תיאוריה
בתרגול הקודם למדנו איך לתת תחזיות (פרדיקציות) במקרים שאנחנו יודעים את ההתפלגות של המשתנים האקראיים שאנחנו עוסקים בהם. אולם, בעולם האמיתי מתרחשים תהליכים אקראיים רבים שאיננו יודעים באופן אפריורי את פונקציית ההתפלגות שלהן. בתרגול זה נתחיל לענות על השאלה הבאה:
“איך ניתן לשערך את אופן ההתפלגות של משתנים מקריים מתוך דגימות (Samples)?”
סט דגימות כזה מכונה מדגם (Dataset) או בקיצור Data. לאורך הקורס, נשתמש תמיד בהנחה שהדגימים (הנקודות ב- Dataset) בלתי תלויות סטטיסטית ובעלות פילוג זהה (i.i.d.).
סימונים:
- - מספר הדגימות במדגם
- - הדגם ה
- , - משתנים אקראיים
- - המדגם (אשר כולל דגמים בעלי פילוג זהה ובלתי תלויים סטטיסטית, i.i.d)
- - הריאלוזציה שמיוחסת לדגם . ערכים אלו נקראים לרוב .data points.
- - פונקציית ההסתברות (PMF) או הצפיפות ההסתברות (PDF) של משתנה אקראי.
- - פנקציית הפילוג המצרפי של משתנה אקראי.
- - פונקציית אינדיקטור של האם המאורע התרחש, לדוגמא: .
- אנו נשתמש בסימון “כובע” (“hat”) לסמן מנת לציין שערוך של ערך בלתי ידוע. לדוגמא נסמן לשערוך של
המטרה: לשערך את הפילוג של משתנה אקראי מתוך מדגם נתון.
🧮 מדידה אמפירית / משערך הצבה (Empirical Measure)
המדידה האמפירית , , הינה שיערוך של הההסתברות, , להתרחשות המאורע , בהנתן סט של מדידות.
במילים, אנו משערכים כי ההסתברות להתרשות של מאורע שווה למספר הפעמים היחסי שהמאורע התרחש בסט המדידיות.
🎯 תוחלת אמפירית (Empirical mean)
המשערך אמפירי, , הינו המשערך האמפירי של התוחלת , של משתנה אקראי כלשהוא:
באופן דומה, ניתן להגדיר משערך אמפירי לתוחלת של פונקציה כל שהיא של , :
נשתמש בתובנה זו על לבנות משערכים אמפיריים לפונקציות לשערך את ו .
📊 שיערוך פונקציית ההסתתרות (במקרה הדיסקרטי)
נוכל לשערך את פונקציית ההסתברות (PMF) של משתנה אקראי על ידי שימוש במדידה האמפירית:
📈 שיערוך של פונקציית הפילוג המצרפית
ידוע גם בתור ECDF (Empirical Cumulative Distribution Function).
גם כאן נוחכל לשערך את הפילוג המצרפית על ידי שימוש במדידה אמפירית:
הערה: תוצאת השיערוך תהיה תמיד פנוקציה קבועה למקוטעין (אם אי רציפויות), גם במקרים בהם פונקציית הפילוג המצרפי רציפה.
📶 שיערוך פונקציית צפיפות ההסתברות על ידי היסטוגרמה
היסטוגרמה היא שיטה לשערוך פונקציית צפיפות ההסתברות (PDF).
הרעיון הוא כדלקמן:
- לבצע קוונטיזציה (Quantization) לסט דיסקרטי של ערכים על ידי חלוקה לסט תאים נפרדים (Bins) של טווח הערכים שהמשתנה האקראי יכול לקבל
- שערוך אמפירי של ההסתברות להיות בכל תא (Bin).
- שימוש בהתפלגות אחידה להתפלגות הערכים בתוך כל תא.
הערה: בחירת גודל התאים (Bins) משפיעה באופן משמעותי על איכות השערוך של ה PDF.
כלל אצבע: לחלק את טווח הערכים ל- תאים בגודל אחיד.
נסמן ב ו את הגבול השמאלי והימני בהתאמה של התא התא ה. ההסטוגרמה נתונה על ידי:
📉 שיערוך פונקציית צפיפות ההסתברות על ידי Kernel Density Estimation (KDE)
KDE הינה שיטה נוספת לשערוך פונקציית צפיפות ההסתברות. בשיטה זו אנו מייצרים פונקציית צפיפות הסתברות חלקה על ידי שימוש בפונקציית מחליקה המכונה פונקציית גרעין (kernel) או Parzan window
שתי בחירות נפוצות לגרעינים הינם:
- חלון מרובע:
- גאוסיאן:
פונקציית הגרעין תהיה תמיד פונקציית הסתברות תקנית (חיובית שאינטרגל עליה שווה ל1).
בנוסף לבחירה של הגרעין עלינו לגם לקבוע את רוחב הגרעין. הקביעה של רוח הגרעין נעשית עלי די מתיחה של פונקציית הגרעין פי באופן הבא:
בעבור שני הגרעינים לעיל, נקבל:
- לחלון המרובע נקבל:
- במקרה הגאוסי, פרמטר הרוחב הוא בדיוק סטיית התקן של הגאוסיאן ולכן נסמן אותו בסימון המקובל :
ניתן לחשוב על הדרך ניבנית הפונקצייה המשוערכת באופן הבא:
-
מתחילים עם פונקציית צפיפות הסתברות אשר מכילה פונקציות דלתא בגובה כל נקודת דגימה.
-
מחליקים את פונקציית הצפיפות על ידי קונבולוציה עם פונקציית הגרעין.
פונקציית הצפיפות המשוערכת מתקבלת על ידי:
כלל אצבע לבחירת רוחב הגרעין במקרה הגאוסי הינו , כאשר הינה הסטיית תקן של המדידיות.
משערכים כמשתנים אקראיים ופרמטרי טיב
חשוב לציין שכל אחד מן המשערכים שתוארו לעיל הינם למעשה משתנים אקראיים, זאת מכיוון שהם פונקצייה של המדגם שהוא אוסף של משתנים אקראיים. במקרה זה דגם יחיד אשר בעבור מוגדר המשנה האקראי הינו האוסף של כל ה דגמים אשר יוצרים את המדגם.
אנו יכולים לדבר על הפילוג של השיערוך בעבור המקרה בו חוזרים על התהליך כולו של יצירת כל המדגם וחישוב המשערך שוב ושוב.
נסמן לרגע את המשתנה האקראי של תוצאת השיערוך כ (לדוגמא, הECDF בנקודה מסויימת, או ההיסטוגרמה בערך מסויים). בדומה לכל משתנה אקראי אחר, התוחלת של משתנה אקראי זה מוגדרת כ:
הטיה / היסט (Bias)
ההטיה או ההיסט של משערך מוגדרת כ:
(ההפרש בין התוחלת של המשערך לערך האמיתי של האובייקט אותו אנו מנסים לשערך).
כאשר ההטיה שווה ל-0, אנו אומרים שהמשערך אינו מוטה (Unbiased).
✍️ תרגיל 2.1 - הטיות
א) מהי ההטיה של משערך הECDF עבור נקודה כלשהי?
ב) מהי ההטיה של משערך הKDE עבור נקודה כלשהי? פתרו עבור המקרה בו רוחב הגרעין, , קטן, הניחו כי הינה פונקציה סימטרית.
💡 פיתרון
א)
על פי הגדרה, ההטיה של הECDF בנקודה נתון על ידי:
ולכן משערך זה אינו מוטה (חסר הטיה)
ב)
על פי הגדרה, ההיסט של KDE בנקודה נתון על ידי:
נבצע את החלפת המשתנים הבאה לקבלת:
בעבור ערכים קטנים של נוכל לקרב את בעזרת טור טיילור
וכשנציב את הפיתוח לבביטוי להיסט נקבל:
מכיוון ש הינה פונקצייה סימטרית, ופונקציית פילוג חוקית מתקיים כי:
ו
ולכן:
קיבלנו כי משערך הKDE הינו משערך מוטה, וכי בעבור ערכים קטנים של , ההטיה שלו פורפוציונית ל, כמו כן ההטיה פורפוציונית לנגזרת השניה של פונקציית צפיפות ההסתברות בנקודה . תוצאה זו הינה הגניות שכן משערך הKDE מחליק את פונקציית צפיפות ההסתברות ולכן אנו מצפים לקבל שינויים כלשהם ככל שהפונקציית הצפיפות המקורות פחות חלקה. כמו כן ככל ש גדולה יותר ההחלקה חזקה יותר.
השונות (Estimator Variance)
כמו לכל משתנה אקראי, השונות של המשערך מוגדרת כ:
השונות מתארת עד את רמת הפיזור של שיערוכים שונים סביב התוחלת. בעשבור משערך עם שונות קטנה השיעורך יהיה מאד מרוכז סביב התוחלת, ובעבור שונות גבוהה השיערוכים יהיו מפוזרים על איזור מאד רחב. אנו נהיה מעוניינים לרוב במשערך עם שונות קטנה.
✍️ תרגיל 2.2 - שונות (לקריאה עצמית)
מהי השונות של משערך הKDE עבור נקודה כלשהי? פתרו עבור המקרה בו רוחב הגרעין, , קטן, הניחו כי הינה פונקציה סימטרית (לקריאה עצמית)
💡 פיתרון
על פי הגדרה, השונות של KDE בנקודה נתון על ידי:
מכיוון שהדגמים במדגם בתלתי תלויים מתקיים כי בעבור :
ולכן:
נבצע את אותה החלפת המשתנים מקודם: ונפתח לטור עד לסדר ראשון:
קיבלנו כי בעבור ערכים קטנים של , השונות פורפורציונית ל . נזכיר כי בתרגיל הקודם קיבלהו כי ההטיה פורפורציונית ל ולכן לא נוכל להגיע למצב שבו למערך יש גם הטיה קטנה וגם שונות קטנה. תופעה זו הינה תופעה אופיינית והיא מכונה Bias-Vairnace tradoff. אנו עוד נדון רבות בתופעה זו בהמשך הקורס.
נשים לב שמכיוון והשונות תלויה גם במספר הדגמים , ככל שנגדיל את מספר הדגמים נוכל להקטין את רוחב הגרעין ובכך להקטין את ההטיה ולשמור על אותה השונות.
תרגיל מעשי
![]()
🚖 מדגם נסיעות המונית בעיר New York
כחלק מהמאץ של העיר New York להנגיש את המידע אותו אוספת העיר לציבור, היא מפרסמת בכל חודש את רשימת כל נסיעות המונית ופרטיהם אשר בוצעו בעיר באותו חודש. בקורס זה, אנו נעשה שימוש ברשימת הנסיעות מחודש ינואר 2016. ניתן למצוא את הרשימה, פה.
הרשימה המלאה כוללת מעל 10 מליון נסיעות, בכדי להאיץ את זמן החישוב אנו נעשה שימוש רק ברשימה חלקית הכוללת רק 100 אלף נסיעות (אשר נבחרו באקראי אחרי ניקוי מסויים של הרשימה). את הרשימה החלקית ניתן למצוא פה
המגדם ושדותיו
בטבלה מלטה מוצגים עשרת שורות הראשונות ברשימה
| passenger count | trip distance | payment type | fare amount | tip amount | pickup easting | pickup northing | dropoff easting | dropoff northing | duration | day of week | day of month | time of day | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 2.768065 | 2 | 9.5 | 0.00 | 586.996941 | 4512.979705 | 588.155118 | 4515.180889 | 11.516667 | 3 | 13 | 12.801944 |
| 1 | 1 | 3.218680 | 2 | 10.0 | 0.00 | 587.151523 | 4512.923924 | 584.850489 | 4512.632082 | 12.666667 | 6 | 16 | 20.961389 |
| 2 | 1 | 2.574944 | 1 | 7.0 | 2.49 | 587.005357 | 4513.359700 | 585.434188 | 4513.174964 | 5.516667 | 0 | 31 | 20.412778 |
| 3 | 1 | 0.965604 | 1 | 7.5 | 1.65 | 586.648975 | 4511.729212 | 586.671530 | 4512.554065 | 9.883333 | 1 | 25 | 13.031389 |
| 4 | 1 | 2.462290 | 1 | 7.5 | 1.66 | 586.967178 | 4511.894301 | 585.262474 | 4511.755477 | 8.683333 | 2 | 5 | 7.703333 |
| 5 | 5 | 1.561060 | 1 | 7.5 | 2.20 | 585.926415 | 4512.880385 | 585.168973 | 4511.540103 | 9.433333 | 3 | 20 | 20.667222 |
| 6 | 1 | 2.574944 | 1 | 8.0 | 1.00 | 586.731409 | 4515.084445 | 588.710175 | 4514.209184 | 7.950000 | 5 | 8 | 23.841944 |
| 7 | 1 | 0.804670 | 2 | 5.0 | 0.00 | 585.344614 | 4509.712541 | 585.843967 | 4509.545089 | 4.950000 | 5 | 29 | 15.831389 |
| 8 | 1 | 3.653202 | 1 | 10.0 | 1.10 | 585.422062 | 4509.477536 | 583.671081 | 4507.735573 | 11.066667 | 5 | 8 | 2.098333 |
| 9 | 6 | 1.625433 | 1 | 5.5 | 1.36 | 587.875433 | 4514.931073 | 587.701248 | 4513.709691 | 4.216667 | 3 | 13 | 21.783056 |
בתרגול זה אנו נשתמש רק בשני השדות הבאים:
- duration: משך הנסיעה הכולל בדקות.
- time_of_day: שעת תחילת הנסיעה כמספר (לא שלם)
(תיאור מלא של כל השדות בטבלה ניתן למצוא פה)
❓️ בעיה: שיערוך הפילוג של משך הנסיעה
נהג מונית מעוניין לשערך את הפילוג של משך הנסיעות שלו. הוא לקח את הקורס מבוא למערכות לומדות והוא יודע שהוא יוכל לעשות זאת מתוך המידע ההיסטורי אותו אספה עריית New York. בחלק זה של התרגול אנו נעזור לאותו נהג מונית לבצע שיערוך זה.
אופן פורמלי, אנו מועניינים לשערך את הפילוג של משך ניסעות המונית בעיר כפונקציית פילוג מצרפי או כפונקציית צפיפות הסתברות.
💡 שיטה 1: ECDF
-
נסמן את האוסף של ה100 אלף מדידות של משך הנסיעה מהטבלה כ
-
נחשב את משערך הECDF על פני גריד של ערכים המחילים ב0 בקפיצות של 0.001 עד ל
תוצאה:
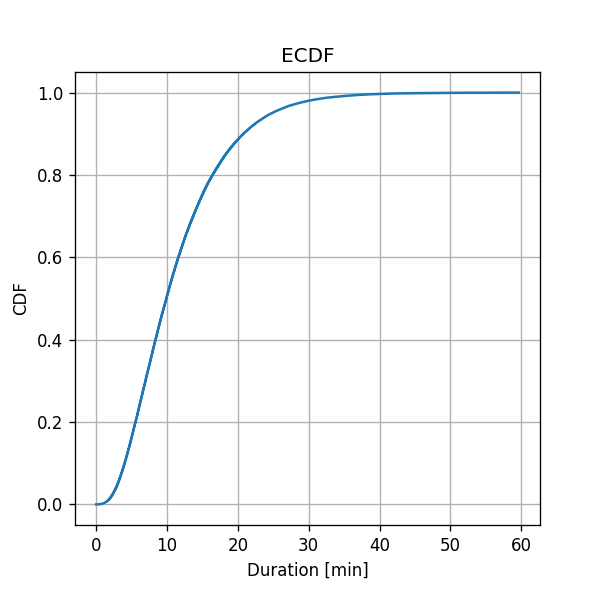
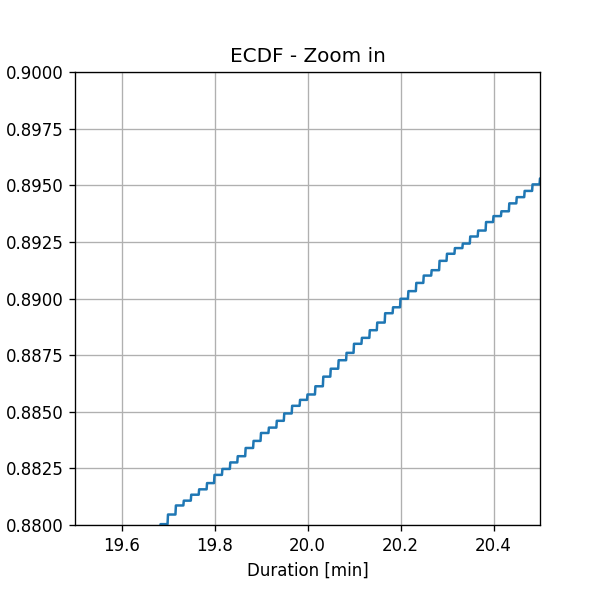
שימו לב כי תוצאת השיערוך היא אוסף של פונקציות מדרגה
✍️ תרגיל 2.3
על פי פונקציית הפילוג המצרפי המושערכת, מהו הסיכוי כש נסיעת מונית תערך יותר מ20 דקות?
💡 פיתרון
על פי הגדרהת הפילוג המצרפי:
התלות בגודל המדגם
על מנת לראות את התלות בגודל המדגם נחזור על החישוב עם כמויות קטנות יותר של דגמים במדגם. אנו נבחר בארקאי גדמים מהמדגם ונחזור על החישוב. התוצאה:
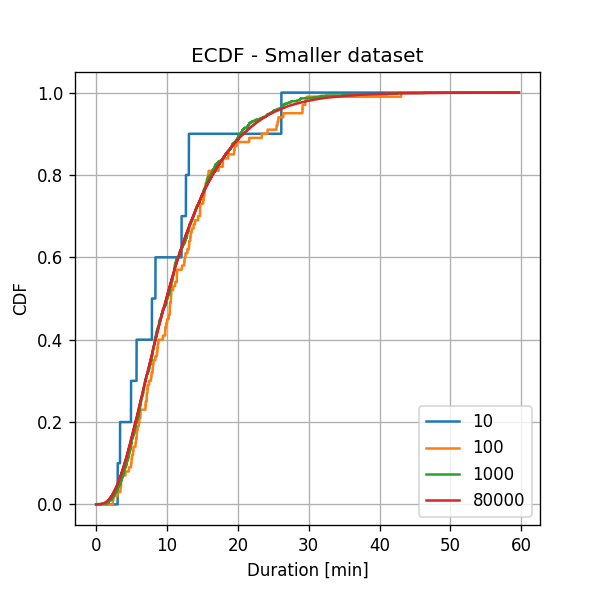
באופן לא מפתיע ניתן לראות כי ככל שאנו מגדילים את מספר הדגמים במדרגם המשערך מתקרב ליותר ויותר לפונצקציה חלקה וניתן גם להראות כי השערוך מתקרב (במובן סטיסטי) לפונקציית הפילוג המצרפי האמיתית.
💡 שיטה 2: היסטוגרמה
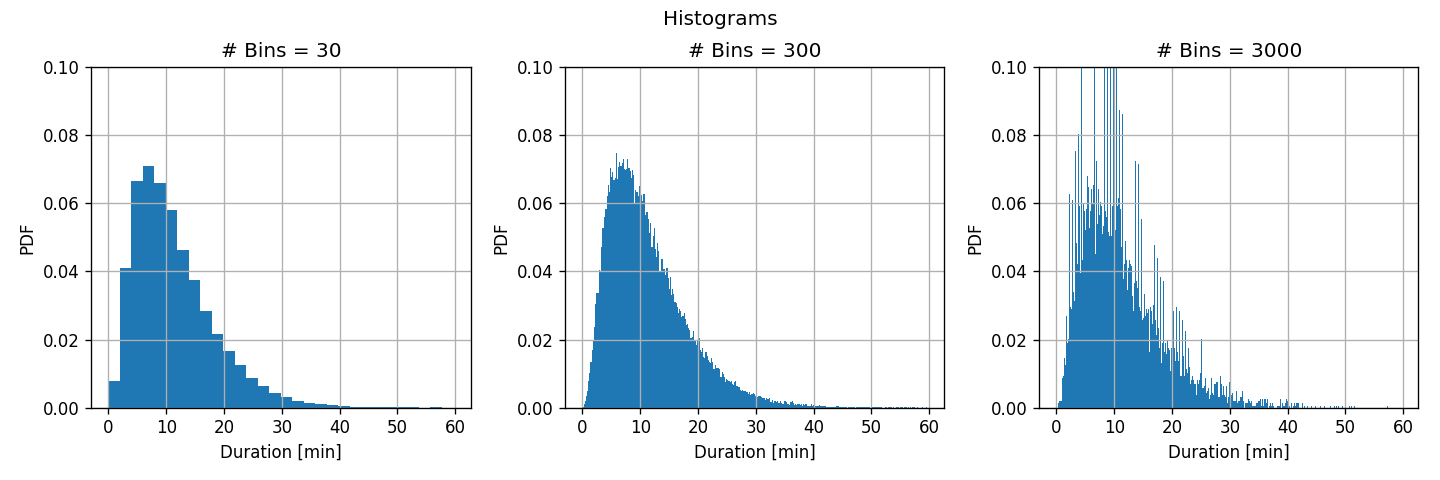
נחשב את ההסטוגרמה של משך הנסיעה בעבור חלוקה של התחום ל30, 300ו 3000 תאים.
תזכורת: כלל האצבע לבחירה של מספר התאים הינו .
תוצאה:
לפני שנבחן את התוצאות, נריץ מבחן נוסף. מפצל את המגדם ל8 תתי מדגמים שווים ונחשב את ההיסטוגרמה על על אחד משמונת תתי המדגם. כך נוכל למעשה לקבל תחושה לגבי הפילוג של השיערוך המתקבל מההסטוגרמה. תוצאה:
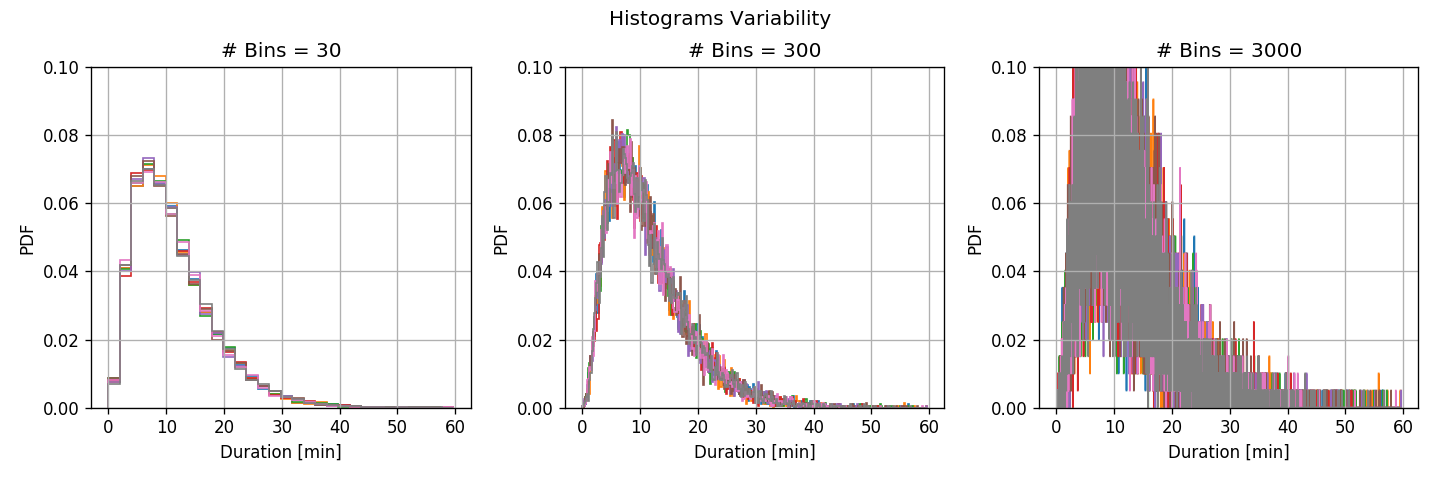
בכדי להגיד את השונות של ההשיערוך בצורה טובה יותר נחסר משמונת השיערוכים את הממוצע שלהם:
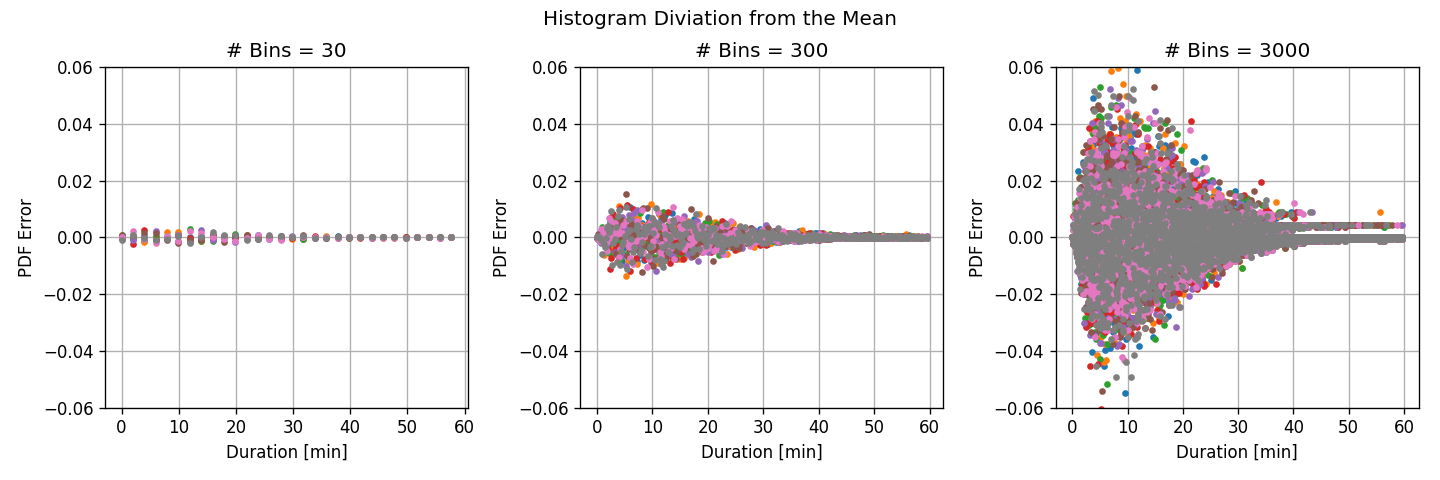
קיבלנו כי:
- בעבור מספר גדול של תאים, ההבדלים בין תתי המדגם השונים (שונות גדולה) גדול והתאים צרים ולכן ההיסטוגרמה יכולה לקרב בצורה יותר טובה את פונקציית הצפיפות האמיתית (הטיה קטנה)
- בעבור מספר קטן של תאים, ההבדלים בין תתי מדגמים שונים קטן (שונות קטנה) אך התאים מאד רחבים ולכן לא יכולים לקרב את הפונקציה האמיתי בצורה טובה (הטיה גדולה)
הסבר אינטאיטיבי למקורות השגיאה
- כאשר נשתמש במספר תאים גדול כל תא יהיה צר ומקור השגיאה העיקרי ינבע מהאקראיות בביצירת המדגם הגורמת לשינויים גדולים במספר היחסי של נקודות אשר נופלות בכל תא. שינויים אלו מתבטאים בשונות גבוהה של המעשרך. שגיאה זו תלך ותקטן ככל שנגדיל את כמות הדגמים במדגם.
- כאשר נשתמש במספר תאים קטן, מקור השגיאה העקרי ינבע מיכולת הייצוג המוגבלת של המודל שלנו. מגבלה זו של המודל תיצור הטיה גדולה.
- בפועל אנו נרצה לרוב לבחור ערך ביניים כלשהו אשר לא סובל משונות גלוה מידי וגם לא מהטיה גדולה מידי. כל ההאבצע יכול לרוב לעזור לבחור ערך שכזה.
💡 שיטה 3: KDE
שערך כעת את פונקציית צפיפות ההסתברות בעזרת KDE עם חלון גאוסי. נבחן ערכים שונים לרוחב החלון .
תזכורת, כלל האצבע מציע לבחור רוחב של:
לשם השוואה, נשרטט את התוצאה של גבי ההסטוגרמה של 300 תאים. תוצאה:
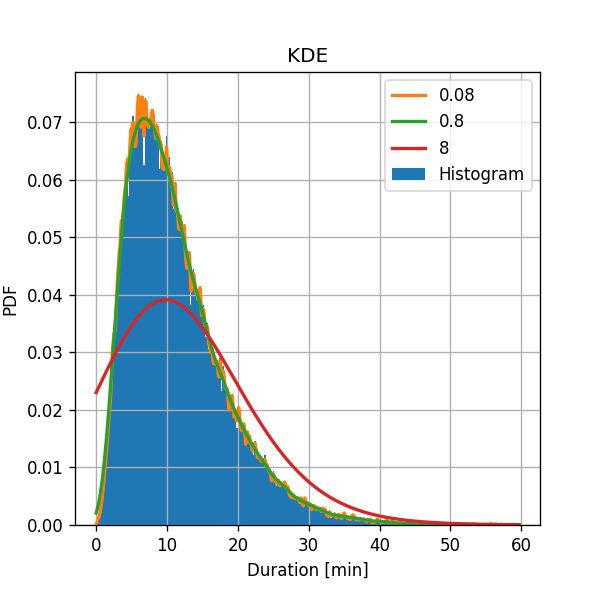
אנו שוב רואים התנהגות דומה לזו של ההסטוגרמה:
- עבור בחירה של רוחב צר המשערך יכולה לקרב פרטים “עדינים” יותר, אבל השיערוך רועש יותר. כפי שראינו בתרגיל 2.2, במקרה זה השונות גדולה יותר וההטיה קטנה יותר.
- עבור בחירה של רוחב רחב המעערך ה”חלקה” את הפרטים הקטנים, אבל השיערוך פחות רועש יותר. כפי שראינו בתרגיל 2.2, במקרה זה השונות קטנה יותר וההטיה גדולה יותר.
❓️ בעיה: האם נסיעה התרחשה בזמן שעות העבודה
נרצה לחזות (predict), על סמך משך הנסיעה, האם נסיעה נתונה התרחשה במהלך שעות העבודה או לא, כאשר יום העבודה מוגדת בין השעות 7:00 ו18:00.
נגדיר את המשתנה האקראי במשתנה ברנולי המתאר האם הנסיעה התרחשה במהלך שעות העבודה או לא. נגדיר כי בעבור נסיעה אשר התרחשה במהלך שעות העבודה ו0 אחרת.
נסמן ב את פונקציית ההסתברות של
נרצה למצוא את חזאי האופטימאלי אשר ימזער את הmissclassification rate (פונקציית הסיכון המתקבל בעבור פונקציית ההפסד אפס-אחד):
💡 פתרון
ראינו בתרגול הקודם כי החזאי האופטימאלי במקרה זה הינו:
על מנת לחשב את נשתמש בכלל בייס:
נשים לב כי:
שלב 1: שיערוך של
נשערך את פונקציית ההסתברות של באופן אמפירי:
נקבל כי:
חיזוי עיוור
אם היה ברצונינו לתת חיזוי עיוור (ללא שום נתונים) להאם נסיעה התרחשה במהלך שעות העבודה הינו מעוניינים לתת את החיזוי הבא:
תוצאה זו טיווראלית שכן ישנו סיכוי מעט יותר גבוה כי נסיעה תתרח מחוץ לשעות העבודה ולכן נעדיף לתת חיזוי שכזה. בעבור חיזוי זה אנו נטעה בממוצע ב49% מהפעמים.
שלב 2: שיערוך
על מנת לשערך את הפילוג המותנה, אנו נשערך באופן בנפרד את ואת . אנו נעשה זאת על ידי חלוקת המדגם לשני תתי מדגמים אחד בעבור ואחד בעבור , ונשתמש בKDE על מנת לשערך את פונקציית צפיפות ההסתברות של כל שני ההסתברות המותנות.
תוצאה:
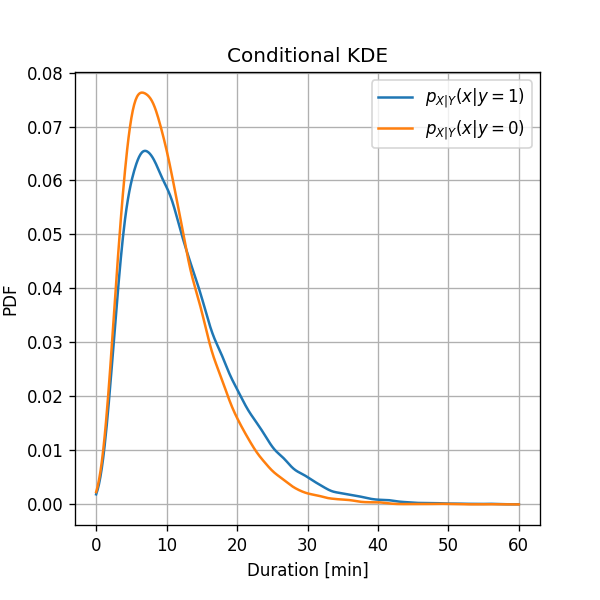
ניתן לראות שבמהלך שעות העבודה ישנה סבירות מעט יותר גבוהה כי משך הנסיעה יהיה ארוך יותר. נראה כעת כיצד עובדה זו תשפר את השיערוך שלנו ל .
שלב 3: חיזוי בהינתן משך הנסיעה
כזכור, החזאי האופטימאלי נתון על ידי: נשרטט פונקציה זו כתלות ב:
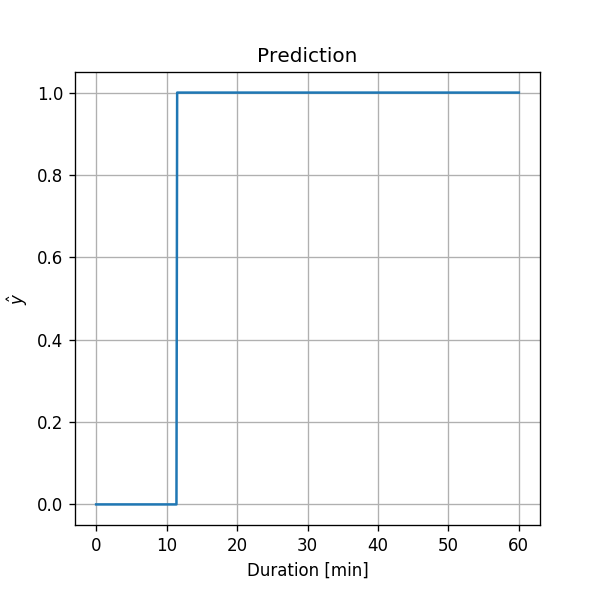
מכאן שהחיזוי שלנו יהיה:
הערכת ביצועים
נוכל לבחון את הביצעים של חזאי זה על סט דוגמאות בילתי תלוי, שיכונה בהמשך סט המבחן (test set). התוצאה של פונקציית הסיכון של סט המחבן הינו . זאת אומרת שהצלחנו לשפר במקצת את החזוי שלנו לעומת החיזוי העיוור. כאשר נסתמך גם על נתונים נוספים כגון: מיקום נסיעה, היום בשבוע וכו’ נוכל לשפראת החזוי שלנו עוד יותר באופן דומה.