תיאוריה
Artificial Neural Networks (ANN)
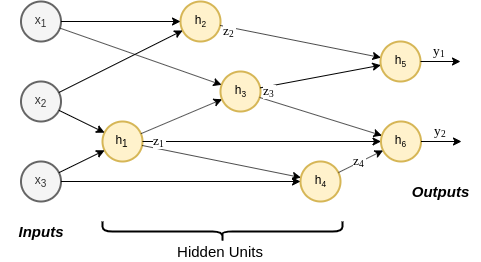
- בנויות בהשראת רשתות נוירונים ביולוגיות.
- בנויות כאוסף של יחידות אשר מבצעות כל אחת פעולה מתימטית פשוטה.
- יחידות אלו מכונות לרוב נוירונים מלאכותיים.
Artificial Neural Networks (ANN) - המשך
לרוב, נוירונים יבצעו את הפועלה של:
- קומבינציה לינארית של הכניסות לנוירון והוספת קבוע (bias).
- הפעלה של פונקציה סקלארית לא לינארית. (פונקציית הפעלה)
פונקציית ההפעלה נפוצות:
- הפונקציה הלוגיסטית (sigmoid):
- טנגנס היפרבולי:
- ReLU (Rectified Linear Unit):
אלא אם צויין אחרת, אנו נניח כי הנויירונים ברשת בנויים בצורה זו.
Artificial Neural Networks (ANN) - המשך 2
מושגים:
- יחידות נסתרות (hidden units): הנוירונים אשר אינם מחוברים למוצא הרשת.
- רשת עמוקה (deep network): רשת בעלת מסלולים עם יותר מיחידה נסתרת אחת.
- ארכיטקטורה: הצורה שבה הנוירונים מחוברים בתוך הרשת.
Artificial Neural Networks (ANN) - המשך 3
סוגי ארכיטקטורות:
- רשת הזנה קדמית (Feed-forward networks): רשת אשר אינה מכילה מסלולים מעגליים (המידע זורם מהכניסה למוצא).
- רשתות נשנות (recurrent networks): ארכיטקטורות אשר מכילות מסלולים מעגליים. בקורס זה לא נעסוק ברשתות מסוג זה.
אנו נשתמש ברשתות אלו כמודל, ונאמן אותן בעזרת אלגוריתם הגרדיאנט ושיטה המכונה back-propagation.
Multilayer Perceptron (MLP)
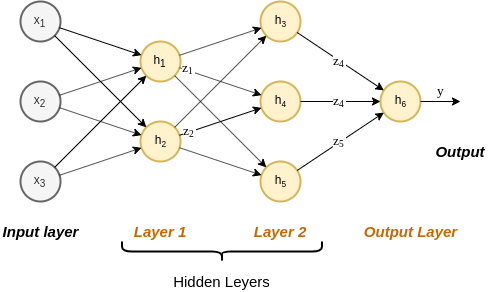
- אחת הארכיטקטורות הפשוטות ביותר הנמצאות בשימוש.
- הנוירונים מסודרים בשתייים או יותר שכבות (layers) (שכבת הכניסה לא נספרת).
- כל נוירון מוזן מכל הנוריונים שבשכבה שלפניו. (fully connected leyers)
Multilayer Perceptron (MLP) - המשך
Hyperparameters:
- מספר השכבות
- מספר הנוירונים בכל שכבה
- פונקציית האקטיבציה
פרמטרים:
- המשקולות ואברי הbias בקומבינציה הלניארית.
הערה חשובה!!!!
בבואנו להשתמש בארגוריתם הגרדיאנט אנו נהיה מעוניינים בחישוב הנגזרת של פונקציית ההפסד/סיכון על פי הפרמטרים של הרשת (ולא על פי התצפיות ).
הערה נוספת לגבי שמות
- במתמטיקה ובdeep learning השם loss function מתאר פונקציה כל שהיא שאותה אנו רוצים למזער (ולא בהכרח ה”כנס” על שגיאת החיזוי)
- במתמטיקה sigmoid מתייחס לאוסף רחב של פונקצייות בעלות צורת S, בהקשר של deep learning, שם זה מתייחס לרוב לפונקציה הלוגיסטית.
Back-Propagation
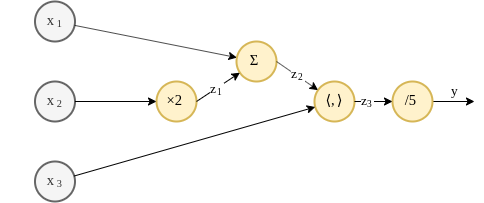
ייצוג פונקציה גרף - דוגמא
לשם המחשה, נסתכל על הפונקציה הבאה:
ניתן לייצג פונקציה זו כגרף באופן הבא:
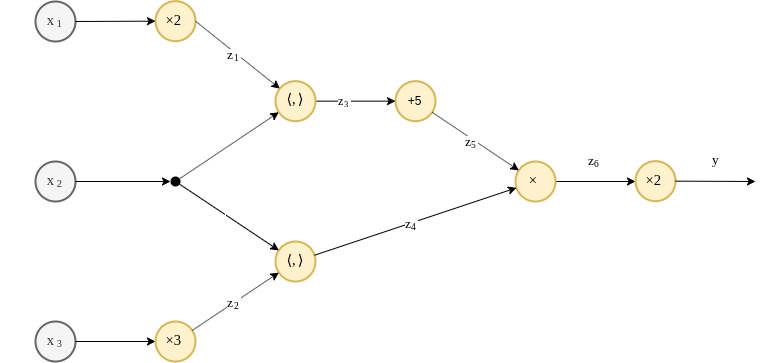
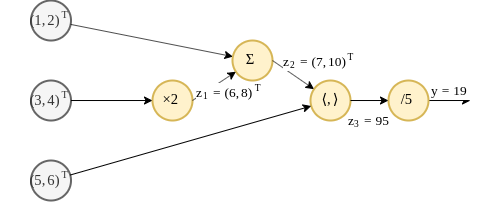
ייצוג פונקציה גרף - דוגמא - המשך
נחשב את מוצא הרשת בעבור הכניסות הבאות:
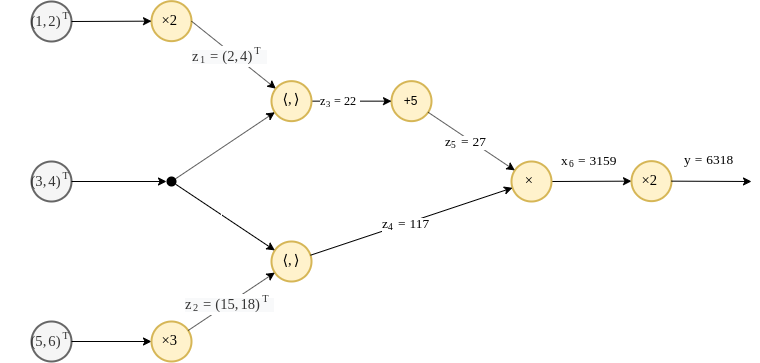
תהליך זה מוכנה הforwad pass
חישוב הנגזרות בעזרת הגרף
נשתמש בכלל השרשרת על מנת לרשום את הנגזרת של המוצא על פי הכניסות:
חישוב הנגזרות בעזרת הגרף - המשך
או באופן גרפי:
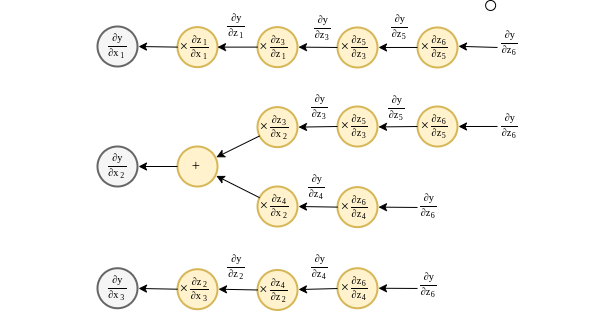
חישוב הנגזרות בעזרת הגרף - המשך 2
נאחד את כל החישובים הזהים:
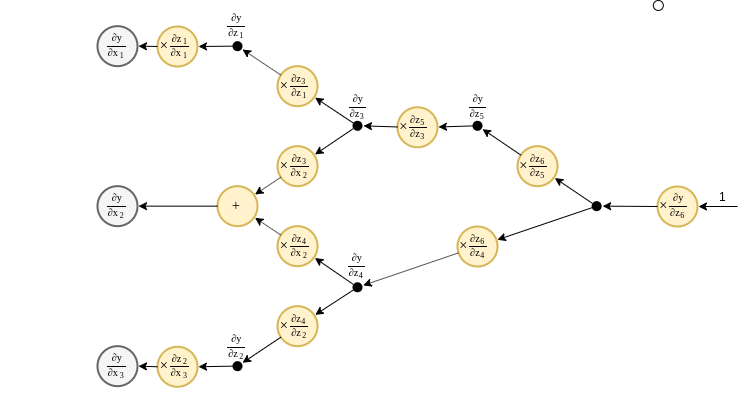
חישוב הנגזרות בעזרת הגרף - המשך 3
לשני הגרפים צורה זהה אך כיוון החישוב בהם הינו הפוך.
חישוב הנגזרות בעזרת הגרף - המשך 3
ניתן להפוך כל גרף של פונקציה להגרף של הנגזרת שלו באופן הבא:
- הופכים את כיוון הזרימה בגרף
- מוסיפים כפל בנגזרת לכל יציאה מייחידת חישוב.
- את יחידות החישוב המקוריות מחליפים בפעולת סכימה על הכניסות.
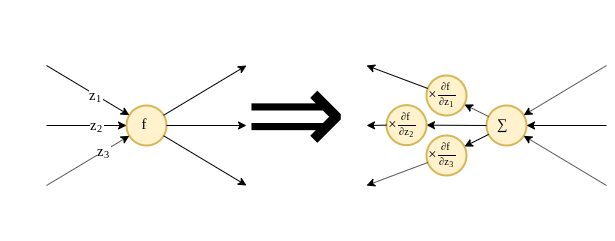
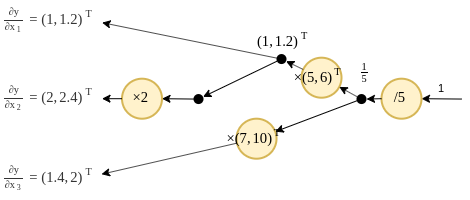
חישוב הנגזרות בעזרת הגרף - המשך 4
נחשב כעת את הנגזרות ונציב אותם לגרף:
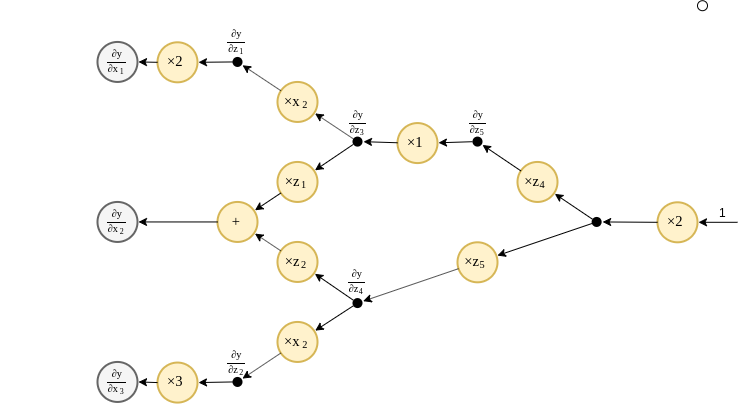
- בגרף המתקבל מופיעים הערכים של המשתנים .
- על מנת לחשב את הנגזרות עלינו לחשב את הערכים המקבלים בגרף המקורי.
- החישוב של הפונקציה המקורית נקרא הforward pass.
- החישוב של הנגזרות מתוך הגרך ההפוך נקרא הbackward pass.
תרגילים
תרגיל 9.1 - Back propagation
נתונה הפונקציה הבאה:
שרטטו את הפונקציה כגרף המורכב מיחידות המבצעות פעולות פשוטות (חיבור וקטורים, מכפלה וקטורית וכפל בסקלר). שרטטו את הגרף של הפונקציה עצמה ואת הגרף של הנגזרת . חשבו את הforward והbackward pass בעבור ערכי הכניסה הבאים:
פתרון
גרף הפונקציה:
פתרון - המשך
גרף הנגזרת:

פתרון - המשך 2
Forward pass:
פתרון - המשך 3
Backward pass:
תרגיל 9.2 - Back propagation in MLP
נתונה רשת מסוג MLP בעלת שתי כניסות, , שכבה נסתרת אחת המכילה 2 נוירונים ושתי יציאות . פונקציית האקטיבציה ברשת זו הינה הפונקציה הלוגיסטית (). בנוסף נתון כי כל נוירונים בכל שכבה חולקים את אותו רכיב bias.
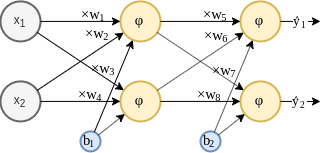
נרצה ללמד רשת זו בעזרת אלגוריתם הגרדיאנט ופונקציית הפסד מסוג : , כאשר .
תרגיל 9.2 - Back propagation in MLP
בעבור ערך התצפית והתוויות , השתמש בשיטת הback propagation על מנת לחשב את הגרדיאנט המקבל בעבור פרמטרי הרשת הבאים:
פתרון
גרף הפונקציה המלא, הכולל גם את פונקציית ההפסד נראה כך:
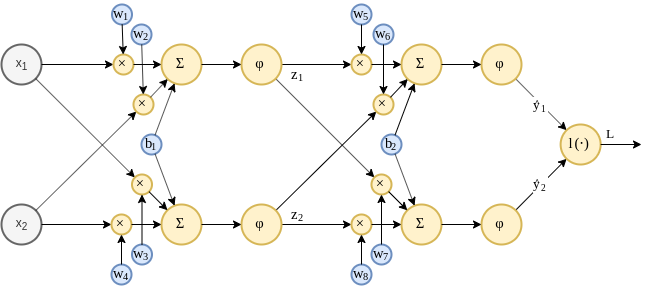
נזכיר כי אנו מעוניינים לחשב את הגרדיאנט בין המוצא, המסומן כ לכל אחת מעשרת פרמטרי הרשת.
פתרון - המשך
- נבנה את הגרף לחישוב הנגזרת על פי העקרונות ממקודם.
- בעבור הפונקציה הלוגיסטית מתקיים:
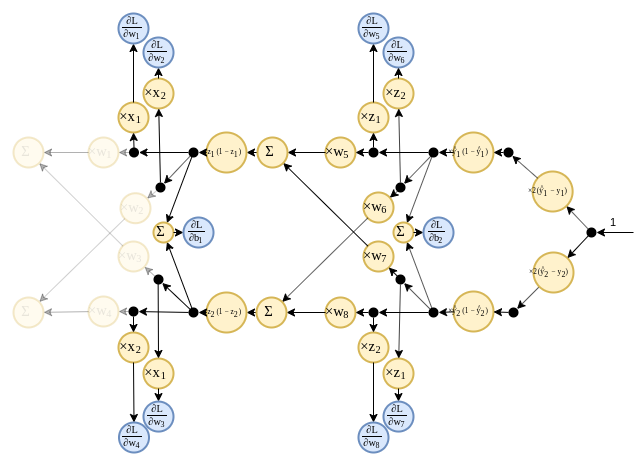
פתרון - המשך 2
נחשב ראשית את הforward pass:
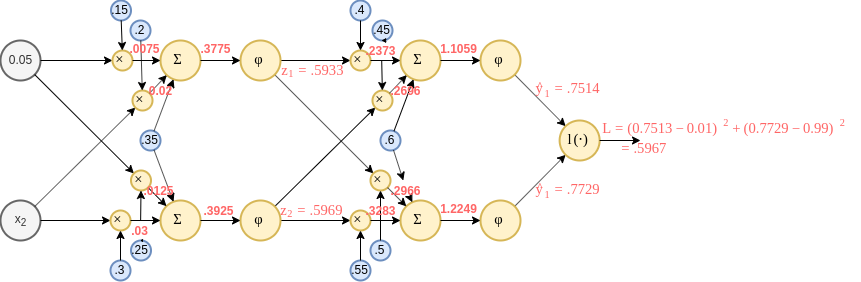
פתרון - המשך 3
וכעת את הbackward pass:
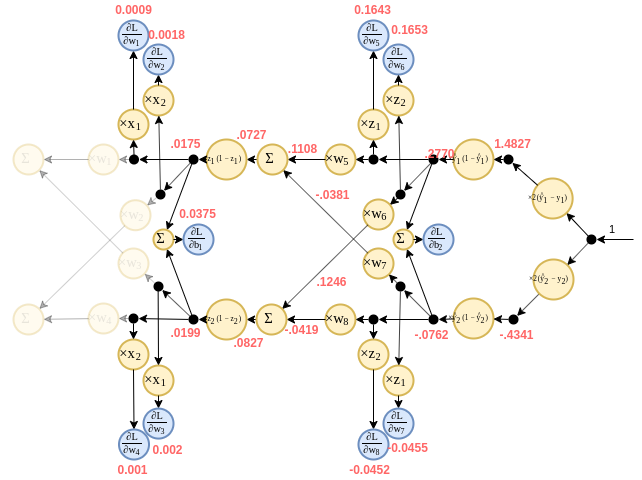
תרגיל 9.3 - משפט הקירוב האוניברסלי
א) הראו כיצד ניתן לייצג את הפונקציה הבאה בעזרת רשת feedforward המכילה מנוירונים בעלי פונקציית הפעלה מסוג ReLU, . שרטטו את הרשת ורשמו את הערכים של פרמטרי הרשת.
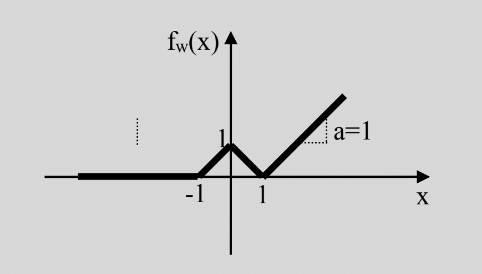
ב) האם ניתן לייצג במדוייק את הפונקציה בעזרת רשת feedforward המכילה מנוירונים בעלי פונקציית הפעלה מסוג ReLU בלבד? הסבירו ו/או הדגימו.
פתרון - א
בעזרת נויירונים בעלי פונקציית אקטיבציה מסוג ReLU נוכל לבנות פונקציות רציפות ולינאריות למקוטעין, בעלות מספר סופי של קטעים, כמו זו בשבשאלה זו.
- נשתמש בMLP בעל שיכבה נסתרת אחת
- השכבה הנסתרת תדאג לחלוקה למקטעים.
- שכבת המוצא תדאג לשיפועים.
פתרון - א - המשך
נשתמש במספר נויירונים כמספר המקומות בהם הפונקציה משנה את השיפוע שלה, ונתאים את השבירה של הReLU לנקודות אלו בעזרת רכיב הbias:
פתרון - א - המשך 2
נדאג לשיפועים משמאל לימין:
- המקטע השמאלי ביותר הינו בעל שיפוע 0 ולכן הוא כבר מסודר.
- המקטע מושפע רק מן הנוירון הראשון. השיפוע במקטע זה הינו 1 ולכן ניתן משקל של 1 לנירון זה.
- המקטע מושפע משני הנוירונים הראשונים. הנוירון הראשון כבר תורם שיפוע של 1 במקטע זה ולכן עלינו להוסיף לו עוד שיפוע של על מנת לקבל את השיפוע של הנדרש. ולכן ניתן משקל של לנירון השני.
- באופן דומה ניתן לנוירון השלישי משקל של .
פתרון - א - המשך 2
סה”כ קיבלנו:
פתרון - ב
מכיוון ש:
- נוירון בעל פונקציית הפעלה מסוג ReLU מייצג פונקציה רציפה ולינארית למקוטעין.
- כל הרכבה או סכימה של פונקציות רציפות ולינאריות למקוטעין יצרו תמיד פונקציה חדשה שגם היא רציפה ולינארית למקוטעין.
בעזרת נוירונים מסוג ReLU נוכל רק לייצג פונקציות רציפות ולנאריות למקוטעין.
מכיוון ש אינה לינארית אנו נוכל רק לקרב אותה, אך לא לייצג אותה במדוייק.
בעיה מעשית
סביבות פיתוח - Deep Learning Frameworks
ספיריות (או toolboxs) בעבור שפות תכנות קיימת אשר מפשטות מאד את תהליך הפיתוח של מערכות המבוססות על רשתות נוירונים. הן לרוב מציעות יכולות כגון:
- מימוש של מגוון פונקציות נפוצות כגון פונקציות אקטיבציה וכלים לבניית רשתות.
- ביצוע back propagation באופן אוטומטי.
- הרצת אלגוריתמי גרדינאט מתוחכמים.
- הרצת הרשתות והאופטימיזציה על GPU לשם האצה.
סביבות פיתוח - Deep Learning Frameworks - המשך
רשימה חלקית של סביבות שכאלה:
-
TensorFlow: סיפריית Python. פותחה ומתוחזקת על ידי Google. כיום סביבת הפיתוח הפופולרית ביותר.
-
PyTorch: ספריית Python. מבוססת על ספריה הנקראת Torch אשר נכתבה לLUA. מפותחת ומתוחזקת על ידי Facebook. יותר צעירה וצוברת פופולריות. כיום פופולרית כמעט כמו TensorFlow.
-
Caffe & Caffe2: ספריה ישנה יותר. בעלת תמיכה ב C, C++, Pyhton ו Matlab. פותחה במקור בBerkley וכיום מתוחזקת על ידי פייסבוק. הפופולריות של ספריה זו הולך ופוחת בשנים האחרונות.
-
Keras: ספריית Python אשר נבנתה על גבי ספריות אחרות כגון TensorFlow ומציעה ממשק יותר “ידידותי”, אך מאפשרת פחות שליטה.
-
fast.ai: חדשה יחסית. עוטפת את PyTorch ומציעה יכולות נוספות והגדרות ברירת מחדל טובות יותר. קיבלה תגובות חיוביות רבות ומתחילה לצבור פופולריות.
-
Matlab: לאחרונה, פרסמה MathWorks (החברה שכותבת את Matlab) Toolbox לעבודה עם רשתות ניורונים.
PyTorch - Logistic Regression
בתרגול הקודם פתרנו את בעיית סיווג התאים הסרטניים בעזרת מודל של linear logistic regression.
נשחזר כעת פיתרון זה על ידי שימוש בPyTorch, ולאחר מכן נרחיב את הפתרון למודל של MLP.
PyTorch - Logistic Regression - המשך
בPyTorch בונים מודלים על ידי הגדרה של class חדש.
הרשת הנל מתארת מודל linear logistic regresion (קומבינציה לינארית של 2 משתני כניסה, אשר מוזנים לsigmoid):
## Defining the network
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__() ## Ignore this line for now
## Defining some objects which will be used in the forward function.
self.linear = torch.nn.Linear(2, 1) ## A linear model with input of 2 and output of 1.
self.sigmoid = torch.nn.Sigmoid() ## A sigmoid function
def forward(self, x):
## The function which defines the forward pass.
x = self.linear(x)
x = self.sigmoid(x)
return x
- torch.nn.Model: מודל בסיס שממנו יש לרשת בבניה של מודלים חדשים.
- torch.nn.Linear: אובייקט אשר מבצע טרנספורמציה לינארית (אפינית).
- torch.nn.Sigmoid אובייקט הממש את פונקציית sigmoid.
PyTorch - Logistic Regression - המשך 2
הקוד הבא עושה שימוש ברשת אשר הוגדרה לעיל, ומאמן אותה על מדגם נתון:
def basic_gradient_decent(net, alpha, tol, max_iter, x_train, y_train):
## Set the loss function
loss_func = torch.nn.BCELoss()
## Initizalie the optimizer
opt = torch.optim.SGD(net.parameters(), lr=alpha)
last_objective = None
objective = None
while (last_objective is None) or (torch.abs(objective - last_objective) < tol) or (i_iter == max_iter):
last_objective = objective
opt.zero_grad()
prob = net(x_train) ## Forward pass
objective = loss_func(prob, y_train.float()) ## Loss calculation
objective.backward() ## Backward pass
opt.step() ## Perform the update step
tol = 1e-7
max_iter = 100000
alpha = 1e-2 ## Learning Rate
net = Net()
basic_gradient_decent(net, alpha, tol, max_iter, x_train, y_train)
PyTorch - Logistic Regression - המשך 3
-
האובייקט של torch.nn.BCELoss BCELoss מגדיר loss באופן הבא:
והוא שקול לפתרון המתקבל בשיטת MLE.
- האובייקט של torch.optim.SGD מגדיר את אלגוריתם האופטמיזציה ומקבל באיתחול את רשימת הפרמטרים שעליהם מבוצעת האופטימיזציה.
תוצאה
הסיכון המשוערך על סט הבחן הינו: 0.097.
הגרף של פונקציית המטרה של האופטימיציזה כפונקציה של מספר האיטרציה הינו:
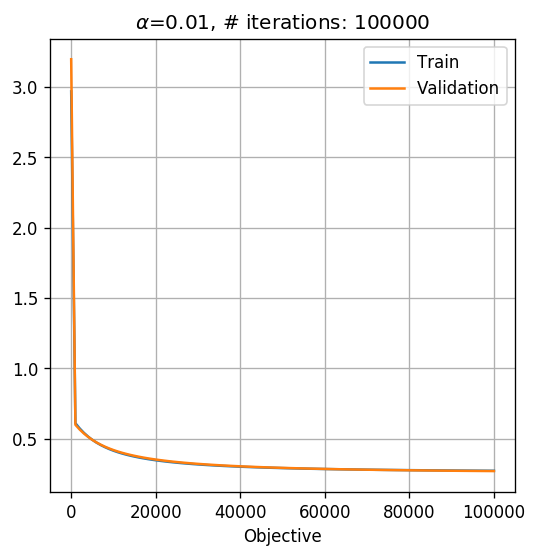
MLP
ניתן כעת בקלות להרחיב מודל זה לMLP פשוט על ידי הוספה של שכבות נוספות.
נוסיף שכבה מוספת של 2 נוירונים:
class NetMLP(nn.Module):
def __init__(self):
super(NetMLP, self).__init__()
self.linear1 = nn.Linear(2, 2) ## input: 2 feature, output: 2 features
self.linear2 = nn.Linear(2, 1) ## input: n_units_in_hidden, output: 1
self.sigmoid = nn.Sigmoid() ## A sigmoid function
torch.random.manual_seed(0)
torch.nn.init.normal_(self.linear1.weight)
torch.nn.init.normal_(self.linear2.weight)
def forward(self, x):
x = self.linear1(x)
x = self.sigmoid(x)
x = self.linear2(x)
x = self.sigmoid(x)
return x
תוצאה
הסיכון המשוערך על סט הבחן הינו: 0.07.
הגרף האופטימיזציה נראה כך:

כלל החלטה נראה כך:
