מוטיבציה
-
עסקנו בתרגולים קודמים בסיווג לינארי:
- מציאת מישור לינארי אשר מפריד בין המחלקות.
- עם זאת, למעשה ניתן למצוא אינסוף מישורי הפרדה כאלה במקרה הלא לינארי.
-
SVM הינו אלגוריתם סיווג לינארי המבוסס על הרעיון הבא:
לבחור את מישור ההפרדה אשר ממקסם את השוליים (Margin) בין המחלקות.
תזכורת - גאומטריה של המישור
-
משוואה של מישור ב- :
עבור ו- , קבועים המגדירים את המישור.
-
מרחק אוקלידי של נקודה מהמישור הינו:
Hard SVM
בעיית אופטימיזציה זו מתאימה למקרה ששתי המחלקות ניתנות להפרדה לינארית.
בחירת ה- Margin המקסימלי שקולה לפתרון בעיית האופטימיזציה הבאה:
- בעיה זו מכונה הבעיה הפרימאלית.
- שהאילוץ דורש שכל הנקודות יסווגו נכון על ידי המסווג הלינארי.
הבעיה הדואלית
בעית האופטימיזציה הבאה, אשר נקראת הבעיה הדואלית, שקולה לבעיה לעיל:
-
ניתן לחשב את המשקולות באמצעות הקשר הבא:
הבעיה הדואלית - המשך
הבעיה הדואלית מדגישה תכונה מעניינת של הפתרון:
עבור פתרון בעיית ה- SVM, כל דוגמא מסט הלימוד תציית לאחד מהתנאים הבאים:
1. and
2. and
-
מהמשוואה , ניתן לראות שהפתרון הוא קומבינציה לינארית של הדוגמאות .
-
רק עבור דוגמא שעבורה מתקיים , משתתפת בהגדרת הערך של .
-
נקודות אלה נקראות וקטורי תמיכה (Support Vectors) ובמקרה הכללי, המספר שלהם יהיה נמוך.
תכונות ה- Support Vectors
-
מרחקן למישור המפריד הוא מינימלי.
-
אם ורק אם היא SV.
-
אם היא SV, מתקיים
(הכיוון ההפוך לא בהכרח מתקיים, כלומר יכולה להיות דוגמה עבורה השוויון הנ”ל מתקיים אך ).
-
המרחק האוקלידי של ה SV מהמישור המפריד נקרא ה- margin של הבעיה, והוא שווה ל (תרגיל: הוכיחו את הביטוי הנ”ל, בעזרת הביטוי למרחק נקודה ממישור ותכונה מס’ 3).
שאלה 1 - דוגמאות ניתנות להפרדה לינארית
נתונות שתי המחלקות הבאות:
מחלקה 1: ()
מחלקה 2: ( )
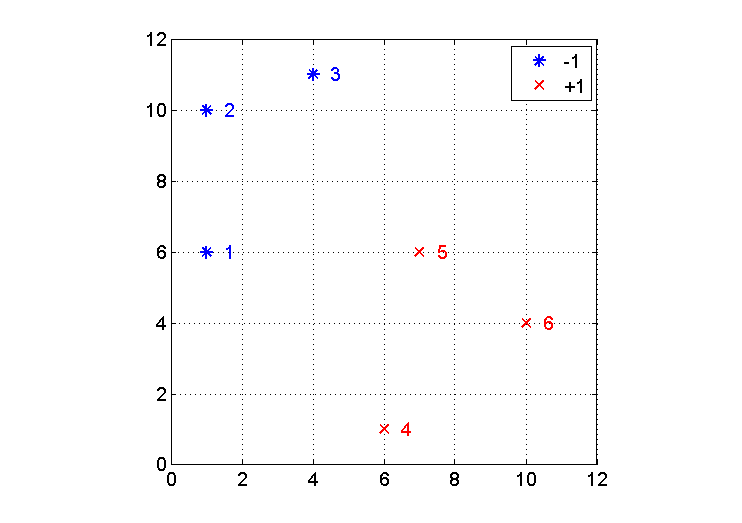
א. צייר את מסווג ה-SVM הלינארי לבעיה זו? מהם וקטורי התמיכה (support vectors)?
ב. נתון כי הערכים האופטימליים של הבעיה הדואלית הם: לאילו דוגמאות שייכים הערכים השווים לאפס?
ג. חשב את ערך הווקטור w האופטימאלי של הבעיה הפרימאלית?
ד. מהו ה-margin של הבעיה?
ה. חשב את ה-margin ישירות מערכי .
א. צייר את מסווג ה-SVM הלינארי לבעיה זו? מהם וקטורי התמיכה (support vectors)?
פתרון
נבדוק מה המספר האפשרי של ווקטורי תמיכה בבעיה זו:
- :
אפשרי באופן עקרוני, אם כל הנקודות בסט הלימוד שייכות רק למחלקה אחת. הפתרון האופטימלי המתקבל הוא . מצב זה לא מתקיים בסט הלימוד הנתון בשאלה.
- :
לא אפשרי במקרה הכללי, שכן אי אפשר לקיים את התנאי עם אחד בלבד ששונה מ- 0. היוצא מהכלל הוא מקרה פרטי בו אנו מאלצים את המישור המפריד לעבור בראשית, כלומר קובעים . במצב זה אינו מופיע בבעית האופטימיזציה, ולא נקבל את התנאי . השאלה דנה במקרה הכללי ולכן לא נבדוק את המקרה הזה.
- :
אפשרי. במקרה זה הווקטור ניצב לקו המחבר את ווקטורי התמיכה. זוגות אפשריים הן הנקודות (ראו ציור) . ע”י בדיקה רואים שכל הזוגות מובילים לסתירה עם ההנחה שהם ווקטורי תמיכה, שכן עבור כל זוג קייימת נקודה אחרת שיותר קרובה למישור המפריד, בסתירה לתכונות ה- SV.
- :
אפשרי.
השלשות המועמדות הן נקודות או . עבור כל שלשה ניתן לפתור עבור תוך שימוש באילוץ (שמתקיים בשוויון עבור ה- SV). הצבת 3 נקודות תיתן 3 משוואות ב 3 נעלמים, ונקבל פתרון יחיד לנעלמים ו- .
מקבלים:
והפתרון האופטימלי הוא השלשה עם מינימלי, כלומר .
ב. נתון כי הערכים האופטימליים של הבעיה הדואלית הם:
לאילו דוגמאות שייכים הערכים השווים לאפס?
ב. נתון כי הערכים האופטימליים של הבעיה הדואלית הם:
לאילו דוגמאות שייכים הערכים השווים לאפס?
פתרון
הערכים עבורם שייכים לדוגמאות שאינן ה SV.
ג. חשב את ערך הווקטור w האופטימאלי של הבעיה הפרימאלית?
ד. מהו ה-margin של הבעיה?
ה. חשב את ה-margin ישירות מערכי .
פתרון
ג. את האופטימלי מצאנו בסעיף א’.
ד. ה- margin של הבעיה הוא
ה. נמצא את ע”י הנוסחה:
מתקבל כמובן אותו כמו מסעיף א’ וה margin מחושב כמו בסעיף ד’.
Soft SVM
-
במקרה שהמחלקות לא פרידות לינארית, בעית האופטימיזציה לעיל איננה פתירה:
- לא ניתן לקיים את האילוץ לכל הנקודות.
-
לכן, ניתן להשתמש בגרסה אחרת של בעית האופטימיזציה אשר עושה שימוש במשתנים שמאפשרים את הפרת האילוץ. באנגלית, משתנים אלו מכונים Slack Variables.
-
-
בעזרת השימוש במשתנים אלה, ניתן להפר את האילוץ, ולכן להגיע לפתרון שלא מסווג באופן מושלם את כל הדוגמאות.
-
כדי שעדיין תהיה משמעות לבעיית האופטימיזציה, נעניש את השימוש במשתנים האלה, כדי למנוע ככל הניתן את כמות ההפרות של האילוץ.
-
Soft SVM
הבעיה הפריאמלית:
הבעיה הדואלית:
כאשר, הקשר הבא עדיין מתקיים:
כעת, הדוגמאות ב- Data יקיימו את אחד משלושת התנאים האים:
-
and
-
and
-
and
פונקציות גרעין - מסווג לא לינארי
-
עבור הרבה בעיות מעשיות, משטח החלטה לינארי אינו מפריד בצורה טובה בין המחלקות, ונצפה שמשטח החלטה לא לינארי ישיג ביצועים יותר טובים.
-
ניתן למצוא משטח הפרדה כזה באמצעות טרנספורמציה לא לינארית ממרחב הקלט למרחב חדש: , כאשר .
-
אימון של מסווג לינארי במרחב החדש, שיראה מהצורה , שקול למסווג לא-לינארי במרחב המקורי.
דוגמה: 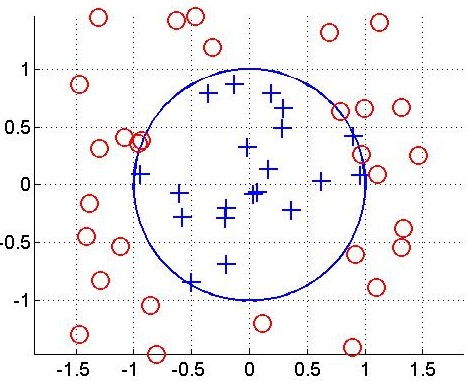
- במרחב אין מפריד לינארי,
- אך הטרנספורמציה מאפשרת לסווג את הדוגמאות
ללא שגיאה עם המסווג הלינארי:
כלומר, ו-
דוגמה נוספת:
טרנספורמציה למרחב הפולינומים ממעלה עד 2, בקואורדינטות של הווקטור :
בעיה: טרנספורמציה למרחב חדש יכולה להיות יקרה חישובית אם המימד של המרחב החדש גבוה מאוד.
בעיה: טרנספורמציה למרחב חדש יכולה להיות יקרה חישובית אם המימד של המרחב החדש גבוה מאוד.
פתרון:
ניזכר שבאמצעות פתרון הבעיה הדואלית ל- SVM עבור , הפתרון האופטימלי הינו:
אם המסווג תלוי רק במכפלות פנימיות בין ווקטורי הקלט, אין צורך לחשב את , אלא רק את המכפלות הפנימיות במרחב החדש, :
לצורך זה נציג את פונקציית הגרעין.
פונקציית גרעין (Kenel)
נגדיר פונקציית גרעין על קבוצה X (תת-קבוצה של ) כפונקציה שהינה:
א. סימטרית:
ב. לכל קבוצה סופית של נקודות , המטריצה היא מטריצה אי שלילית מוגדרת (PSD).
אזי, תחת תנאים טכניים סבירים, קיים מרחב כך שפונקציית הגרעין הינה מכפלה פנימית מהצורה:
פונקציית גרעין (Kernel) - המשך
כעת הסיווג שלנו יהיה כדלקמן:
כך ניתן לחשב ישירות את , במקום את שיכול להיות יקר לחישוב.
זאת, מאחר שחישוב זה פרופורציוני לגודל מרחב הקלט ולחישוביות הפונקציה , אך איננו תלוי ב- - גודל מרחב ה- Features.
דוגמאות לפונקציות גרעין:
א. גרעין גאוסי: .
- הפונקציות הן גאוסיאנים ו- הינו פרמטר שיש לקבוע ידנית.
ב. גרעין פולינומיאלי: ,
- כאשר פרמטר שיש לקבוע ידנית.
מפתיחת הגרעין ניתן לוודא שנקבל פולינום רב-משתנים מסדר עד באיברי הווקטורים . לכן, גרעין זה מתאים ל- Feature Space פולינומיאלי.
מדוע להשתמש בפונקציות גרעין?
נסתכל לדוגמא על הגרעין הבא: , כאשר .
ניתן להראות שגרעין זה פורס את ה- Feature Space הבא:
כאשר , כלומר את כל האיברים האפשריים מסדר .
לדוגמא:
מדוע להשתמש בפונקציות גרעין? - המשך
בסך הכל, ניתן לראות שמימד ה- Features הינו קומבינטורי (ולכן אקפוננציאלי):
כאשר
- עבור ערכים גדולים של או , חישוב ישיר דרך מרחב ה- Feature-ים נדון לכישלון, בגלל מספר החישובים האקפוננציאלי הדרוש
לעומת זאת, ניתן להשתמש ב- Kernel Trick: חישוב ישיר של הסיווג דרך ה- Kernel, באמצעות הנוסחא
- עבור, נדרשים לנו אך ורק חישובים!
מוטיבציה לשימוש בבעיה הדואלית
בתרגיל הבא, נראה שכאשר פותרים את בעית ה- SVM הדואלית, ניתן להתחמק משימוש ב- Feature-ים בעת תהליך הלימוד ולהשתמש רק בפונקציית הגרעין.
הבעיה הדואלית ניתנת לתאור בצורה הבא עבור פונקציית גרעין:
נשים לב, שאכן אין כאן תלות במרחב ה- Feature-ים החדש, אלא רק בחישוביות של ה- Kernel!
מסקנה:
-
נבצע סיווג לא לינארי באמצעות מרחב Feature-ים שמתואר על ידי kernel.
-
נוכל לחסוך חישובים רבים עקב הטרנספורמציה הזולה חישובית של ה- Kernel במסגרת הבעיה הדואלית.
תרגיל 2 - גרעין גאוסי
נתונות שתי נקודות במרחב דו מימדי,
חשבו את משטח ההפרדה עבור הגרעין הגאוסי בעל , ו - .
פתרון
-
נזכר כי כלל ההחלטה הוא
-
לכן, משטח גבול ההחלטה מקיים
-
על מנת לחשב את המשטח יש למצוא את המקדמים . לצורך כך, נפתור את הבעיה הדואלית (הפרידה):
במקרה שלנו,
- נשים לב כי וכן כי .
- מהאילוץ השני נקבל .
- בהצבה בפונקציית המטרה נקבל,
- זוהי בעיה חד מימדית ריבועית, נגזור על מנת למצוא נקודת מקסימום ונקבל,
כעת, נמצא את b:
כדי למצוא את $b$ נדרוש שאחת מהנקודות הינה SV:
ומכאן הפתרון הוא למשטח ההפרדה הוא
זוהי משוואת קו ישר (כצפוי).
חלק מעשי
בעיה: זיהוי מין הדובר על סמך אות דיבור
- בחלק זה, ננסה להשתמש ב- SVM כדי לזהות את מינו של הדובר באמצעות קולו.
- מוטיבציה למערכת כזאת יכולה להיות עוזר וירטואלי שרוצה לפנות לדובר לפי מינו.
- הרחבה לניסיון זה יכולה להיות זיהוי דובר על סמך קולו וכו’.
Dataset Labeled Voices
הרעיון וה- DATA נלקחו מ- Dataset והערכת ביצועים של קורי בקר, אשר נמצאים באתר הבא.
בפרוייקט זה נאספו 3168 דגימות קול מתוייגות מהמקורות הבאים:
- The Harvard-Haskins Database of Regularly-Timed Speech
- Telecommunications & Signal Processing Laboratory (TSP) Speech Database at McGill University
- VoxForge Speech Corpus
- Festvox CMU_ARCTIC Speech Database at Carnegie Mellon University
כל רצועת קול עברה עיבוד באמצעות כלי בשםWarbleR i כדי לייצר 20 Features לכל דגימה.
ה- Data עצמו נמצא כאן.
🔃 תהליך העבודה
🕵️ בחינת ה - Data
נסתכל על העמודות הראשונות ב- Data
מספר הרשומות :
| meanfreq | sd | median | Q25 | Q75 | IQR | skew | kurt | sp.ent | sfm | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.059781 | 0.064241 | 0.032027 | 0.015071 | 0.090193 | 0.075122 | 12.863462 | 274.402906 | 0.893369 | 0.491918 | male |
| 1 | 0.066009 | 0.067310 | 0.040229 | 0.019414 | 0.092666 | 0.073252 | 22.423285 | 634.613855 | 0.892193 | 0.513724 | male |
| 2 | 0.077316 | 0.083829 | 0.036718 | 0.008701 | 0.131908 | 0.123207 | 30.757155 | 1024.927705 | 0.846389 | 0.478905 | male |
| 3 | 0.151228 | 0.072111 | 0.158011 | 0.096582 | 0.207955 | 0.111374 | 1.232831 | 4.177296 | 0.963322 | 0.727232 | male |
| 4 | 0.135120 | 0.079146 | 0.124656 | 0.078720 | 0.206045 | 0.127325 | 1.101174 | 4.333713 | 0.971955 | 0.783568 | male |
| 5 | 0.132786 | 0.079557 | 0.119090 | 0.067958 | 0.209592 | 0.141634 | 1.932562 | 8.308895 | 0.963181 | 0.738307 | male |
| 6 | 0.150762 | 0.074463 | 0.160106 | 0.092899 | 0.205718 | 0.112819 | 1.530643 | 5.987498 | 0.967573 | 0.762638 | male |
| 7 | 0.160514 | 0.076767 | 0.144337 | 0.110532 | 0.231962 | 0.121430 | 1.397156 | 4.766611 | 0.959255 | 0.719858 | male |
| 8 | 0.142239 | 0.078018 | 0.138587 | 0.088206 | 0.208587 | 0.120381 | 1.099746 | 4.070284 | 0.970723 | 0.770992 | male |
| 9 | 0.134329 | 0.080350 | 0.121451 | 0.075580 | 0.201957 | 0.126377 | 1.190368 | 4.787310 | 0.975246 | 0.804505 | male |
| 9 | 0.134329 | 0.080350 | 0.121451 | 0.075580 | 0.201957 | 0.126377 | 1.190368 | 4.787310 | 0.975246 | 0.804505 | male |
Data Fields and Types
להלן התאור של שדות ה- Data מאתר הפרוייקט:
-
meanfreq: mean frequency (in kHz)
-
sd: standard deviation of frequency
-
median: median frequency (in kHz)
-
Q25: first quantile (in kHz)
-
Q75: third quantile (in kHz)
-
IQR: interquantile range (in kHz)
-
skew: skewness (see note in specprop description)
-
kurt: kurtosis (see note in specprop description)
-
label: The label of each track: male/female
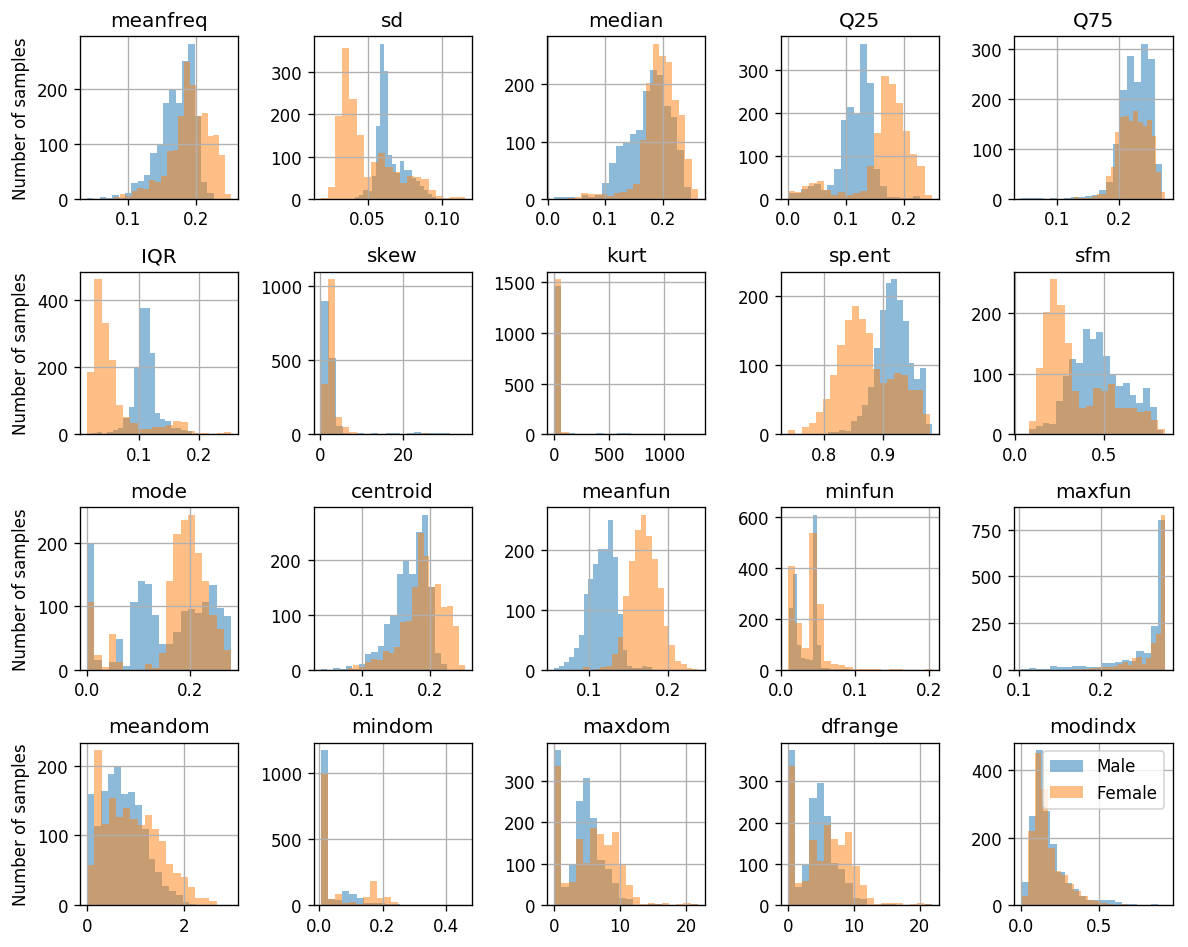
📉 סטטיסטיקה של ה- Data
מספר הנשים והגברים ב- Data
היסטוגרמות של הערכים השונים:
📜 הגדרת הבעיה
-
דגימת קול אקראית -
-
משתנים אקראיים:
-
: רשימה של ערכים שהוצאו עבור דגימת הקול.
-
: מין הדובר: עבור נקבה, עבור זכר
-
הריסק שלנו היינו - Misclassification
💡 שיטת הלימוד: Soft-SVM
- נשתמש בחבילת האופטימיזציה הקונבקסית cvxpy על מנת לפתור את בעיית האופטימיזציה של SVM.
פרמטרים:
הפרמטרים הנלמדים המודל הינם ו- או במקרה שנפתור את הבעיה הדואלית.
היפר-פרמטרים:
ההיפר-פרמטר היחיד בבעיית ה- Soft-SVM הינו פרמטר העונש , שמגדיר מה העונש על הפרת האילוצים.
עיבוד מקדים
📚 א) פיצול ה- Data
-
סט אימון - 60%
-
סט וולידציה - 20%
-
סט בוחן - 20%
📚 ב) נרמול ה- Data
חשוב לנרמל את ה- Data לפני הרצת האלגוריתם, משתי סיבות עיקריות:
-
ה- Data מתאר מאפיינים ביחידות וסקלות שונות.
-
האלגוריתם מנסה למזער את Objective אשר מבוסס מרחק, מה שהופך אותו לרגיש ביחס למרחק לכל כיוון.
- לדוגמא, אם נכפיל מאפיין מסויים בערך קבוע גדול מ-1, למעשה ניתן לו חשיבות יתרה ב- Objective.
⚙️ שלב הלמידה - הבעייה הדואלית
- ראשית, נפתור את הבעיה הדואלית:
- נתחיל עם ולאחר מכן ננסה לכוונן היפר-פרמטר זה.
נצייר את ערך לכל אחת מהדוגמאות
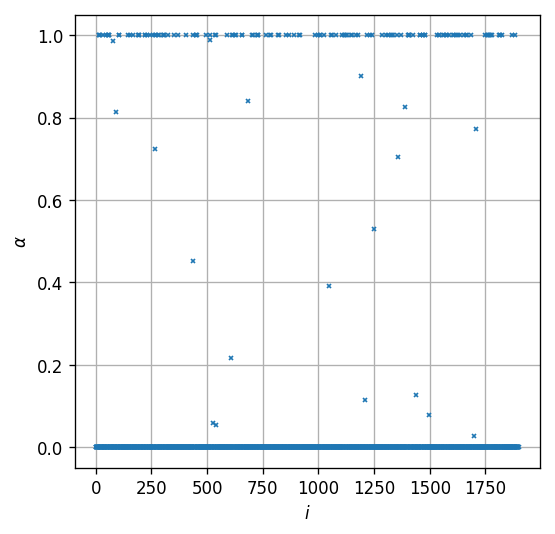
כצפוי, קיבלנו 3 סוגי ערכים: , ו- . ערכים אלה מתאימים למצבים הבאים:
- : דוגמאות שסווגו נכונה ורחוקות מה- Margin:
- : דוגמאות שיושבות בדיוק על ה- Margin:
- : נקודות שסווגו באופן לא נכון (בצד הלא נכון של מישורה הפרדה) או סווגו בצורה נכונה אבל יושבות בתוך ה- Margin:
כעת, ניתן להשתמש בנוסחא שנלמדה על מנת לחשב את ו- :
את ניתן לחשב על ידי לבחור נקודה שעבורה ולהשתמש במשוואה: .
ההיסטוגרמה של התיוגים של כל הנקודות
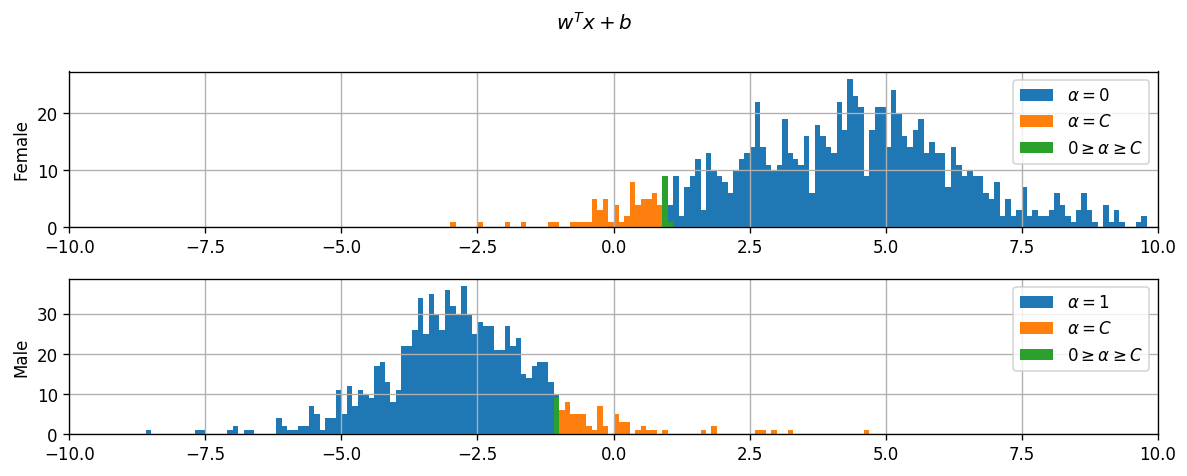
- הצבעים מייצגים את 3 המקרים לעיל.
הסיכון שהתקבל על סט הבוחן הינו:
⚙️ שלב הלמידה - הבעייה הפרימאלית
כתרגיל, ננסה גם לפתור את הבעיה הפרימאלית ישירות ונשווה בין הפתרונות:
The first 10 values if w in the primal problem are:
[ 0.32403667 -0.13227075 -0.06096529 0.41782102 -0.48840472]
The first 10 values if w in the dual problem are:
[ 0.32138073 -0.13206916 -0.05900207 0.4178552 -0.48799808]
The b value of the primal problem is: 0.6602256435596877
The b value of the dual problem is: 0.658170109096357
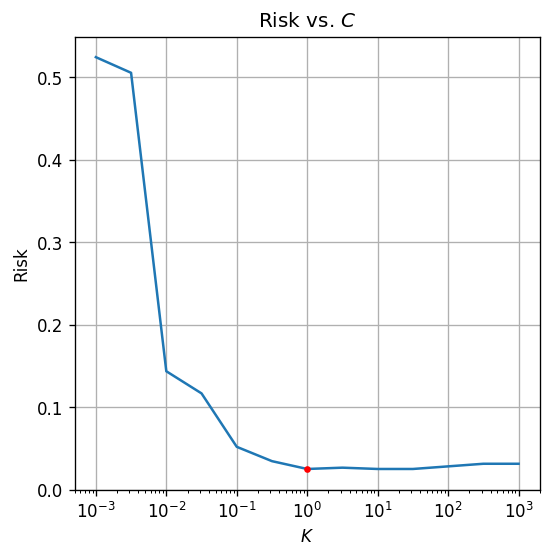
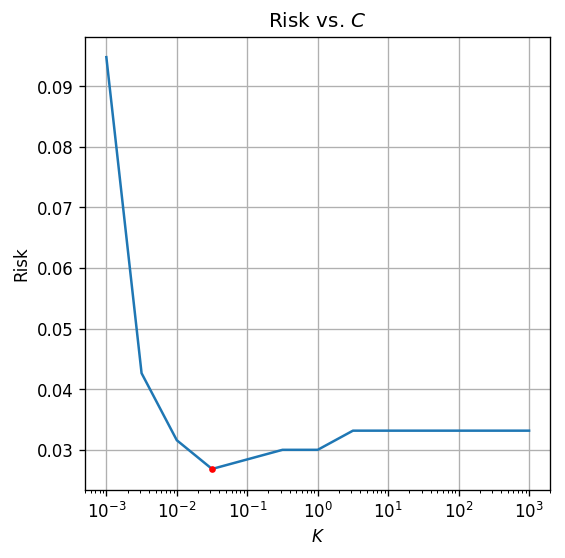
בחירת מודל - כיוונון היפר פרמטרים
-
כעת, ננסה לבחור את ההיפר-פרמטר .
-
נסתכל על ערכים בטווח - ונשווה את התוצאות על סט האימות
-
ה- האופטימלי הינו
-
הסיכון שהתקבל על סט הבוחן הינו:
שימוש בפונקציית גרעין:
- נשתמש בפורמולצייה של הבעייה הדואלית:
- ניתן להחליף את המכפלה הפנימית בפונקציית גרעין.
- החלפנו את פונקציית הגרעין בגרעין פופולרי המכונה Radial Basis Function.
ה- האופטימלי שהתקבל הינו .
הסיכון על סט הבוחן הינו: