידועים.
ב) פילוג אחיד: , עם פרמטר לא יודע.
ג) פילוג אקספוננציאלי (לקריאה עצמית): . עם פרמטר לא ידוע.
ד) פילוג דיסקרטי: נתונה קוביה בעלת 6 פאות והסתברות . עם פרמטרים לא ידועים.
💡 פיתרון
א) נסמן את וקטור הפרמטרים: , כלומר
על פי הגדרה, משערך הMLE נתון על ידי:
נפתור על ידי גזירה והשוואה ל 0:
מכאן ש:
ב) פונקציית צפיפות ההסתברות של הפילוג הנתון הינה:
ולכן:
מכאן ש:
ג) פונקציית צפיפות ההסתברות של הפילוג הנתון הינה:
ולכן על פי הגדרת משערך הMLE נקבל כי:
נפתור על ידי גזירה והשוואה ל 0:
מכאן ש:
ד) נסמן את וקטור הפרמטרים .
פונקציית ההסתברות של הפילוג הנתון הינה:
רק שהפעם עלינו להתחשב באילוץ:
נמצא אם כן את משערך הMLE על ידי פתרון בעיית האופטימיזציה המאולצת הבאה:
נרשום את הLagrangian
(שימו לב: על מנת למנוע בלבול נשתמש ב לסימון פונקציית הסבירות ו לסימון של הLagrangian)
כאשר הינו מספר הפעמים אשר הערך מופיע במדגם.
נגזור את הLagrangian לפי הפרמטרים ונשווה ל-0:
קיבלנו כי
כלומר משערך הMLE הינו המדידה האמפירית של ההסתברות של לקבלת הערך מסויים.
נדון במקרי הקצה
- עבור הטלה בודדת, , שתוצאתה נקבל פונקציית צפיפות משוערכת של . זאת אומרת שתוצאת הקוביה תהיה תמיד
- בגבול שבו מתקבל על פי חוק המספרים הגדולים כי
✍️ תרגיל 3.2
נתון שהרווח היומי של חברת “רווחילי” מתפלג גאוסית . נתון לנו מדגם אשר מכיל את הרווחים של החברה ב הימים האחרונים .
לשם הפשטות נניח שהרווחים בימים שונים הינם בעלי פילוג זהה וכי הם בלתי תלויים סטטיסטית, כלומר הם משתנים i.i.d.
בשאלה זו נניח ש הינו פרמטר ידוע וקבוע ונרצה לחשב את תוחלת הרווח היומי, כלומר לשערך את . לשם כך, יוסי הציע להשתמש במודל עבור ההתפלגות הפירורית של בהתאם למחקר שביצעו על חברות שונות במשק. יוסי טען שתוחלת הרווח היומי של חברות מתפלגת נורמלי , עם פרמטרים ידועים ו .
א) חשב את משערך הMAP בהתאם למדגם ולפילוג האפריורי שהציע יוסי.
ב) נתחו את תוצאת השיערוך המתקבלת עבור ערכים שונים של ו .
💡 פיתרון
נחשב את משערך הMAP על פי הגדרה
נגזור ונשווה ל-0
קיבלנו כי:
נרשום זאת באופן מעט שונה:
כאשר:
נשים לב למספר דברים:
- הינו ממוצע הדגימות. זהו הערך אשר ממקסם את פונקציית הסבירות (והוא למעשה משערך הMLE של ).
- הערך הינו הערך אשר ממקסם את הפילוג האפריורי.
- הגודל הינו השונות של .
התוצאה שאותה קיבלנו הינה למעשה ממוצע מושכלל בין הערך אשר ממקסם את הlikelihood, אשר תלוי במדגם, לבין הערך אשר ממקסם את הפילוג האפריורי. המשקל של כל ערך שווה לאחד חלקי שונות הפילוג של אותו ערך. הגודל של אחד חלקי שונות למעשה מבטא את רמת הוודאות שיש לנו לגבי הדיוק של הערך.
ב) נסתכל על מקרי הקצה.
- כאשר אזי החלק אשר תלוי במדגם מקבל את מרבית המשקל, ומתקיים כי:
במקרה זה הפילוג האפיריורי רחב מאד ואין הבדל גדול בין ההסתברות האפריורית של ערכים יחסית קרובים ולכן ההשפעה של הפילוג האפריורי קטנה.
