תיאוריה
סימונים
- - דוגמאות (דגימות - samples) בלתי תלויות של עם פרדיקציה ידועה .
- - מרחב הקלט. .
מרחב הפלט תלוי במשימה, נבחין בין שתי משימות שונות:
סיווג (classification)
המטרה היא סיווג דוגמאות לאחת מבין מספר סופי של מחלקות אשר הגדרנו מראש. לדוגמא: זיהוי חתול וכלב מתמונה.
- - מרחב סופי של קטגוריות (מחלקות), .
- - חזאי אשר מסווג כל ל-.
רגרסיה (regression)
המטרה הינה מציאת חזאי אשר מקיים את הקשר הבא , לכל צמד . הפלט הינו ערך מסויים שאנו רוצים לחזות באמצעות החזאי ובהינתן קלט .
לדוגמא: מתן תחזית לערך מניה מסויימת על סמך נתוני הבורסה.
מסווג כל ל .
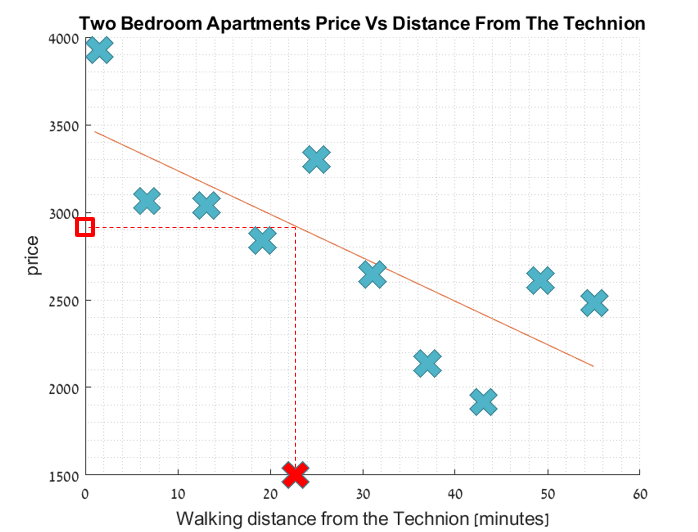
רגרסיה - דוגמא
בהינתן סט של דירות בקרבת הטכניון בעל מאפיין של מרחק הליכה ומחיר הדירה, נרצה ללמוד פונקציה המקיימת את הקשר בין מרחק הליכה למחיר הדירה.
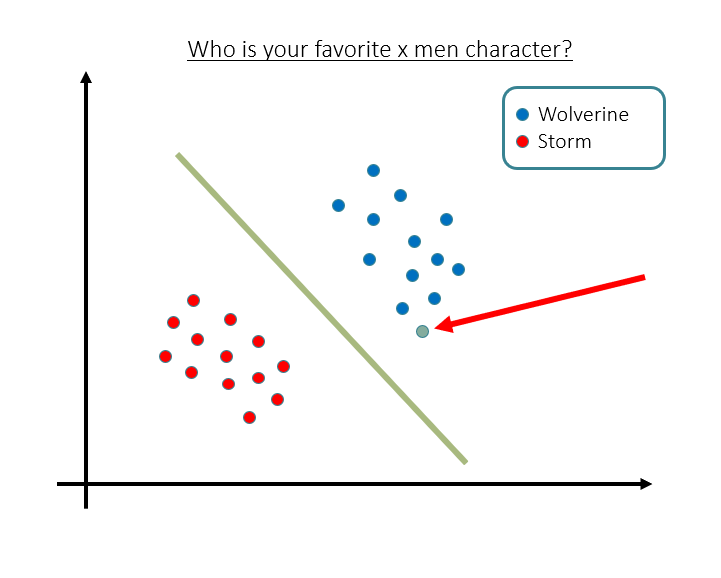
סיווג - דוגמא
חיזוי של שייכות דוגמא חדשה לאחת המחלקות של דמויות קומיקס מועדפות.
בחירת סדר המודל
- למשל עבור מיפויים לינאריים בחירת הגודל .
- סדר המודל (למשל, מספר הפרמטרים במודל פרמטרי) קובע, כעיקרון, את גודל קבוצת הפונקציות הכלולות במודל. ככל שסדר המודל גדול יותר, כך קבוצה זו עשירה יותר, ומכילה פונקציות מסובכות יותר.
- סוגיה יסודית בבחירת סדר המודל הינה הניגוד הבא:
- מודל פשוט מדי (בעל סדר נמוך) לא יאפשר תיאור מדוייק של הקשר ה”אמיתי” בין הקלט לפלט.
- מודל מסובך מדי (בעל סדר גבוה) הוא בעל מספר גדול של דרגות חופש, ולפיכך עלול לדרוש מספר רב של דוגמאות על מנת לבצע הכללה סבירה.
Bias-Variance Tradeoff
פונקציית הסיכון (risk):
פונקציית הסיכון האימפירית (empirical risk):
כאשר - פונקציית מחיר כלשהי, למשל:
פירוק השגיאה:
כאשר
משפחת היפותיזות, מודל -F
- היא שגיאת הקירוב (approximation error) הנקראת גם ההטיה (bias). היא מציינת את הסיכון המינימאלי שחזאי כלשהו מתוך המודל יכול להשיג. גודל זה הינו דטרמיניסטי ואינו תלוי בסדרת הלימוד.
- היא שגיאת השיערוך (estimation error). גודל זה הינו הפרש הסיכון עבור החזאי האופטימאלי מתוך המודל - דהינו לבין החזאי הנבחר על ידי אלגוריתם הלימוד, דהיינו .
מקורות שגיאה
- Bias גבוה - מודל פשוט מדי (בעל סדר נמוך) לא יאפשר תיאור מדויק של הקשר ה”אמיתי” בין הקלט לפלט. (שגיאת גדולה).
- Variance גבוה - מודל מסובך מידי (בעל סדר גבוה) הוא בעל מספר גדול של דרגות חופש, ולפיכך עלול לדרוש מספר רב של דוגמאות על מנת לבצע הכללה סבירה. (שגיאת גבוהה).
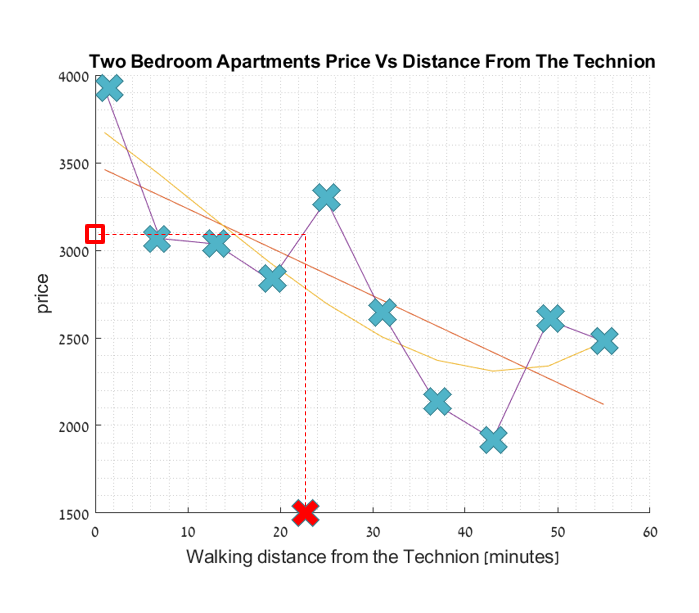
התאמת יתר - דוגמא
ניתן לראות שככל שהמודל בעל שונות יותר גדולה (הסדר של המודל גדל) נכנסים למצב של התאמת יתר, כך שהמודל לומד באופן מדויק את הדוגמאות מתוך סט הספציפי ויכולת ההכללה נפגעת.
Bias vs. Variance אילוסטרציה
הפגיעה במרכז המטרה מציג ה- Bias (שגיאת הקירוב), הפיזור מציג את ה- Variance (שגיאת השערוך).
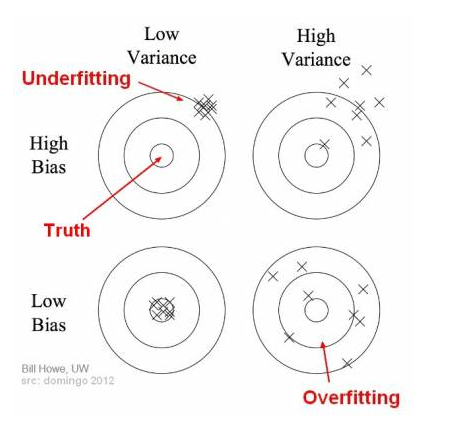
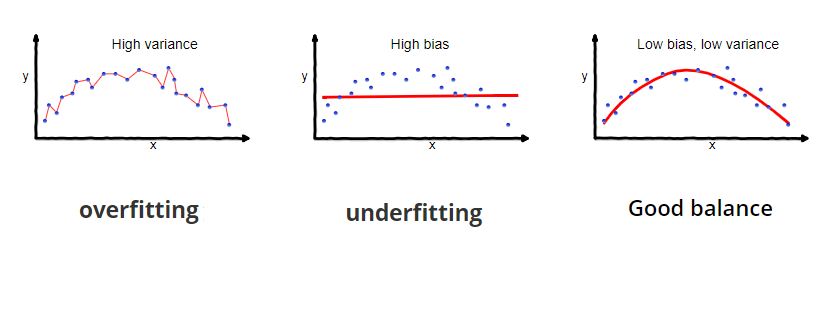
הערה: התמונות נלקחו מהאתר: https://towardsdatascience.com/understanding-the-bias-variance-tradeoff-165e6942b229.
תהליך הלימוד (ולידציה)
נחלק את ה-Data שיש לנו לשלוש קבוצות:
- סט אימון (training set) - סט דוגמאות מתוייג שבאמצעותו האלגוריתם לומד.
- סט אימות (validation set) - סט דוגמאות מתוייג שבאמצעותו נעריך את טיבם של המודלים על מנת לבחור בניהם.
- סט בוחן (test set) - סט דוגמאות מתוייג שבאמצעותו נעריך את ביצועי המודל הסופי שבחרנו.
הערה: השימוש בסט זה הינו השלב האחרון בתהליך הלמידה, ואין להשתמש בו כדי להעריך את ביצועי המודל במהלך הלימוד.
דוגמא לאימות בבעיית רגרסיה
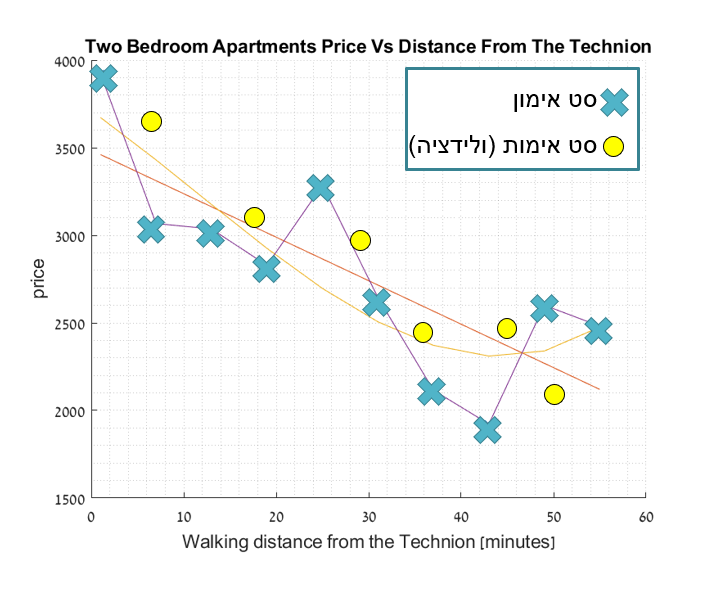
K-fold Cross Validataion
במקרים בהם הData הניתן לנו הוא מוגבל, לא נרצה לבזבז Data על ידי הקצאתו לvalidataion set. שיטה זו מאפשרת לקבל הערכת לשגיאת השיערוך.
input: , integer , learning algorithm A, model M
- Create data partitions: ,
- For
- Fit model M by algorithm A with data
- Calcualte
- Return
דוגמא

סיווג בעזרת אלגוריתם K-NN (K-Nearest Neighbours)
- מצא את השכנים הקרובים ביותר לנקודה החדשה.
- מצא לאיזו קבוצה שייכים רוב השכנים. הנקודה החדשה שייכת לקבוצה זו.
- במקרה של שיוויון בשלב 2, השווה סכום מרחקים. הנקודה החדשה שייכת לקבוצה בעלת הסכום המינימאלי.
- במקרה של שיווון גם בין סכום המרחקים, בחר אקראית.
תרגילים
✍️ תרגיל 5.1
סטודנט נבון ניגש לבחור אבטיחים בסופרמרקט. ידוע כי זוהי רק תחילתה של עונת האבטיחים וקיים מספר לא מבוטל של אבטיחי בוסר הסטודנט שם לב כי ניתן לאפיין את האבטיחים ע”פ ההד בהקשה וע”פ קוטר האבטיח. הסטודנט החליט למפות את ניסיון העבר שלו:
- הד חזק (עוצמה 1), רדיוס 8 ס”מ – מתוק
- הד בינוני (עוצמה 2), רדיוס 10 ס”מ – חמוץ
- הד בינוני (עוצמה 2), רדיוס 5 ס”מ – מתוק
- הד חלש (עוצמה 3), רדיוס 7 ס”מ – מתוק
- הד רפה (עוצמה 4), רדיוס 6 ס”מ – חמוץ
- הד רפה (עוצמה 4), רדיוס 11 ס”מ – חמוץ
- הד עמום (עוצמה 5), רדיוס 8 ס”מ – מתוק
הסטודנט מחזיק בידו האבטיח בעל הד חלש רדיוס 8 ס”מ. האם סביר שהאבטיח מתוק או חמוץ?
א) בדקו את תוצאות ה-classification עבור k-nearest neighbors, כאשר K=1,3. ב) בצע Cross Validation להערכת טיב המודל, עבור K=1,3 ו-7 קבוצות (Leave-one-out Cross Validation). באיזה מסווג נבחר? ג) מה יקרה אם נבחר את k להיות בגודל ה-dataset. ד) סטודנטית נבונה (אף יותר!) העירה לסטודנט כי קוטר האבטיח אינו משנה, וכי עליו להתייחס אך ורק להד. חזרו על התהליך במקרה זה.
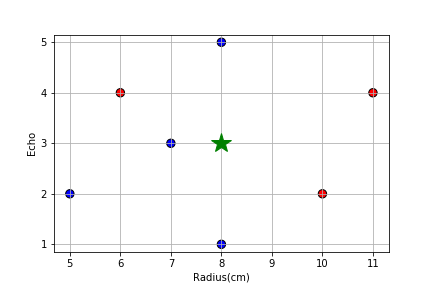
💡 פיתרון
א) נמפה את הנתונים על גרף, כאשר ציר הינו הד האבטיח מ-1 (חזק) ל-5 (עמום). כל נקודה ניתן לרשום כ כאשר, הנקודה הנבדקת היא . בבדיקה ישירה במרחק אוקלידי: השכן הקרוב ביותר הוא ולכן נעניק לנקודה הנבדקת
שלושת השכנים בקרובים ביותר הם וע”פ הצבעת רוב
ב) כאמור הData שלנו הינו:
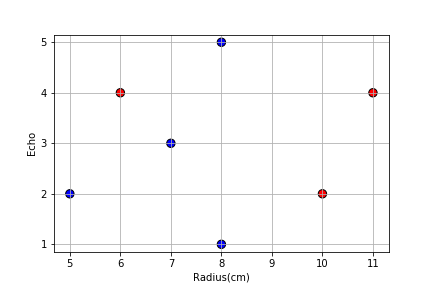
נזכור שבמצב שהנרחקים שווים, נבחר צבע באקראי. במקרה זה נניח שתמיד שובר השוויון הינו כחול, שכן יש לנו יותר נקודות כחולות. נבדוק כל אחת מהנקודות:
| point | label | K=1 | K=3 |
|---|---|---|---|
| blue | ✓ blue(random) | ✓ blue | |
| red | ✗ blue | ✗ blue | |
| blue | ✗ red | ✓ blue | |
| blue | ✓ blue(random) | ✓ blue | |
| blue | ✓ blue(random) | ✗ red | |
| red | ✗ blue | ✗ blue | |
| red | ✓ red | ✗ blue | |
| # of errors | 3 | 4 |
נחשב את שגיאת ה-CV:
עבור K=1, מספר השגיאות הוא 3, ולכן שגיאת ה-CV הינה: עבור K=3, מספר השגיאות הוא 4, ולכן שגיאת ה-CV הינה:
קיבלנו שעבור שגיאת המסווג קטנה יותר מאשר , לכן - במקרה זה נבחר במסווג בעל . משים לב כי במקרה זה תוצאות שני המסווגים גרועות ביותר.
ג) במצב כזה ההחלטה שלנו תקבע ישירות לפי באיזה מהמחלקות יש יותר דוגמאות (במקרה זה, לכל דוגמא חדשה יתקבל הצבע הכחול – כל האבטיחים מתוקים!).
דוגמא נוספת
בשאלה זו ננסה לחזות את בחירתו של אזרח אמריקאי באמצעות אלגוריתם K-NN. לשם הפשטות, נניח כי כל אזרח מיוצג על ידי שני מאפיינים:
מצבו הכלכלי (הציר האופקי - x) וקרבתו לדת (הציר האנכי – y).
בסימונים שלמדנו:
להלן ה- Dataset (מיוצג ע”י נקודות) ומשטחי ההחלטה שנובעים מאלגוריתם 1-nn:
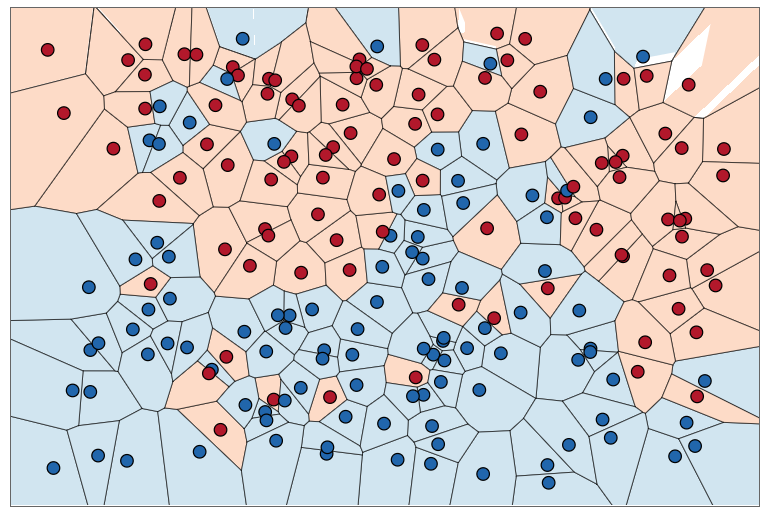
כעת, נבצע פרדיקציה לסט בחן לדוגמא:
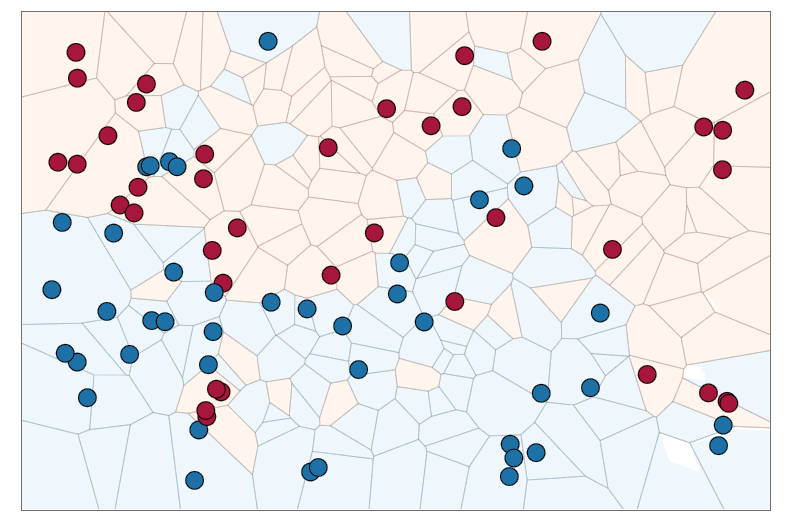
שאלה: איזה משפחה יותר עשירה? תוצאת סיווג עבור 1-nn או עבור 50-nn?
נראה זאת ויזואלית:
נסתכל על סט אימון גדול מאוד ונניח שהוא מתפזר בצורה אחידה על מרחב המאפיינים.
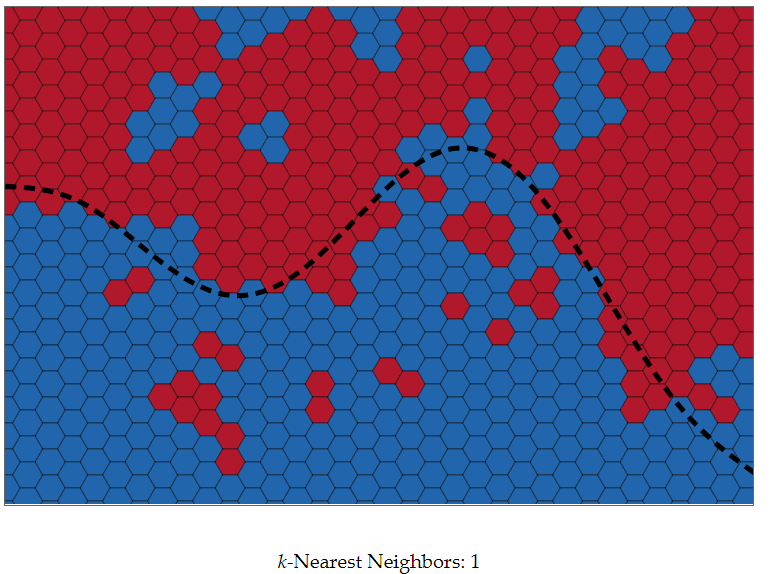
הקו השחור מייצג את קו ההחלטה שלפיו יוצרו הדוגמאות, לפני הוספה של רעש תיוג אקראי.
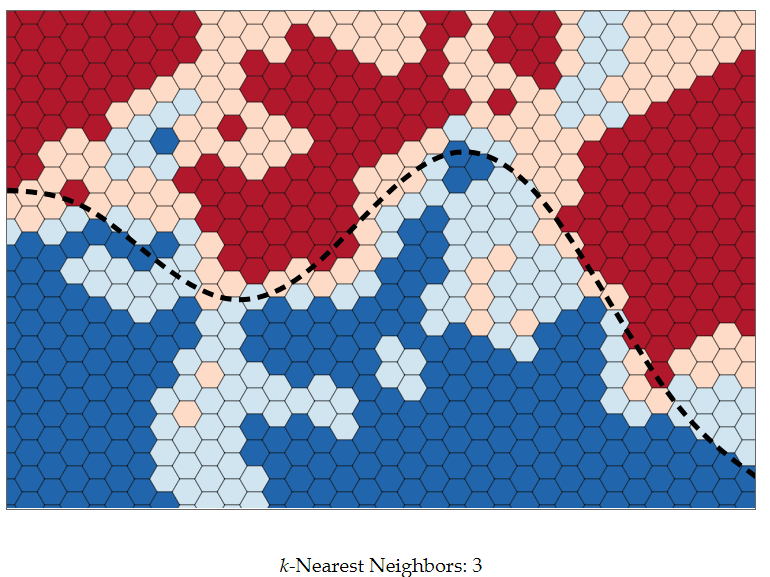
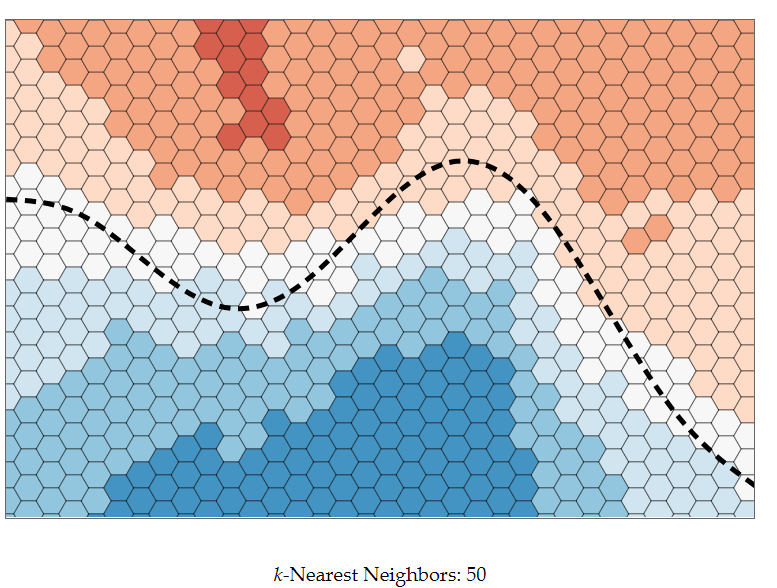
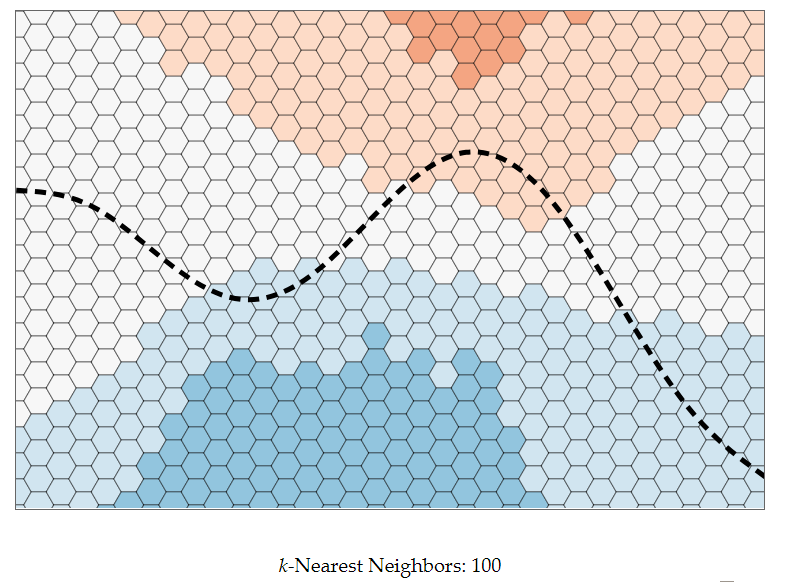
ניתן לראות שככל שנגדיל את מספר השכנים עליהם נסתכל בעת הסיווג משטחי ההחלטה יהפכו ליותר ויותר חלקים, כלומר המודלים יהיו פשוטים יותר. במצב זה, אנחנו מאבדים עם הגדלת k אזורים מיוחדים וקטנים. יש לכך יתרון במידה ואזורים אלו נובעים מרעש, אך ייתכן Data שאינו פריד לינארית וקיימים בו “מובלעות” החלטה.
עם זאת, מידת הביטחון שלנו בפרדיקציות אשר קרובות לאזור ההחלטה ירדו, מאחר שיהיו שכנים רבים באופן יחסי מהמחלקה השנייה.
מה יקרה אם k=n?
כל נקודה חדשה תסווג למחלקה השכיחה יותר בסט האימון. אם שני הסטים זהים בגודלם, כל נקודה תסווג באופן אקראי לחלוטין.
הערה: התמונות נלקחו מאתר http://scott.fortmann-roe.com/docs/BiasVariance.html, מומלץ לקרוא את ההסבר המלא.
בעיה מעשית
תיאור המדגם: Breast Cancer Wisconsin
שיטה נפוצה כיום לאבחנה של סרטן הינה בשיטת Fine-needle aspiration. בשיטה זו נלקחת דגימה של הרקמה בעזרת מחט ומבוצעת אנליזה בעזרת מיקרוסקופ על מנת לאבחן שני מקרים:
- Malignant - רקמה סרטנית
- or Benign - רקמה בריאה
להלן דוגמא לדגימה שכזו:
*התמונה לקוחה מויקיפדיה
מדגם בשם Breast Cancer Wisconsin Diagnostic נאסף על ידי חוקרים מאוניברסיטת ויסקונסין. הוא כולל 30 ערכים מספריים, כגון שטח התא הממוצא, אשר חושבו בעבור 569 דגימות שונות, בנוסף לתווית של האם הדגימה הינה סרטנית או לא.
מדגם זה משמש לרוב כדוגמא לבעיית סיווג קלסית.
ניתן למצוא את המדגם המקורי פה: Breast Cancer Wisconsin (Diagnostic) Data Set
בקורס נשתמש בגרסא דומה לזו הנמצאת פה
❓️ הבעיה: חיזוי האם תא הינו סרטני או לא
אנו מעוניינים לעזור לצוות הרפואי לבצע אבחון נכון של הדגימות על סמך הנתונים המספריים שמחושבים לכל דגימה.
הערה: בהרבה שימושים רפואיים השאיפה הינה לספק סיוע לצוות הרפואי, לרוב על ידי סיפוק המלצות, ולא להחליף אותו.
השדות במדגם
להלן 10 השורות הראשונות במדגם:
| id | diagnosis | radius_mean | texture_mean | perimeter_mean | area_mean | smoothness_mean | compactness_mean | concavity_mean | concave points_mean | ... | radius_worst | texture_worst | perimeter_worst | area_worst | smoothness_worst | compactness_worst | concavity_worst | concave points_worst | symmetry_worst | fractal_dimension_worst | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 842302 | M | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.30010 | 0.14710 | ... | 25.38 | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 |
| 1 | 842517 | M | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.08690 | 0.07017 | ... | 24.99 | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 |
| 2 | 84300903 | M | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.19740 | 0.12790 | ... | 23.57 | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 |
| 3 | 84348301 | M | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.24140 | 0.10520 | ... | 14.91 | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 |
| 4 | 84358402 | M | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.19800 | 0.10430 | ... | 22.54 | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 |
| 5 | 843786 | M | 12.45 | 15.70 | 82.57 | 477.1 | 0.12780 | 0.17000 | 0.15780 | 0.08089 | ... | 15.47 | 23.75 | 103.40 | 741.6 | 0.1791 | 0.5249 | 0.5355 | 0.1741 | 0.3985 | 0.12440 |
| 6 | 844359 | M | 18.25 | 19.98 | 119.60 | 1040.0 | 0.09463 | 0.10900 | 0.11270 | 0.07400 | ... | 22.88 | 27.66 | 153.20 | 1606.0 | 0.1442 | 0.2576 | 0.3784 | 0.1932 | 0.3063 | 0.08368 |
| 7 | 84458202 | M | 13.71 | 20.83 | 90.20 | 577.9 | 0.11890 | 0.16450 | 0.09366 | 0.05985 | ... | 17.06 | 28.14 | 110.60 | 897.0 | 0.1654 | 0.3682 | 0.2678 | 0.1556 | 0.3196 | 0.11510 |
| 8 | 844981 | M | 13.00 | 21.82 | 87.50 | 519.8 | 0.12730 | 0.19320 | 0.18590 | 0.09353 | ... | 15.49 | 30.73 | 106.20 | 739.3 | 0.1703 | 0.5401 | 0.5390 | 0.2060 | 0.4378 | 0.10720 |
| 9 | 84501001 | M | 12.46 | 24.04 | 83.97 | 475.9 | 0.11860 | 0.23960 | 0.22730 | 0.08543 | ... | 15.09 | 40.68 | 97.65 | 711.4 | 0.1853 | 1.0580 | 1.1050 | 0.2210 | 0.4366 | 0.20750 |
לשם פשטות (וממגבלות ויזואליזציה) אנו נעבוד רק עם שני שדות בנוסף לתווית:
- diagnosis - התווית של הדגימה: M = malignant (סרטני), B = benign (בריא)
- radius_mean - רדיוס התא הממוצא בדגימה
- texture_mean - סטיית התקן הממוצעת של רמת האפור בצבע של כל תא בדגימה.
תיאור מלא של כל השדות ניתן למצוא כאן
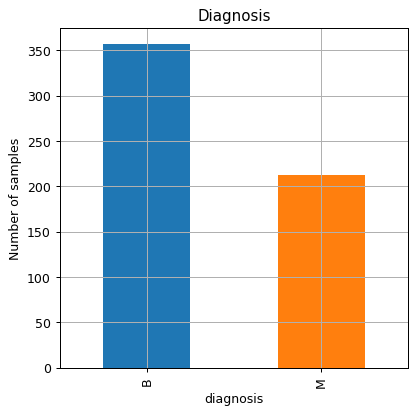
קצת סטטיסטיקות
מספר הדגימות הסרטניות והבריות:
הפילוג של הדגימות כתלות בשני השדות שנעבוד איתם:
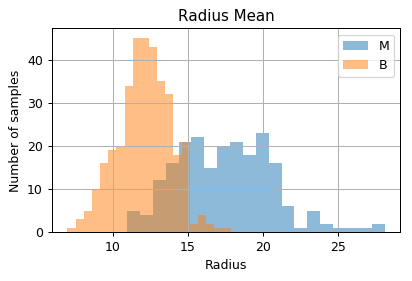
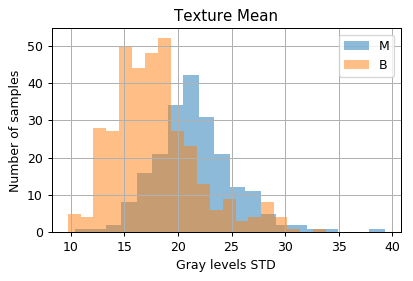
ובדו מימד:
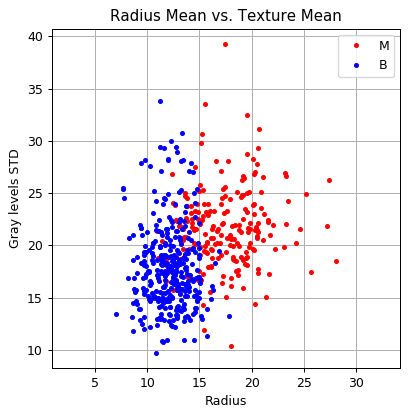
הגדרה פורמאלית של הבעיה
זוהי משימת לימוד מודרך של סיווג בינארי.
אנו נהיה מעניינים למצוא פונקציית חיזוי , הממפה מהמרחב של למרחב התוויות
פונקציית הסיכון שאותה נרצה למזער הינה פונקציית הmissclassification rate:
על מנת לחשב את פונקציית הסיכון עלינו להפריש חלק מהמדגם לשם יצירה של סט בחן. נקדיש 20% מהמדגם לשם כך.
💡 סיווג בעזרת 1-NN
נשתמש באלגוריתם השכן הקרוב על מנת לבצע את החיזוי. נשתמש בפונקציות Voronoi ו voronoi_plot_2d שבחבילה הפייתונית SciPy על מנת לשרטט את מפת החיזוי.
תוצאות
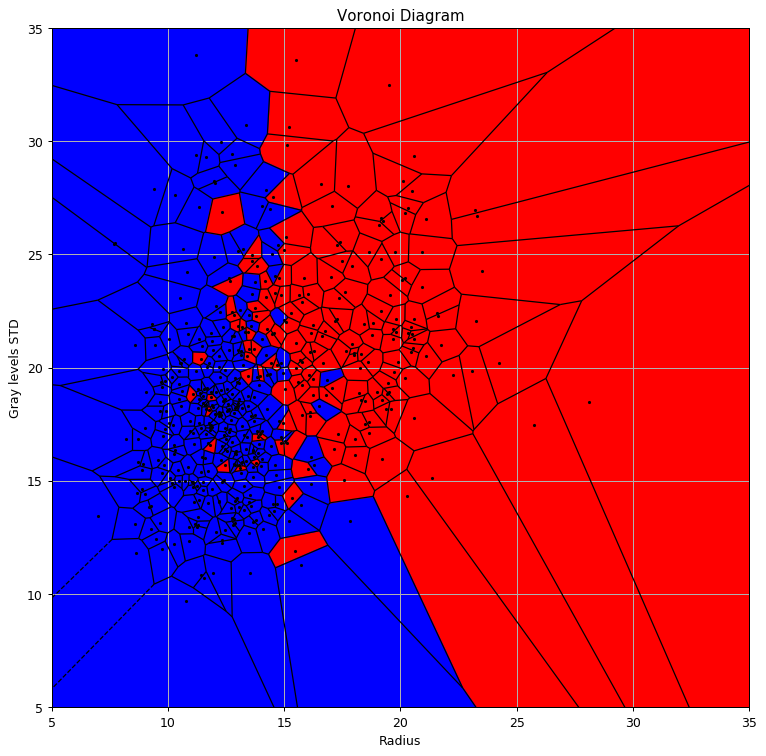
הערכת ביצועים
שיערוך של פונקציית הסיכון בעזרת סט הבחן נותן סיכון של: (סיכוי של 14% לבצע חיזוי שגוי)
💡 סיווג בעזרת K-NN
ננסה לשפר את תוצאות החיזוי שלנו על ידי שימוש בK-NN. נמצא את K בעזרת בדיקת של כל הK-ים בין 1 ל100 והשוואה של הסיכון המשוערך.
נשתמש בפונקציה KNeighborsClassifier בחבילה SciKit-Learn
תוצאות
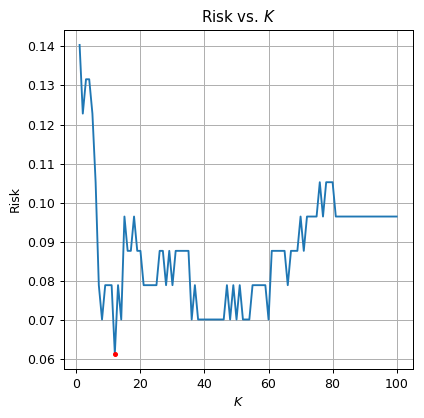
על פי הגרף, הK האופטימאלי הינו אשר נותן סיכון משעורך על סט הבוחן של .
Train-Validation-Test Separation
כפי שציינו קודם לכן, בחירה של על פי סט האימון הינה שגויה מפני שהיא תניב שיערוך אופטימי מידי של הסיכון. בכדי להמנע מכך עלינו הינה להפריש מן המדגם חלק נוסף לשם יצירה של סט אימות.
נחלק את המדגם ל:
- 60% סט אימון.
- 20% סט אימות.
- 20% סט בחן.
נחזור על התהליך אך עם בחירה של על פי סט האימות.
תוצאות
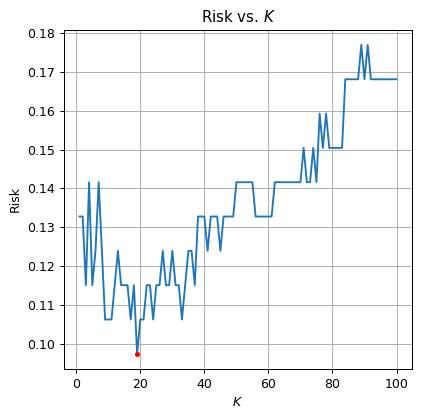
על פי הגרף, הK האופטימאלי הינו אשר נותן סיכון משוערך על סט האימות של .
שיערוך של פונקציית הסיכון בעזרת סט הבחן נותן סיכון של: .
💡 שימוש ב Cross-Validation
כפי שציינו קודם, על מנת שלא לבזבז רבע מסט הלימוד לצורך הבניה של סט האיבחון נוכל להשתמש ב Cross-Validation.

*התמונה לקוחה מ SciKit-Learn
חזור על התהליך עם cross-validataion. נשתמש בפונקצייה cross_val_score של SciKit-Learn.
תוצאות
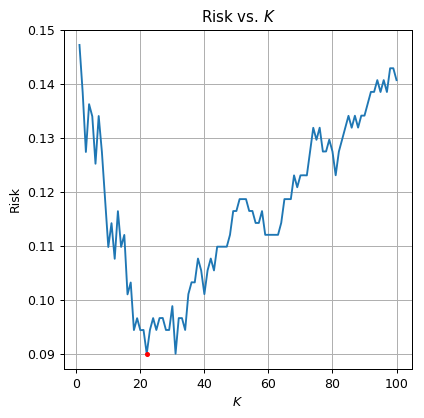
על פי הגרף, הK האופטימאלי הינו אשר נותן סיכון משוערך על סט האימות של .
שיערוך של פונקציית הסיכון בעזרת סט הבחן נותן סיכון של: .