עצי החלטה
תקציר התאוריה
עצי החלטה הינם כלי נפוץ ופשוט יחסית לסיווג ורגרסיה. בבסיסו עץ החלטה הינו מימוש מסוים של פונקציות לוגיות (כניסה ויציאה דיסקרטית), אולם ניתן ליישמו גם עבור משתנים רציפים על ידי דיסקרטיזציה.
:דוגמא לשימוש בעץ החלטה לצורך סיווג פירות לפי מספר מאפיינים
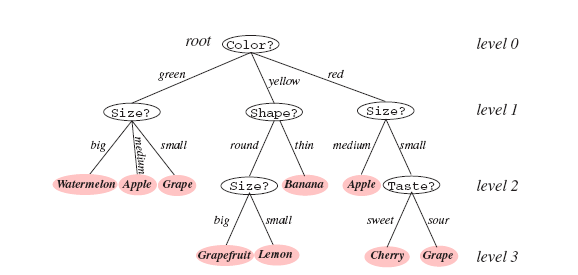
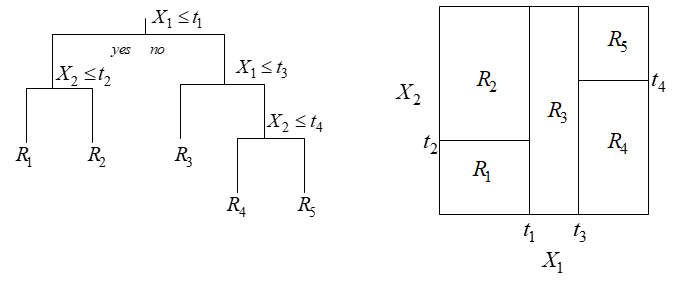
דוגמא לשימוש בעץ החלטה כאשר מרחק הקלט הוא רציף:
מטרת חלק זה היא להדגים בנייה של עץ החלטה, על סמך אוסף דוגמאות מתויג, כאשר נבנה את עץ ההחלטה עם התכונות הבאות:
- סיווג נכון של מרבית הדוגמאות.
- עץ קצר (פשוט) ככל הניתן.
תכונה 2 חשובה משתי סיבות:
- פשטות המימוש.
- יכולת הכללה: מניעת התאמת-יתר לאוסף הדוגמאות הנתון.
נציג מספר הגדרות ומספר קריטריונים שונים לבחירת המאפיין המיטבי שעל פיו נבנה העץ. יהי אוסף של דוגמאות מסווגות , כך ש- כאשר הינו מספר המחלקות האפשריות.
השכיחות היחסית (או “הפילוג האמפירי”) של כל אחד מהסיווגים האפשריים בקבוצת הדוגמאות נתונה ע”י:
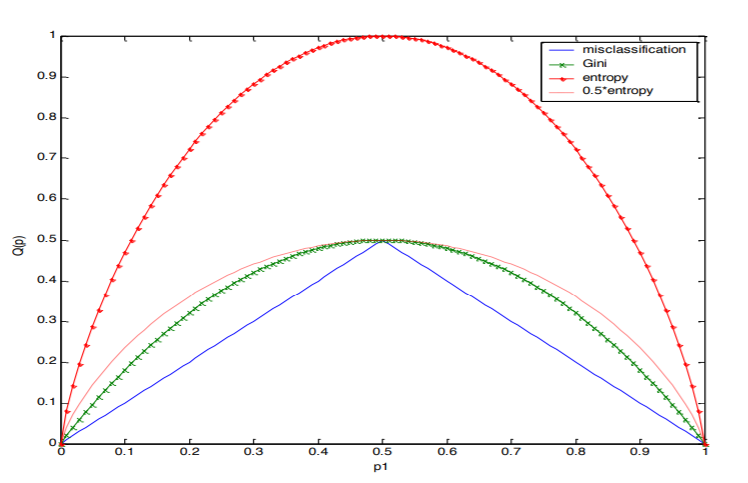
מדדים אחידות של :
- שגיאת הסיווג:
- אינדקס Gini:
- אנטרופיה:
תכונות של :
- עבור פילוג חד-ערכי ( עבור כלשהו).
- מקבל את ערכו המכסימלי עבור פילוג אחיד ( ).
תוספת המידע של מאפיין: נניח כי מאפיין כלשהו מחלק את למספר תת-קבוצות. נסמן תת-קבוצות אלו על ידי , כאשר הינו אוסף הערכים האפשריים של .
מדד האחידות המשוקלל עבור האוסף יוגדר עתה על ידי:
כאשר הוא מדד לחוסר האחידות של תת-הקבוצה .
מדד הטיב של המאפיין ביחס לקבוצת הדוגמאות יוגדר עתה על ידי
ניתן לראות כי זהו הגידול באחידות (או הקטנה בחוסר-האחידות) של האוסף לעומת קבוצת הדוגמאות המקורית . כאשר הינה האנטרופיה, נקרא גם תוספת המידע (information gain) של המאפיין .
המאפיין שנבחר הוא (כעיקרון) זה שעבורו השיפור הינו מקסימלי כלומר מינימלי.
שאלה 12.1 – בניית עץ החלטה
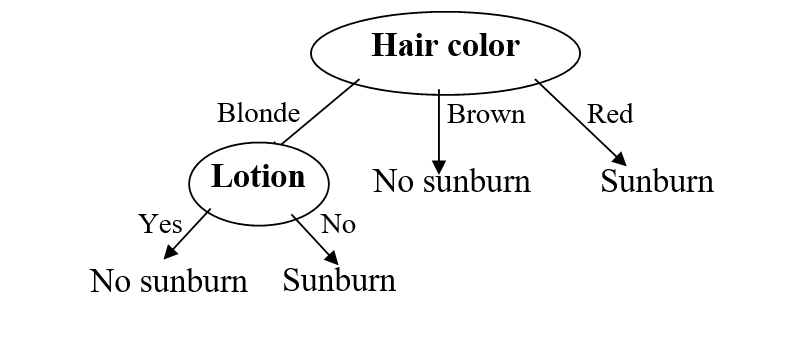
בנה עץ החלטה המבוסס על קריטריון האנטרופיה, אשר בהינתן נתוני צבע שער, גובה, משקל, משתמש בקרם הגנה, קובע האם עתיד האדם להכוות מהשמש היוקדת.
סט דוגמאות הלימוד לצורך בניית העץ מוצג בטבלה הבאה:
| Name | Hair | Height | Weight | Lotion | Result (Label) |
|---|---|---|---|---|---|
| Sarah | blonde | average | light | no | sunburned (positive) |
| Dana | blonde | tall | average | yes | none (negative) |
| Alex | brown | short | average | yes | none |
| Annie | blonde | short | average | no | sunburned |
| Emily | red | average | heavy | no | sunburned |
| Pete | brown | tall | heavy | no | none |
| John | brown | average | heavy | no | none |
| Katie | blonde | short | light | yes | none |
פתרון שאלה 12.1
אנו נמצאים בשורש ולכן הוא קבוצת כל האנשים. ראשית נחשב את האנטרופיה על פני כלל הדוגמאות:
כעת נבחן את האנטרופיה שתושרה לאחר פיצול לפי כל אחד מהמאפיינים האפשריים:
Hair:
| Feature | Distribution | |
|---|---|---|
| Blonde | ||
| Brown | ||
| Red |
ומדד הטיב של מאפיין Hair יחושב לפי האנטרופיה המשוקללת על פני הפיצולים האפשריים:
Height:
| Feature | Distribution | |
|---|---|---|
| Short | ||
| Average | ||
| Tall |
ומדד הטיב של מאפיין Height יחושב לפי האנטרופיה המשוקללת על פני הפיצולים האפשריים:
Weight:
| Feature | Distribution | |
|---|---|---|
| Light | ||
| Average | ||
| Heavy |
ומדד הטיב של מאפיין weight יחושב לפי האנטרופיה המשוקללת על פני הפיצולים האפשריים:
Lotion:
| Feature | Distribution | |
|---|---|---|
| No | ||
| Yes |
ומדד הטיב של מאפיין lotion יחושב לפי האנטרופיה המשוקללת על פני הפיצולים האפשריים:
מכאן שהמאפיין האופטימלי לפיצול הראשון (על פי קריטריון האנטרופיה) הוא Hair.
עבור הפיצול של הרמה השנייה נשים לב כי הענפים של Hair=brown ו Hair=red בעלי אנטרופיה מקסימלית. כלומר, ניתן לסווג את הדוגמאות בצורה מושלמת לכן אין צורך בפיצולים נוספים. לגבי הענף Hair=blonde: קבוצת הדוגמאות בענף זה היא:
| Name | Hair | Height | Weight | Lotion | Result (Label) |
|---|---|---|---|---|---|
| Sarah | blonde | average | light | no | sunburned (positive) |
| Dana | blonde | tall | average | yes | none (negative) |
| Annie | blonde | short | average | no | sunburned |
| Katie | blonde | short | light | yes | none |
פיצול לפי מאפיין height ייתן:
| Feature | Distribution | |
|---|---|---|
| Short | ||
| Average | ||
| Tall |
לפי weight:
| Feature | Distribution | |
|---|---|---|
| Light | ||
| Average | ||
| Heavy |
לפי Lotion:
| Feature | Distribution | |
|---|---|---|
| No | ||
| Yes |
לפיכך הקריטריון האופטימלי (זה שממזער את קריטריון הגידול) הוא Lotion.
עץ ההחלטה הסופי יראה כך:
בעיית התאמת היתר (overfitting):
ניתן לסווג את הדוגמאות באופן מושלם רק על סמך “מאפיין” שם ו”מאפיין” זה בוודאי ייבחר בצומת הראשונה לפי קריטריון “תוספת המידע”. אולם לקריטריון זה ערך מועט לצורך חיזוי.
מקור הבעיה: בקריטריון שבו השתמשנו קיימת העדפה מובנית למאפיינים בעלי מספר ערכים רב.
פתרון אפשרי: נרמול “תוספת המידע” של מאפיין באופן הבא:
כאשר הינו מקדם פיצול מתאים. הגדרה מקובלת:
כאשר, היינו מספר הערכים השונים של הנאפיין , המתקבלים על פני איברי הקבוצה
מאפיינים רציפים:
נניח כי וקטור המאפיינים כולל רכיבים בעלי ערכים רציפים.
במקרה זה, המבחן המקובל לגבי הינו מהצורה .
לפיכך, לבחירת המאפיין בכל צומת יש להוסיף את בחירת ערך הסף .
עבור כל מבחן ניתן להגדיר את תוספת המידע באופן הרגיל:
השלב הבא הוא מקסימיזציה על הסף :
ולאחר מכן בחירת המאפיין שעבורו מדד זה הינו מקסימלי.
Boosting - Adaboost
AdaBoost (Adaptive Boosting) הינה טכניקה לשיפור ביצועים של אלגוריתם סיווג על ידי שילוב ממושקל של מספר מסווגים. עיקרון מבוסס על בנייה איטרטיבית של מסווג אשר מורכב ממספר מסווגים, כשאר בתהליך הבנייה נשמר ווקטור של משקולות המעיד על טיב הסיווג של כל נקודה בסט על ידי סך הסיווגים הקודמים (מכל המסווגים). בכל שלב האלגוריתם מנסה לבנות מסווג שיתקן את הטעויות שנעשו מהמסווגים הקודמים.
נסמן:
- - גודל ה dataset
- - המדידות והמחלקות.
- ערכי המחלקות הם
אלגוריתם:
- אתחל באופן אחיד את המשקולות עבור כל נקודה ב dataset:
- המשך באופן איטרטיבי עבור אינדקס עד להגעת תנאי עצירה:
- בנה מסווג אופטימלי ביחס ל- dataset הממושקל
- חשב את שגיאת הסיווג של עבור ה dataset הממושקל:
- חשב את משקל עבור המסווג לפי:
- עדכן את המשקולות עבור כל נקודה ב-dataset :
- נרמל את המשקולות לפי: according to:
הסיווג הסופי נעשה על ידי קומבינציה לינארית של כל מסווגים והמשקל שלהם.
תרגיל 12.2: הדגמת האלגוריתם
נתבונן בבעיית סיווג חד מימדית עבור סט דוגמאות האימון:
יהי המודל:
-
האם קיימים מסווגים ליניאריים ופרמטרים כך שהשגיאה של היפותזה היא אפס על כל סט האימון? אם כן, מה ה-T המינימאלי לקבל שגיאה אפס?
-
רשום את שלבי אלגוריתם AdaBoost עבור הדוגמא.
פתרון
- ראשית נסתכל בבעיה:

נשים לב, שמסווג בודד לא יפתור את הבעיה משום שלא קיימת הפרדה לינארית בין המחלקות. עבור שני מסווגים לא ניתן למצוא מקדמים שעבור נקבל שגיאת אימון אפס. ניתן לקבל שגיאה אפס עבור שלושה מסווגים חלשים בהן נתייג נכון את כל הדוגמאות.
2. נאתחל את הפילוג:
נקח את המסווג הבא:
עבורו נקבל:
וכרגע ניתן לעדכן את התפלגות הדוגמאות:
באיטרציה הבאה נבחר את המסווג הבא:
עבורו נקבל:
נעדכן את הפילוג לפי המסווג הנוסף:
עבור הבעיה בדוגמה, מספיק עוד מסווג חלש אחד אותו נבחר כך:
עבורו נקבל:
נעדכן את הפילוג לפי המסווג הנוסף:
לבסוף המסווג עם שגיאה אפס המתקבל היינו:
AdaBoost חלק מעשי
האתגר: בחזרה לטיטניק

ננסה לחזות האם נוסע בטיטניק ישרוד או לא על סמך רישום ונתונים של הנוסעים.
Dataset: The Titanic Manifest
ניתן להוריד את הdataset מהקישור הזה
🕵️ Data Inspection
התרשמות ראשונית ממאגר המידע, עשר שורות ראשונות מהרשומות:
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | numeric_sex | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO | 1 |
| 1 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON | 1 |
| 2 | 1 | 0 | Allison, Mr. Hudson Joshua Creighton | male | 30 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | 135.0 | Montreal, PQ / Chesterville, ON | 0 |
| 3 | 1 | 0 | Allison, Mrs. Hudson J C (Bessie Waldo Daniels) | female | 25 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON | 1 |
| 4 | 1 | 1 | Anderson, Mr. Harry | male | 48 | 0 | 0 | 19952 | 26.5500 | E12 | S | 3 | NaN | New York, NY | 0 |
| 5 | 1 | 1 | Andrews, Miss. Kornelia Theodosia | female | 63 | 1 | 0 | 13502 | 77.9583 | D7 | S | 10 | NaN | Hudson, NY | 1 |
| 6 | 1 | 0 | Andrews, Mr. Thomas Jr | male | 39 | 0 | 0 | 112050 | 0.0000 | A36 | S | NaN | NaN | Belfast, NI | 0 |
| 7 | 1 | 1 | Appleton, Mrs. Edward Dale (Charlotte Lamson) | female | 53 | 2 | 0 | 11769 | 51.4792 | C101 | S | D | NaN | Bayside, Queens, NY | 1 |
| 8 | 1 | 0 | Artagaveytia, Mr. Ramon | male | 71 | 0 | 0 | PC 17609 | 49.5042 | NaN | C | NaN | 22.0 | Montevideo, Uruguay | 0 |
| 9 | 1 | 0 | Astor, Col. John Jacob | male | 47 | 1 | 0 | PC 17757 | 227.5250 | C62 C64 | C | NaN | 124.0 | New York, NY | 0 |
סה”כ ישנם רשומות במאגר מידע.
The Data Fields and Types
נעשה שימוש בשדות (מאפיינים) הבאים:
- pclass: מחלקת הנוסע: 1, 2 או 3
- sex: מין הנוסע
- age: גיל הנוסע
- sibsp: מס’ של אחים ובני זוג של כל נוסע על האוניה
- parch: מס’ של ילדים או הורים של כל נוסע על האונייה
- fare: המחיר שהנוסע שילם על הכרטיס
- embarked: הנמל בו עלה הנוסע על האונייה (C = Cherbourg; Q = Queenstown; S = Southampton)
- survived: התיוג, האם הנוסע שרד או לא
📉 התרשמות ראשונית בעזרת גרפים
נציג את היחס בין המחלקות (שורדים ונספים) עבור המאפיינים:
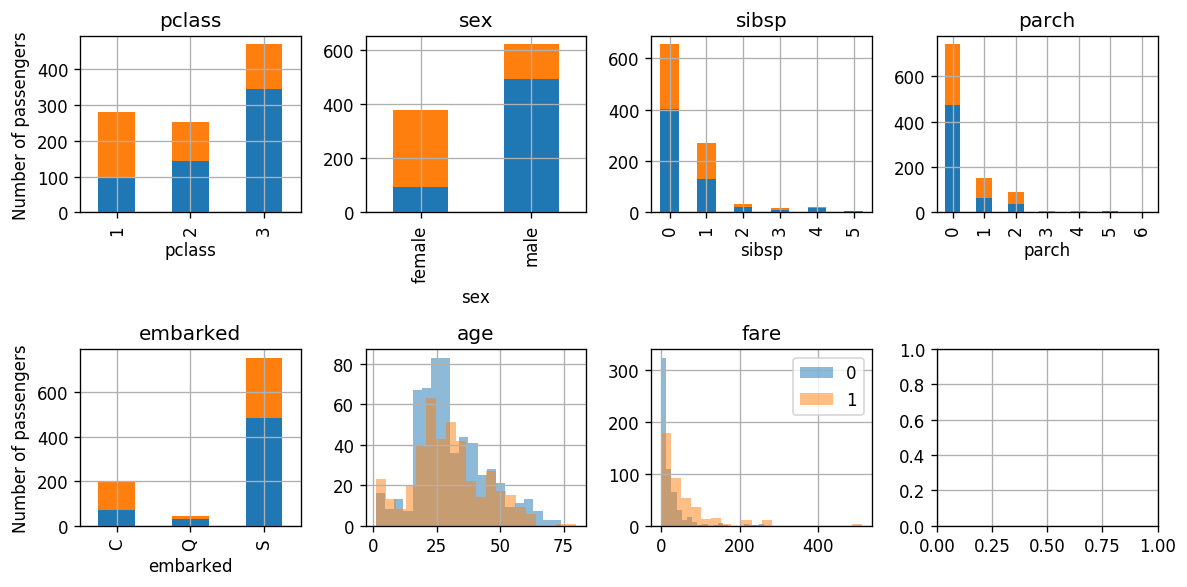
📜 הגדרת הבעיה :#
- משתנים אקראיים:
- : מאפייני הנוסע
- : תיוג הנוסע, שרד או נספה
נמצא מסווג אשר מביא למינימום את ה- miscalssification rate:
💡 Model & Learning Method Suggestion: Stumps + AdaBoost
.נשתמש בעץ בינארי בעל עומק אחד (נקרא Stump), שבעצם מסווג על פי מאפיין בודד בשילוב של אלגוריתם AdaBoost
הערה: ניתן להגיד שהשילוב הנ”ל הוא וריאציה של Random Forest, אלגוריתם שמשלב מספר עצים. כמו כן הטכניקה הזאת נקראת גם Ensemble.
עבור קריטריון בניית עץ נשתמש בGini אינדקס ממושקל הנובע מה-data הממושקל. עבור חלוקה של ה-data לשני סטים and , וסט המשקולות של הדגימות נקבל את Gini אינדקס ממושקל:
פרמטרים נלמדים:
- החלוקה המתבצעת על ידי כל עץ.
- משקול כל עץ: .
Hyper-parameters
ההיפר פרמטרי היחידי הינו קריטריון העצירה עבור אלגוריתם Adaboost שעבורו מוחלט מס’ עצי ההחלטה שמשולבים במסווג הסופי.
📚 חלוקת ה-dataset
נחלק ל 80% סט אימון ו 20% סט בוחן.
⚙️ אימון
נאתחל את המודל ונציג את עשר השורות הראשונות של הdataset הממושקל וההתפלגות לפי המאפיינים:
| age | embarked | fare | parch | pclass | sex | sibsp | survived | weights | |
|---|---|---|---|---|---|---|---|---|---|
| 724 | 11 | 2 | 46.9000 | 2 | 2 | 0 | 5 | 0 | 0.001252 |
| 77 | 27 | 2 | 30.5000 | 0 | 0 | 0 | 0 | 1 | 0.001252 |
| 879 | 6 | 2 | 21.0750 | 1 | 2 | 0 | 3 | 0 | 0.001252 |
| 615 | 22 | 2 | 7.2500 | 0 | 2 | 0 | 1 | 0 | 0.001252 |
| 905 | 24 | 2 | 8.6625 | 0 | 2 | 0 | 0 | 0 | 0.001252 |
| 533 | 42 | 2 | 7.5500 | 0 | 2 | 0 | 0 | 0 | 0.001252 |
| 401 | 50 | 2 | 13.0000 | 0 | 1 | 0 | 0 | 0 | 0.001252 |
| 454 | 39 | 2 | 26.0000 | 0 | 1 | 0 | 0 | 0 | 0.001252 |
| 31 | 58 | 2 | 26.5500 | 0 | 0 | 1 | 0 | 1 | 0.001252 |
| 358 | 18 | 2 | 13.0000 | 0 | 1 | 0 | 0 | 0 | 0.001252 |
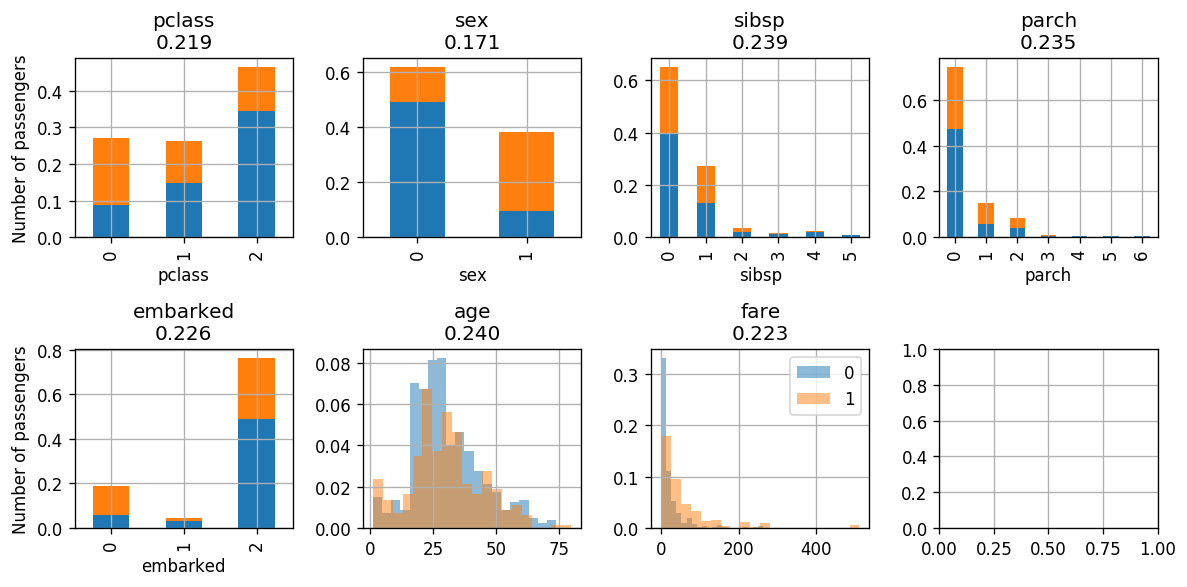
אינדקס Gini המושקלל מצויין בכותרת של כל גרף. בכל איטרציה של Adaboost נבחר את העץ שיפעל על המאפיין בעל האינדקס הנמוך ביותר. כאשר במקרה זה נבחר לפי מין הנוסע.
Iteration:
לאחר איטרציה בודדת של סיווג לפי מין קיבלנו:
- שגיאה: 0.22
- : 0.6320312618746508
- Classifing sex according to: {0: [0], 1: [1]}
נציג את המשוקל של ה-data מחדש, וההתפלגויות החדשות:
| age | embarked | fare | parch | pclass | sex | sibsp | survived | weights | |
|---|---|---|---|---|---|---|---|---|---|
| 724 | 11 | 2 | 46.9000 | 2 | 2 | 0 | 5 | 0 | 0.000803 |
| 77 | 27 | 2 | 30.5000 | 0 | 0 | 0 | 0 | 1 | 0.002841 |
| 879 | 6 | 2 | 21.0750 | 1 | 2 | 0 | 3 | 0 | 0.000803 |
| 615 | 22 | 2 | 7.2500 | 0 | 2 | 0 | 1 | 0 | 0.000803 |
| 905 | 24 | 2 | 8.6625 | 0 | 2 | 0 | 0 | 0 | 0.000803 |
| 533 | 42 | 2 | 7.5500 | 0 | 2 | 0 | 0 | 0 | 0.000803 |
| 401 | 50 | 2 | 13.0000 | 0 | 1 | 0 | 0 | 0 | 0.000803 |
| 454 | 39 | 2 | 26.0000 | 0 | 1 | 0 | 0 | 0 | 0.000803 |
| 31 | 58 | 2 | 26.5500 | 0 | 0 | 1 | 0 | 1 | 0.000803 |
| 358 | 18 | 2 | 13.0000 | 0 | 1 | 0 | 0 | 0 | 0.000803 |
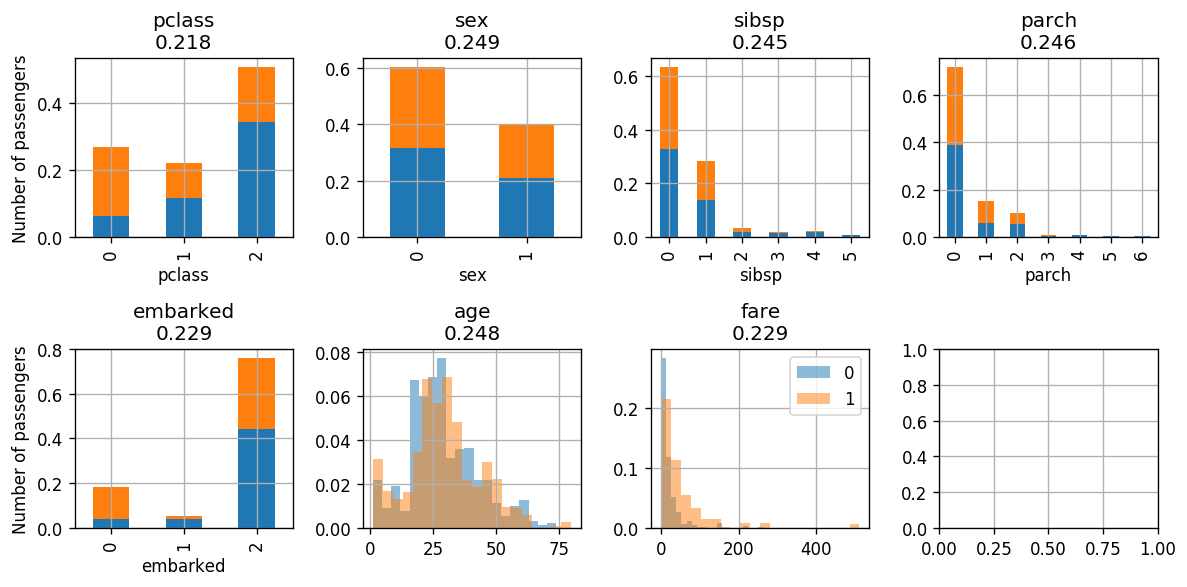
נבחין בכך, שככל שנתקדם באיטרציות של האלגוריתם, ה-data הממושקל יתפלג באופן אחיד כפונקציה של המחלקות, כלומר ההתפלגות של הדגימות שעבורן זהה להתפלגות של הדגימות שעבורן .
כתוצאה מכך, הסיווג על פי מאפיין בודד יהיה קשה יותר והשגיאה למסווג בודד תתקרב ל-0.5, ובאופן ישיר המשקל של כל מסווג ידעך.
בשלב הבא נסווג לפי pclass:
Iteration
לאחר איטרציה נוספת של סיווג לפי מחלקת נוסע קיבלנו:
- שגיאה: 0.66
- : -0.34
- Classifing pclass according to: {1: [0], 0: [1, 2]}
| age | embarked | fare | parch | pclass | sex | sibsp | survived | weights | |
|---|---|---|---|---|---|---|---|---|---|
| 724 | 11 | 2 | 46.9000 | 2 | 2 | 0 | 5 | 0 | 0.000601 |
| 77 | 27 | 2 | 30.5000 | 0 | 0 | 0 | 0 | 1 | 0.002127 |
| 879 | 6 | 2 | 21.0750 | 1 | 2 | 0 | 3 | 0 | 0.000601 |
| 615 | 22 | 2 | 7.2500 | 0 | 2 | 0 | 1 | 0 | 0.000601 |
| 905 | 24 | 2 | 8.6625 | 0 | 2 | 0 | 0 | 0 | 0.000601 |
| 533 | 42 | 2 | 7.5500 | 0 | 2 | 0 | 0 | 0 | 0.000601 |
| 401 | 50 | 2 | 13.0000 | 0 | 1 | 0 | 0 | 0 | 0.000601 |
| 454 | 39 | 2 | 26.0000 | 0 | 1 | 0 | 0 | 0 | 0.000601 |
| 31 | 58 | 2 | 26.5500 | 0 | 0 | 1 | 0 | 1 | 0.000601 |
| 358 | 18 | 2 | 13.0000 | 0 | 1 | 0 | 0 | 0 | 0.000601 |
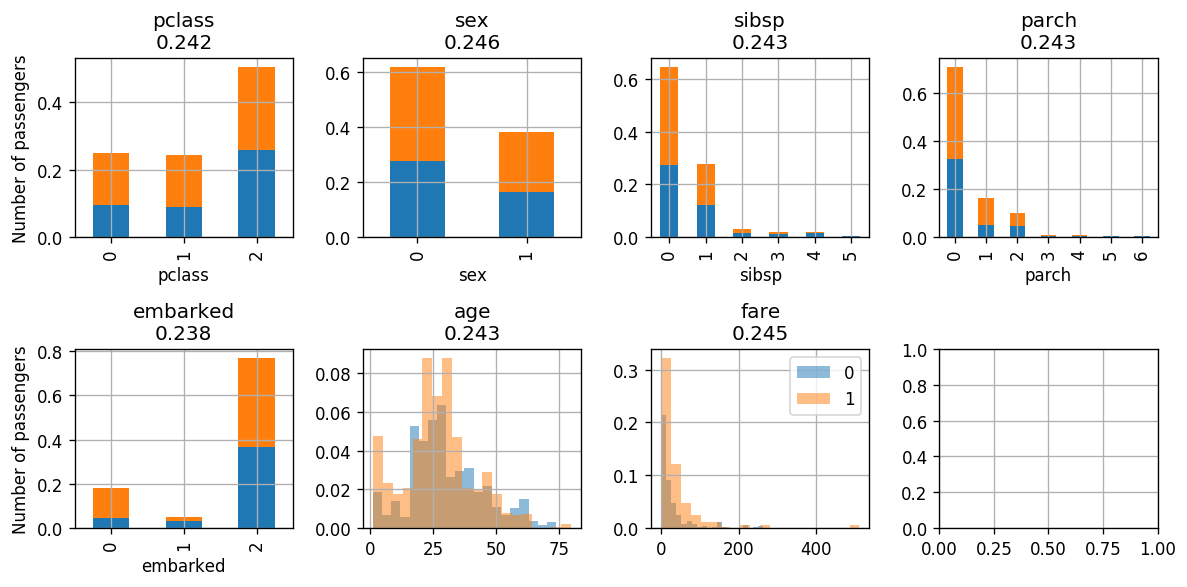
באיטרציה השלישית נסווג לפי embarked:
Iteration
- שגיאה: 0.53
- : -0.06
- Classifing embarked according to: {1: [0], 0: [1, 2]}
| age | embarked | fare | parch | pclass | sex | sibsp | survived | weights | |
|---|---|---|---|---|---|---|---|---|---|
| 724 | 11 | 2 | 46.9000 | 2 | 2 | 0 | 5 | 0 | 0.000564 |
| 77 | 27 | 2 | 30.5000 | 0 | 0 | 0 | 0 | 1 | 0.002274 |
| 879 | 6 | 2 | 21.0750 | 1 | 2 | 0 | 3 | 0 | 0.000564 |
| 615 | 22 | 2 | 7.2500 | 0 | 2 | 0 | 1 | 0 | 0.000564 |
| 905 | 24 | 2 | 8.6625 | 0 | 2 | 0 | 0 | 0 | 0.000564 |
| 533 | 42 | 2 | 7.5500 | 0 | 2 | 0 | 0 | 0 | 0.000564 |
| 401 | 50 | 2 | 13.0000 | 0 | 1 | 0 | 0 | 0 | 0.000564 |
| 454 | 39 | 2 | 26.0000 | 0 | 1 | 0 | 0 | 0 | 0.000564 |
| 31 | 58 | 2 | 26.5500 | 0 | 0 | 1 | 0 | 1 | 0.000643 |
| 358 | 18 | 2 | 13.0000 | 0 | 1 | 0 | 0 | 0 | 0.000564 |
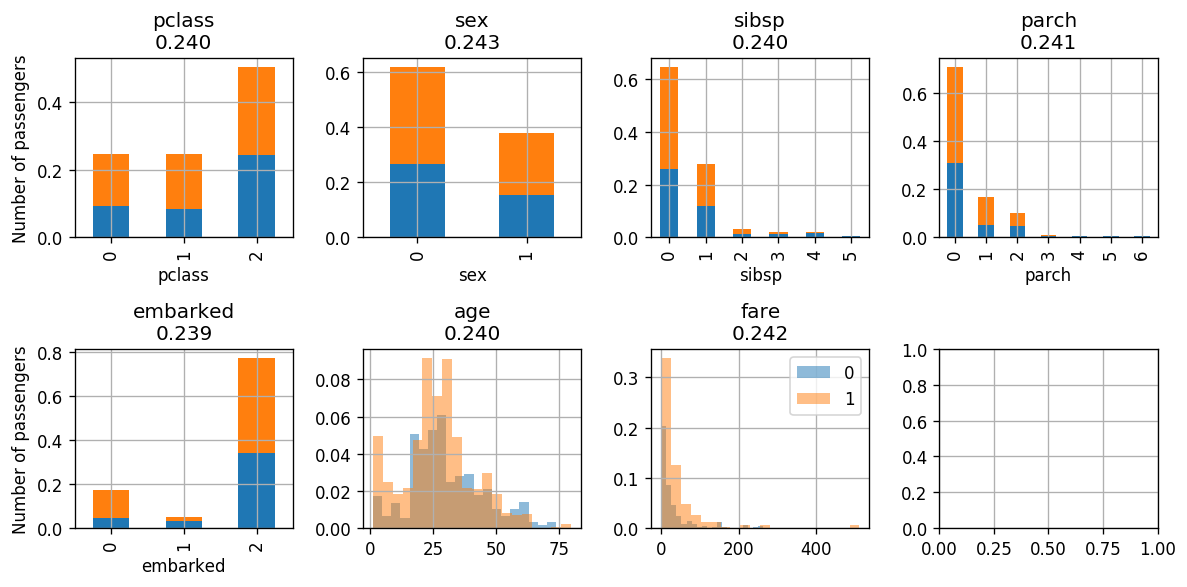
נשים לב שגם אחרי האאינטרציה השלישית קיבלנו את האינדקס הנמוך ביותר עבור embarked. על כן באיטרציה הבאה נסווג עלפיו (ואפשר כבר לנחש שלא נשתפר בביצועים)
Iteration
- שגיאה : 0.5000000000000001
- : -2.2204460492503136e-16
- Classifing embarked according to: {1: [0], 0: [1, 2]}
| age | embarked | fare | parch | pclass | sex | sibsp | survived | weights | |
|---|---|---|---|---|---|---|---|---|---|
| 724 | 11 | 2 | 46.9000 | 2 | 2 | 0 | 5 | 0 | 0.000564 |
| 77 | 27 | 2 | 30.5000 | 0 | 0 | 0 | 0 | 1 | 0.002274 |
| 879 | 6 | 2 | 21.0750 | 1 | 2 | 0 | 3 | 0 | 0.000564 |
| 615 | 22 | 2 | 7.2500 | 0 | 2 | 0 | 1 | 0 | 0.000564 |
| 905 | 24 | 2 | 8.6625 | 0 | 2 | 0 | 0 | 0 | 0.000564 |
| 533 | 42 | 2 | 7.5500 | 0 | 2 | 0 | 0 | 0 | 0.000564 |
| 401 | 50 | 2 | 13.0000 | 0 | 1 | 0 | 0 | 0 | 0.000564 |
| 454 | 39 | 2 | 26.0000 | 0 | 1 | 0 | 0 | 0 | 0.000564 |
| 31 | 58 | 2 | 26.5500 | 0 | 0 | 1 | 0 | 1 | 0.000643 |
| 358 | 18 | 2 | 13.0000 | 0 | 1 | 0 | 0 | 0 | 0.000564 |
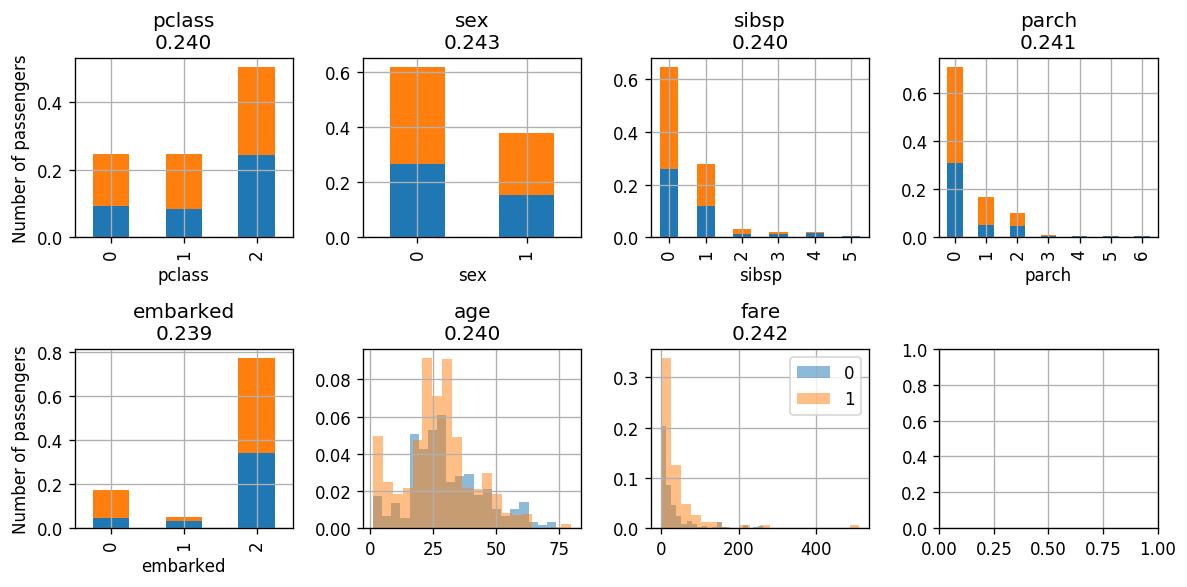
באיטרציה האחרונה קיבלנו ששגיאת המסווג קרובה ל 0.5 והמשקל שלו , לכן ניתן להפסיק את תהליך הלימוד.
⏱️ ביצועים:
נריץ את האלגוריתם המאומן על סט המבחן ונקבל שהסיכון היינו: