🎛️ Parametric Estimation
In contrast to evaluating the distribution of a random variable in a non-parametric way, a much more popular approach is to assume some known form of the distribution, up to some unknown parameters. For example, a commonly used assumption is that a random variable has a normal distribution with some unknown mean value and standard deviation. We will refer to the form of the distribution, which is assumed to be known, as the model, and our task will be to estimate the values of the unknown model’s parameters.
We would usually denote the vector of model parameters as .
There are two main approaches for doing parametric estimation. We will describe them both.
👨 Bayesian Inference
Under this approach, we assume that the unknown model parameters are random variables which have been drawn from some known distribution , called the prior distribution (or the a priori distribution).
| Under the Bayesian approach, our model for the distribution of the data , given the parameters, is described through the conditional probability $$p_{\boldsymbol{X} | \boldsymbol{\tilde{\theta}}}$$ |
Based on the data, we would update our belief of the distribution of the parameters using Bayes’ rule:
(Here is a vector of random variables and is a realization of it)
| The conditional probability $$p_{\boldsymbol{\tilde{\theta}} | \boldsymbol{X}}$$ is called the posterior distribution (or the a posteriori distribution). |
Let us give an interpretation to each of the terms:
-
$$p_{\boldsymbol{X} \boldsymbol{\tilde{\theta}}}\left(\boldsymbol{x} \boldsymbol{\theta}\right)\boldsymbol{\theta}$$ explains the measured data. - - The prior distribution: How probable is it for the random variable to be equal to a specific set of values .
- - The model evidence: How probable is it for the random variable to be equal to the actual measured data . This is based on the complete model, unrelated related to any specific value of . This term is simply the normalization factor which is necessary for making the posterior distribution a valid probability
There are a few methods for selecting the optimal model parameters based upon the posterior distribution. We will describe one of them
Maximum A Posteriori Estimation (MAP)
In MAP estimation we will select the optimal model parameters as the parameters which maximize the posterior distribution:
We will note that the term has no effect on the result of , therefore:
An intuitive interpretation is that we would like to select the optimal which can both explain the measured data (high likelihood) and has a high prior probability.
In practice we would usually solve:
Here, the second equality is due to the monotonically increasing nature of the function and results in an expression which is usually simpler to use.
⏳️ Frequentist Inference
Under this approach, we assume that the unknown model parameters are some constant unknown parameters without any distribution related to them. Under the frequentist approach, our model for the distribution of the data based on the parameters is described as a parametric probability function
| A comment: Since in this case is no longer a random variable, we have used here to emphasize that is a prameter of . In the Bayesian case we have used $$p\left(\cdot | \cdot\right)p\left(\cdot | \cdot\right)$$ for both cases. |
Based on the data , the likelihood function is defined as .
This is merely a change of notation to distinguish the change of roles between and . While the probability function is a function of , and we assume that is known, the likelihood function is a function of , and we assume that is known.
For simplicity we would also define the log-likelihood function:
Here as well, there are a few methods for selecting the optimal model parameters based upon the data, we will describe one of them.
Maximum Likelihood Estimation (MLE)
In MLE we select the optimal model parameters as the parameters which maximizes the likelihood function:
Workshop 3
MLE, MAP & Estimation Errors
🚖 The NYC Taxi Dataset
Let us return to the taxi rides dataset from the last workshop.
❓️ Problem Reminder: Estimating the Distribution of Trip Duration
In the last workshop we have tried to describe the distribution of taxi rides duration using non-parametric methods. In this tutorial we will try to use parametric models to evaluate this distribution.
🔃 Reminder: The Workflow
We will follow the same work flow from the workshop

🛠️ Preparations
We will start by importing some useful packages
# Importing packages
import numpy as np # Numerical package (mainly multi-dimensional arrays and linear algebra)
import pandas as pd # A package for working with data frames
import matplotlib.pyplot as plt # A plotting package
## Setup matplotlib to output figures into the notebook
## - To make the figures interactive (zoomable, tooltip, etc.) use ""%matplotlib notebook" instead
%matplotlib inline
plt.rcParams['figure.figsize'] = (5.0, 5.0) # Set default plot's sizes
plt.rcParams['figure.dpi'] = 90 # Set default plot's dpi (increase fonts' size)
plt.rcParams['axes.grid'] = True # Show grid by default in figures
## A function to add Latex (equations) to output which works also in Google Colabrtroy
## In a regular notebook this could simply be replaced with "display(Markdown(x))"
from IPython.display import HTML
def print_math(x): # Define a function to preview markdown outputs as HTML using mathjax
display(HTML(''.join(['<p><script src=\'https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.3/latest.js?config=TeX-AMS_CHTML\'></script>',x,'</p>'])))
🕵️ Data Inspection (Reminder)
Print out the size and the 10 first rows of the dataset.
data_file = 'https://technion046195.github.io/semester_2019_spring/datasets/nyc_taxi_rides.csv'
## Loading the data
dataset = pd.read_csv(data_file)
## Print the number of rows in the data set
number_of_rows = len(dataset)
print_math('Number of rows in the dataset: $$N={}$$'.format(number_of_rows))
## Show the first 10 rows
dataset.head(10)
Number of rows in the dataset:
| passenger_count | trip_distance | payment_type | fare_amount | tip_amount | pickup_easting | pickup_northing | dropoff_easting | dropoff_northing | duration | day_of_week | day_of_month | time_of_day | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 2.768065 | 2 | 9.5 | 0.00 | 586.996941 | 4512.979705 | 588.155118 | 4515.180889 | 11.516667 | 3 | 13 | 12.801944 |
| 1 | 1 | 3.218680 | 2 | 10.0 | 0.00 | 587.151523 | 4512.923924 | 584.850489 | 4512.632082 | 12.666667 | 6 | 16 | 20.961389 |
| 2 | 1 | 2.574944 | 1 | 7.0 | 2.49 | 587.005357 | 4513.359700 | 585.434188 | 4513.174964 | 5.516667 | 0 | 31 | 20.412778 |
| 3 | 1 | 0.965604 | 1 | 7.5 | 1.65 | 586.648975 | 4511.729212 | 586.671530 | 4512.554065 | 9.883333 | 1 | 25 | 13.031389 |
| 4 | 1 | 2.462290 | 1 | 7.5 | 1.66 | 586.967178 | 4511.894301 | 585.262474 | 4511.755477 | 8.683333 | 2 | 5 | 7.703333 |
| 5 | 5 | 1.561060 | 1 | 7.5 | 2.20 | 585.926415 | 4512.880385 | 585.168973 | 4511.540103 | 9.433333 | 3 | 20 | 20.667222 |
| 6 | 1 | 2.574944 | 1 | 8.0 | 1.00 | 586.731409 | 4515.084445 | 588.710175 | 4514.209184 | 7.950000 | 5 | 8 | 23.841944 |
| 7 | 1 | 0.804670 | 2 | 5.0 | 0.00 | 585.344614 | 4509.712541 | 585.843967 | 4509.545089 | 4.950000 | 5 | 29 | 15.831389 |
| 8 | 1 | 3.653202 | 1 | 10.0 | 1.10 | 585.422062 | 4509.477536 | 583.671081 | 4507.735573 | 11.066667 | 5 | 8 | 2.098333 |
| 9 | 6 | 1.625433 | 1 | 5.5 | 1.36 | 587.875433 | 4514.931073 | 587.701248 | 4513.709691 | 4.216667 | 3 | 13 | 21.783056 |
The Data Fields and Types
In this exercise we will only by interested in the following column:
- duration: The total duration of the ride (in minutes)
Plotting the data
Let us plot again the histogram of the durations
## Prepare the figure
fig, ax = plt.subplots()
ax.hist(dataset['duration'].values, bins=300 ,density=True)
ax.set_title('Historgram of Durations')
ax.set_ylabel('PDF')
ax.set_xlabel('Duration [min]');
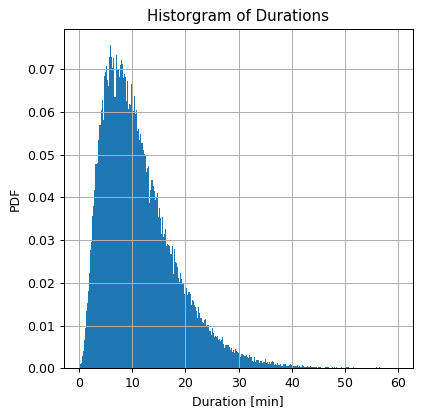
📜 Problem Definition
As same as last time:
- The underlying process: A random phenomenon generating taxi rides along with there details
- The task and goal: To find the distribution of rids duration, represented as a PDF.
📚 Splitting the dataset
We will split the data into 80% train set and 20% test set for later evaluations.
(Although we will not be using the test set in this workshop, it is a good practice to always start by splitting the data)
n_samples = len(dataset)
## Generate a random generator with a fixed seed
rand_gen = np.random.RandomState(0)
## Generating a vector of indices
indices = np.arange(n_samples)
## Shuffle the indices
rand_gen.shuffle(indices)
## Split the indices into 80% train / 20% test
n_samples_train = int(n_samples * 0.8)
train_indices = indices[:n_samples_train]
test_indices = indices[n_samples_train:]
train_set = dataset.iloc[train_indices]
test_set = dataset.iloc[test_indices]
💡 Model & Learning Method Suggestion 1 : Normal Distribution + MLE
In this case we will suggest a normal distribution as our model. A general normal distribution is define by 2 parameters, it’s mean value and it’s standard deviation .
In addition, in this step we would want to decide on a method for selecting the model’s parameters, in this case we will take the MLE (Maximum Likelihood Estimation) approach. This special case of MLE and a normal distribution can be solve analytically. Sadly, this is will not be true in the general case, and we will have to resort to numerical solutions.
⚙️ Learning
✍️ Exercise 3.1 - MLE + Normal Distribution
- Use the MLE approach to estimate the PDF of rides duration as a normal distribution.
- Plot the estimated PDF on top of an histogram of the rides duration.
- By looking at the two plots, do you thinks that the Gaussian distribution is a good approximation for the data distribution?
Solution 3.1-1
(Solution seen in the lecture, appears here only for completeness)
Se shall denote:
- - The PDF of a normal distribution with mean and standard deviation .
- - the vector .
- - The number of samples points in the train set.
The Normal distribution is defined by:
Given a set of independent sample , the likelihood function is given as:
The log-likelihood function for the normal distribution model is then:
Under the MLE approach, the optimal parameters for the model are given by
We shall find by comparing the derivative of the log-likelihood function to zero.
The actual calculation:
## extarcting the samples
x = train_set['duration'].values
## Normal distribution parameters
mu = np.sum(x) / len(x)
sigma = np.sqrt(np.sum((x - mu) ** 2) / len(x))
print_math('$$\\mu = {:.01f}\\ \\text{{min}}$$'.format(mu))
print_math('$$\\sigma = {:.01f}\\ \\text{{min}}$$'.format(sigma))
From here on we will use np.mean and np.std functions to calculate the mean and standard deviation.
In addition scipy.stats has a wide range of distribution models. Each model comes with a set of methods for calculating the CDF, PDF, performing MLE fit, generate samples and more.
Solution 3.1-2
We shall plot the estimated PDF on top of the histogram.
## Define the grid
grid = np.arange(-10, 60 + 0.1, 0.1)
## Import the normal distribution model from SciPy
from scipy.stats import norm
## Define the normal distribution object
norm_dist = norm(mu, sigma)
## Calculate the normal distribution PDF over the grid
norm_pdf = norm_dist.pdf(grid)
## Prepare the figure
fig, ax = plt.subplots()
ax.hist(dataset['duration'].values, bins=300 ,density=True, label='Histogram')
ax.plot(grid, norm_pdf, label='Normal')
ax.set_title('Distribution of Durations')
ax.set_ylabel('PDF')
ax.set_xlabel('Duration [min]')
ax.legend();
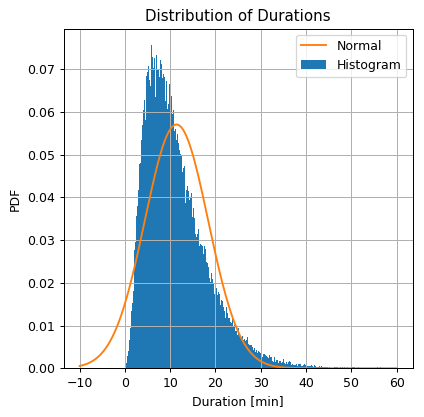
Solution 3.1-3
Since we did not define any actual evaluation method, we will estimate how good is the density estimation in a qualitative manner rather then a quantitative one. We will do so by looking at how similar it is to the histogram.
It seems that the normal distribution gives a very rough approximation of the real distribution. In some cases this would be good enough as a first order approximation, but in this case we would like to do better.
One very disturbing fact, for example, is the that there is a non zero probability to get negative ride durations, which is obviously not realistic.
Let us try to propose a better model in order to get a better approximation.
💡 Model & Learning Method Suggestion 2 : Rayleigh Distribution + MLE
The Rayleigh distribution describes the distribution of the magnitude of a 2D Gaussian vector with zero mean and no correlation between it’s two components. I.e. if has the following distribution:
Than has a Rayleigh distribution.
The PDF of the Rayleigh distribution is given by:
Notice that here the distribution is only defined for positive values. The Rayleigh distribution has only one parameter which is called the scale parameter. Unlike in case of the normal distribution, here is not equal to the standard deviation.
For consistency we will denote the 1D vector of parameters:
We will now give a short motivation for preferring the Rayleigh distribution. This section can be skipped, and the Rayleigh distribution can be assumed to be simply selected as a good guess.
Motivation For Using Rayleigh Distribution
We have started with an assumption that the duration a taxi ride is normally distributed. Let us instead assume that the quantity which is normally distributed is the 2D distance , between the pickup location to the drop off location.
I.e., we are assuming that the random variable is a 2D Gaussian vector. For simplicity, we will also assume that the and components of are uncorrelated with equal variance and zero mean. I.e. we assume that:
In addition, let us also assume that the taxis speed, is constant. Therefore the relation between the ride duration and the distance vector is:
In this case will have a Rayleigh distribution with a scale parameter
⚙️ Learning
✍️ Exercise 3.2 - MLE + Rayleigh Distribution
Repeat the process using the Rayleigh distribution
Solution 3.2
The log likelihood function in this case given by:
| Under the MLE approach,optimal parameters, are defined by $$\boldsymbol{\theta}^*=\underset{\boldsymbol{\theta}}{\arg\min}\ -l_\text{rayleigh}\left(\boldsymbol{\theta} | {x}\right)$$. |
Like before, we will solve this by differentiating and comparing to zero:
The actual calculation and plot:
## Import the normal distribution model from SciPy
from scipy.stats import rayleigh
## Find the model's parameters using SciPy
_, sigma = rayleigh.fit(x, floc=0) ## equivalent to running: sigma = np.sqrt(np.sum(x ** 2) / len(x) / 2)
print_math('$$\\sigma = {:.01f}$$'.format(sigma))
## Define the Rayleigh distribution object
rayleigh_dist = rayleigh(0, sigma)
## Calculate the Rayleigh distribution PDF over the grid
rayleigh_pdf = rayleigh_dist.pdf(grid)
## Prepare the figure
fig, ax = plt.subplots()
ax.hist(dataset['duration'].values, bins=300 ,density=True, label='Histogram')
ax.plot(grid, norm_pdf, label='Normal')
ax.plot(grid, rayleigh_pdf, label='Rayleigh')
ax.set_title('Distribution of Durations')
ax.set_ylabel('PDF')
ax.set_xlabel('Duration [min]')
ax.legend();
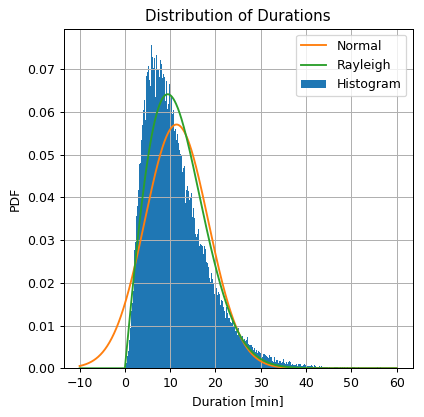
Judging by the similarity to the histogram, the Rayleigh distribution does a slightly better job at approximating the distribution and solves the negative values problem.
Let us try one more model.
💡 Model & Learning Method Suggestion 3 : Generalized Gamma Distribution + MLE
The Rayleigh distribution is a special case of a more general family of distributions called the Generalized Gamma distribution. The PDF of the Generalized Gamma distribution is given by the following complex expression:
( here is the gamma function)
For and we get the Rayleigh distribution.
Unlike the case of the normal and Rayleigh distributions, here we will not be able to find a simple analytic solution for the optimal MLE parameters. However we can use numerical methods for finding the optimal parameters. In practice we will use SciPy’s model for the General Gamma distribution to find the optimal parameters.
⚙️ Learning
Exercise 3.3 - MLE + Generalized Gamma Distribution
Repeat the process using the Generalized Gamma distribution. Use SciPy to calculated the MLE parameters.
Solution 3.3
## Import the normal distribution model from SciPy
from scipy.stats import gengamma
## Find the model's parameters using SciPy
a, c, _, sigma = gengamma.fit(x, floc=0)
print_math('$$a = {:.01f}$$'.format(a))
print_math('$$c = {:.01f}$$'.format(c))
print_math('$$\\sigma = {:.01f}$$'.format(sigma))
## Define the generalized gamma distribution object
gengamma_dist = gengamma(a, c, 0, sigma)
## Calculate the generalized gamma distribution PDF over the grid
gengamma_pdf = gengamma_dist.pdf(grid)
## Prepare the figure
fig, ax = plt.subplots()
ax.hist(dataset['duration'].values, bins=300 ,density=True, label='Histogram')
ax.plot(grid, norm_pdf, label='Normal')
ax.plot(grid, rayleigh_pdf, label='Rayleigh')
ax.plot(grid, gengamma_pdf, label='Generalized Gamma')
ax.set_title('Distribution of Durations')
ax.set_ylabel('PDF')
ax.set_xlabel('Duration [min]')
ax.legend();
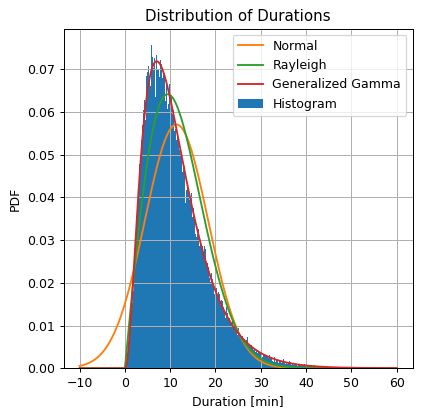
The Generalized Gamma distribution results in a distribution with a PDF which is much similar to the shape of the histogram.
🧸 Toy Model
In this exercise we will take a look at a very simple toy example. Consider the following process:
- A random number is generated once following the normal distribution:
- A series of random numbers is then generated independently following the normal distribution:
We would look at a few cases of estimating the distribution of .
✍️ Exercise 3.4 - MAP and a Toy Model
-
Start by using the exact model which generates the data, i.e. a normal distribution with a known standard deviation of and mean value which is normally distributed with mean value 0 and a standard deviation of . Use the MAP approach to estimate the distribution of given a dataset .
-
Use and to randomly generate the dataset with a size of 10 samples. Using the MAP estimation, calculate the actual parameters and the estimation error between the true and the estimated mean value of .
-
Compare it to an estimation based on MLE.
-
MAP works great when we have a good prior distribution. Let us see what happens if our prior is not that good. Repeat the process, but this time use for calculating the MAP estimation (instead of the real value of )
Solution 3.4-1
Here we assume that the entire model is known including and . However following the MAP approach we would like to find the specific parameters of of the distribution of the data which are most probable given the prior distribution and the data. In this case, of a normal distribution with a known standard deviation, the only parameter of the model is the distribution’s mean value , therefore we will define the vector of parameters .
Under this approach we are looking for the model’s optimal parameters according to:
We will find by differentiating and compare to zero:
Solution 3.4-2
We shall generate the data and calculate the value of and the estimation error
n_samples = 10
sigma_x = 3
sigma_a = 1
## Generate a random generator with a fixed seed
rand_gen = np.random.RandomState(0)
## Draw a random value for a
a = rand_gen.randn() * sigma_a
## Draw N random samples for {x_i}
x = rand_gen.randn(n_samples) * sigma_x + a
## Calaulte the MAP estimation for the mean value
mu_hat_map = sigma_a ** 2 / (sigma_x ** 2 / n_samples + sigma_a ** 2) * np.mean(x)
## Calaulte the estimation error
estimation_error_map = np.abs(mu_hat_map-a)
print_math('The true mean value of $$X$$ is: $$\\mu=a = {:.03f}$$'.format(a))
print_math('By using MAP we get:')
print_math('- $$\\hat{{\\mu}}_\\text{{MAP}} = {:.03f}$$'.format(mu_hat_map))
print_math('- Estimation error: $$\\left|\\hat{{\\mu}}_\\text{{MAP}}-\\mu\\right| = {:.03f}$$'.format(estimation_error_map))
The true mean value of is:
By using MAP we get:
-
Estimation error: $$\left \hat{\mu}_\text{MAP}-\mu\right = 0.074$$
Solution 3.4-3
We saw earlier that based on the MLE approach, the optimal mean value of a normal distribution is equal to the average value of the samples:
## Calaulte the MLE estimation for the mean value
mu_hat_mle = x.mean()
## Calaulte the estimation error
estimation_error_mle = np.abs(mu_hat_mle-a)
print_math('By using MLE we get:')
print_math('- $$\\hat{{\\mu}}_\\text{{MLE}} = {:.03f}$$'.format(mu_hat_mle))
print_math('- Estimation error: $$\\left|\\hat{{\\mu}}_\\text{{MLE}}-\\mu\\right| = {:.03f}$$'.format(estimation_error_mle))
By using MLE we get:
-
Estimation error: $$\left \hat{\mu}_\text{MLE}-\mu\right = 1.728$$
Let us plot the two estimations along with the true distribution
## Define the grid
grid = np.arange(-10, 10 + 0.1, 0.1)
## Calculate the normal distribution PDF over the grid
true_pdf = norm.pdf(grid, a, sigma_x)
map_pdf = norm.pdf(grid, mu_hat_map, sigma_x)
mle_pdf = norm.pdf(grid, mu_hat_mle, sigma_x)
## Prepare the figure
fig, ax = plt.subplots()
ax.plot(grid, true_pdf, label='True')
ax.plot(grid, map_pdf, label='MAP')
ax.plot(grid, mle_pdf, label='MLE')
ax.plot(x, np.zeros(x.shape), 'rx', label='Samples')
ax.set_title('Distribution')
ax.set_ylabel('PDF')
ax.set_xlabel('X')
ax.legend();
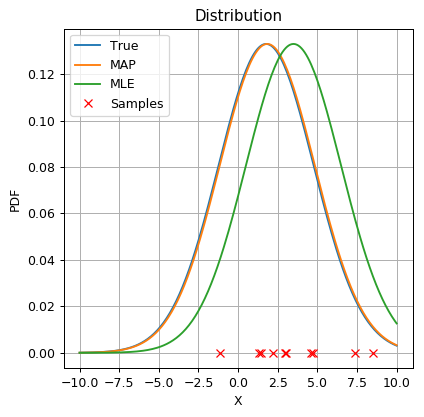
In this example, the samples, drawn according to the true distribution, happened to be more concentrated on the left side of the Gaussian. This causes the MLE to give an estimation for the mean which is slightly higher then it’s real value. By using the MAP approach along with the prior on , which states that is more likely to have a value closer to zero, the estimation of the mean value gets closer to zero and also closer to the real mean value.
Solution 3.4-4
We shall calculate the MAP estimation using
## Define the list of sigma_a_tilde
sigma_a_tilde_list = [0.25, 0.5, 1, 2, 4]
print_math('By using MAP with different values of $$\\tilde{{\\sigma}}_A$$ we get:')
for i, sigma_a_tilde in enumerate(sigma_a_tilde_list):
## Calaulte the MLE estimation for the mean value
mu_hat_map_tilde = sigma_a_tilde ** 2 / (sigma_x ** 2 / n_samples + sigma_a_tilde ** 2) * np.mean(x)
## Calaulte the estimation error
estimation_error_map_tilde = np.abs(mu_hat_map_tilde-a)
print_math('- $$\\tilde{{\\sigma}}_A={:.2f}\\quad\\Rightarrow\\hat{{\\mu}} = {:.3f},\\quad\\left|\\hat{{\\mu}}-\\mu\\right| = {:.3f}$$'.format(sigma_a_tilde, mu_hat_map_tilde, estimation_error_map_tilde))
By using MAP with different values of we get:
To get a bit more intuition, let us plotting as a function of
sigma_a_grid = np.logspace(-2, 2, 1000)
mu_hat_map_grid = sigma_a_grid ** 2 / (sigma_x ** 2 / n_samples + sigma_a_grid ** 2) * np.mean(x)
fig, ax = plt.subplots()
ax.set_xscale('log')
ax.plot(sigma_a_grid, mu_hat_map_grid, label='MAP')
ax.plot([sigma_a_grid[0], sigma_a_grid[-1]], [mu_hat_mle, mu_hat_mle], '--', label='MLE')
ax.plot([sigma_a_grid[0], sigma_a_grid[-1]], [a, a], '--', label='True')
ax.set_title('Mean Value Estimation')
ax.set_ylabel('Mean Value')
ax.set_xlabel('$$\\tilde{{\\sigma}}_A$$')
ax.legend();
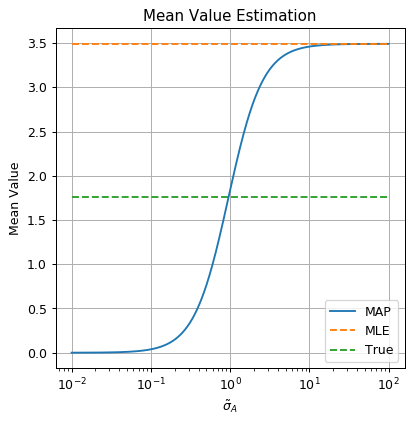
Interpretation
In this case, of a normal distributions as a prior and a normal distribution as a model, the MAP estimation will be a weighted average between the MLE result of and the mean value of the prior distribution, which is 0 in this case.
Not surprisingly we get the best results when our prior is the exact the true underlying distribution with: .
When the prior is very strong, i.e. a very narrow Gaussian, , this dictates that the probability of the mean value to be far from 0 is very low, which results in an estimation which is very close to 0.
When the prior is very weak, i.e. a very wide Gaussian, , the prior probability becomes close to uniform in the relevant range of values. This is equal to not using a prior at all, and the MAP estimation approaches the MLE.
In general, using a prior could also give results which are worse than the MLE. This would happen for example if as a prior we would use a normal distribution with a mean value which is very different then the true mean value of .
In practice in many cases it is hard to choose a good prior, a fact which makes the MAP approach a bit more difficult to use in practice.
%%html
<link rel="stylesheet" href="../css/style.css"> <!--Setting styles - You can simply ignore this line-->