- כאשר אזי החלק אשר תלוי בפילוג האפריורי מקבל את מרבית המשקל, ומתקיים כי:
בעיה מעשית
![]()
🚖 תזכורת: מדגם נסיעות המונית בNew York
עשרת הדגמים הראשונים במדגם הנסיעות בעיר New York
| passenger_count | trip_distance | payment_type | fare_amount | tip_amount | pickup_easting | pickup_northing | dropoff_easting | dropoff_northing | duration | day_of_week | day_of_month | time_of_day | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 2.768065 | 2 | 9.5 | 0.00 | 586.996941 | 4512.979705 | 588.155118 | 4515.180889 | 11.516667 | 3 | 13 | 12.801944 |
| 1 | 1 | 3.218680 | 2 | 10.0 | 0.00 | 587.151523 | 4512.923924 | 584.850489 | 4512.632082 | 12.666667 | 6 | 16 | 20.961389 |
| 2 | 1 | 2.574944 | 1 | 7.0 | 2.49 | 587.005357 | 4513.359700 | 585.434188 | 4513.174964 | 5.516667 | 0 | 31 | 20.412778 |
| 3 | 1 | 0.965604 | 1 | 7.5 | 1.65 | 586.648975 | 4511.729212 | 586.671530 | 4512.554065 | 9.883333 | 1 | 25 | 13.031389 |
| 4 | 1 | 2.462290 | 1 | 7.5 | 1.66 | 586.967178 | 4511.894301 | 585.262474 | 4511.755477 | 8.683333 | 2 | 5 | 7.703333 |
| 5 | 5 | 1.561060 | 1 | 7.5 | 2.20 | 585.926415 | 4512.880385 | 585.168973 | 4511.540103 | 9.433333 | 3 | 20 | 20.667222 |
| 6 | 1 | 2.574944 | 1 | 8.0 | 1.00 | 586.731409 | 4515.084445 | 588.710175 | 4514.209184 | 7.950000 | 5 | 8 | 23.841944 |
| 7 | 1 | 0.804670 | 2 | 5.0 | 0.00 | 585.344614 | 4509.712541 | 585.843967 | 4509.545089 | 4.950000 | 5 | 29 | 15.831389 |
| 8 | 1 | 3.653202 | 1 | 10.0 | 1.10 | 585.422062 | 4509.477536 | 583.671081 | 4507.735573 | 11.066667 | 5 | 8 | 2.098333 |
| 9 | 6 | 1.625433 | 1 | 5.5 | 1.36 | 587.875433 | 4514.931073 | 587.701248 | 4513.709691 | 4.216667 | 3 | 13 | 21.783056 |
❓️ הבעיה: שיערוך הפילוג של משך הנסיעה
אנו מעוניינים לשערך את הפילוג של משך הנסיעה
💡 ניסיון 1: MLE ופילוג גאוסי
נשתמש במודל של פילוג נורמלי לתיאור הפילוג של משך הנסיעה. למודל זה שני פרמטרים, התוחלת והשונות .
פתרון
סימונים והנחות:
-
- מספר הדגמים במדגם.
- - וקטור הפרמטרים של המודל
- - המודל
ראינו כי בעבור המודל הנורמלי, ניתן למצוא את הפרמטרים של משערך הMLE באופן מפורש (אנליטית), והפתרון נתון על ידי:
בעבור המדגם הנתון נקבל:
נשרטט את ההיסטוגרמה של של משכי הנסיעה יחד עם הפילוג הנורמלי המשוערך:
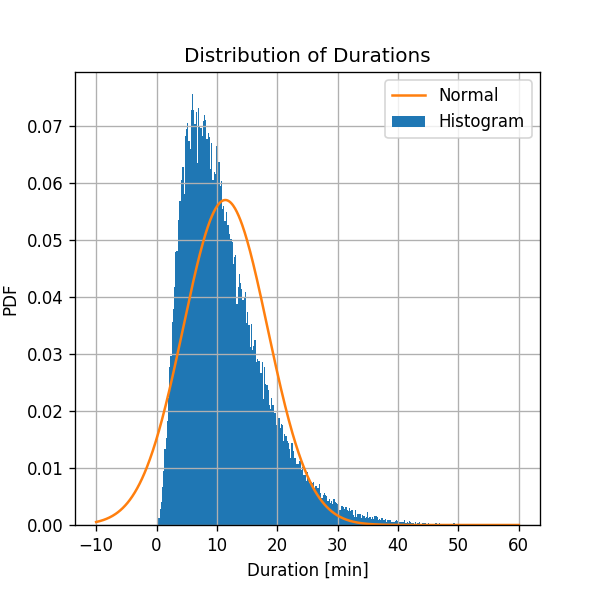
נראה כי הפילוג הנורמלי נותן קירוב מאד גס לפילוג האמיתי. במקרים רבים קירוב זה יהיה מספיק, אך במקרה זה ננסה לשפר את השיערוך שלנו.
עובדה אחת שמאד מטרידה לגבי הפילוג שקיבלנו הינה שישנו סיכוי לא אפסי לקבל נסיעות עם משך נסיעה שלילי.
ננסה להציע מודל טוב יותר.
💡 נסיון 2: MLE ופילוג Rayleigh
פילוג Rayleigh מתאר את הפילוג של האורך האוקלידי ( norm) של וקטור גאוסי דו מימדי עם תוחלת 0 וחוסר קורלציה ופילוג זהה לשני רכיבי הוקטור. במלים אחרות, עבור וקטור בעל הפילוג הבא:
פילוג Rayleigh מתאר את הפילוג של הגודל
פונקציית צפיפות ההסתברות של פילוג Reyligh נתונה על ידי:
נשים לב כי הפילוג מוגדר רק בעבור ערכים חיוביים. לפילוג זה פרמטר יחיד שנקרא פרמטר סקאלה (scale parameter). בניגוד לפילוג הנורמלי, פה אינה שווה לסטיית התקן של הפילוג.
ניתן מוטיבציה קצרה לבחירה שלנו במודל זה.
מוטיבציה לשימוש בפילוג Rayleigh
נתחיל עם ההנחה שוקטור המחבר את נקודת תחילת הנסיעה עם נקודת סיום הנסיעה הינו וקטור דו מימדי אשר מפולג נרמלית ולשם הפשטות נניח כי רכיביו מפולגים עם פילוג זהה וחסר קורלציה.
בנוסף לשם הפשטות נניח כי המונית נוסעת בקירוב בקו ישר בין נקודת ההתחלה והסיום ולכן המרחק אותו נוסעת המכונית יהיה מפולג על פי פילוג Reyleigh. נניח בנוסף כי מהירות הנסיעה קבוע ולכן משך הנסיעה פורפורציוני למרחק ולכן גם הוא יהיה מפולג על פי פילוג Reyleigh.
פתרון
לשם השלמות נסמן את וקטור הפרמטרים של ב:
במקרה זה המודל נתון על ידי:
ופונקציית ה log likelihood תהיה:
בעיית האופטימיזציה שלנו תהיה:
גם בעבור המקרה הזה נוכל לפתור את בעיית האופטימיזציה באופן אנליטי על ידי גזירה והשוואה לאפס:
בעבור המדגם הנתון נקבל:
נוסיף את השיערוך החדש שקיבלנו לגרף ממקודם:
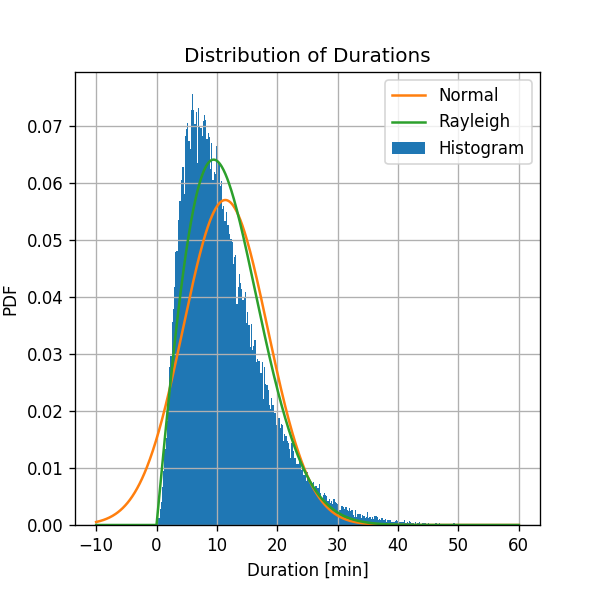
על פי הדמיון בין ההיסטוגרמה לפונקציות הפילוג ששיערכנו, נראה כי המודל של פילוג Rayleigh נותן תוצאה מעט יותר טובה מהמודל הנורמלי, בנוסף ניתן לראות גם כי כעת אין הסתברות שונה מ0 לקבל משך נסיעה שלילי.
ננסה מודל נוסף.
💡נסיון 3: MLE ו Generalized Gamma Distribution
פילוג Rayleigh הינו מקרה פרטי של משפחה כללית יותר של פונקציות פילוג המכונה Generalized Gamma Distribution. פונקציית צפיפות ההסתברות של משפחה זו נתונה על ידי:
(כשאר היא פונקציה המוכנה פונקציית גמא (gamma function) )
למודל זה 3 פרמטרים: .
בעבור ו נקבל את פילוג Rayleight כאשר .
בניגוד למקרים של פילוג נורמלי ופילוג Rayleigh, במקרה זה לא נוכל למצוא בקלות את הפרמטרים האופטימאלים של המשערך באופן אנליטי. לכן, לשם מציאת הפרמטרים נאלץ להעזר בפתרון נומרי. בפועל נעשה שימוש באחת החבילה של Python הנקראת SciPy. חבילה זו מכילה מודלים הסברותיים רבים ומכילה מספר רב של כלים הקשורים למודלים אלו, כגון מציאת הפרמטרים האופטימאלים בשיטת MLE על סמך מדגם נתון. את הפונקציות הקשורות למודל הGeneralized Gamma Distribution ניתן למצוא כאן.
אתם תעשו שימוש בפונקציות אלו בתרגיל הבית הרטוב.
שימוש בפונקציה הנ”ל, מניב את התוצאות הבאות:
נוסיף את השיערוך החדש שקיבלנו לגרף הקודם:
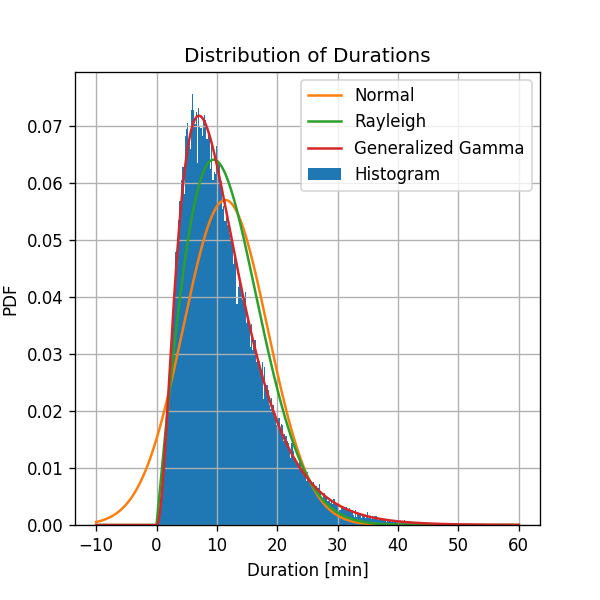
ניתן לראות המודל של Generalized Gamma Distribution אכן מניב תוצאה אשר דומה מאד לצורת ההסטוגרמה.
תרגילים
✍️ תרגיל 3.3: תרגיל ממבחן - אביב 2019, מועד ב’ שאלה 3
נתונות לנו מדידות i.i.d., כאשר מגיע מההתפלגות הבאה:
א) מצאו את משערך הMLE עבור הפרמטר בהנחה כי פרמטר ידוע
ב) מצאו את משערך הMLE עבור הפרמטר בהנחה כי פרמטר ידוע
💡 פתרון
א) פונקציית הlikelihood (הפעם כפונקציה של כי הוא המשתנה הלא ידוע בסעיף זה):
תחת התנאי כי .
פונקציית הlog-likelihood הינה:
מגזירה והשוואה לאפס נקבל:
הנגזרת השנייה שלילית ולכן זוהי אכן נקודת מקסימום.
ב) נכתוב את ה-likelihood:
נשים לב כי היא פונקציה מונוטונית עולה ב בתחום שבו . לכן שמערך הסבירות המירבית יתקבל בערך המקסימאלי האפשרי עבור בתחום זה: .