בעיית חיזוי - תזכורת
- - התצפיות/המדידות משתנה/וקטור אקראי אשר יש באפשרותינו למדוד.
- - התויות. משתנה אקראי אשר ברצונינו לחזות על סמך .
- - פונקציית חיזוי של כתלות ב.
- - פונקציית הפסד. ה”קנס” המתקבל בעבור חיזוי שגוי.
- - פנקציית הסיכון. התוחלת של ההפסד.
המטרה: למצוא פונקציית חיזוי אופטימאלית:
בעיית חיזוי - תזכורת - המשך
אנו מבחינים בין שני סוגי בעיות חיזוי:
- סיווג: כאשר תחום הערכים של התוויות הינו דיסקרטי וסופי.
- רגרסיה: כאשר תחום הערכים של התוויות הינו תחום רציף.
פונקציות הפסד נפוצות
הפסד אפס-אחד (zero-one loss)
- ההפסד הנפוץ בבעיות סיווג.
- פונקציית הסיכון שלו נקראת: misclassification rate
- החזאי האופטימאלי תחת הפסד זה הינו:
הפסד מרחק ריבועי ( loss)
- ההפסד הנפוץ בבעיות רגרסיה.
- פונקציית הסיכון שלו נקראת: Mean Square Error (MSE)
- החזאי האופטימאלי תחת הפסד זה הינו משערך התוחלת המותנית:
למידה מודרכת
- בבעיות חיזוי שבהם אין אנו יודעים את הפילוג המשותף של ו
- יש ברשותינו מדגם של דיגימות משותפות שלהם:
גישה גנרטיבית
- נשתמש במדגם על מנת לשערך את פונקציית הפילוג המשותפת
- ובעזרת הפילוג המשותף נבנה את החזאי.
(שיטות אלו נקראות גנרטיביות משום שהם מנסות ללמוד את האופן שבו נוצר (generated) המדגם)
גישה גנרטיבית - המשך
נפרק לרוב את הפונקציית הצפיפות המושתפת באופן הבא:
- בבעיות סיווג דיסקרטי וסופי.
ניתן לשערך אותו על פי: - את נשערך בנפרד בעבור כל ערך של .
זאת אומרת שאת נשערך מתוך אוסף דגמים שמקיימות .
שיטות הסיווג הגנרטיביות נבדלות במודל של , ואופן הלימוד שלו.
מסווג בייס נאיבי (Naïve Bayse Classifier)
ההנחה: הרכיבים של הינם בלתי תלויים סטטיסטית.
תחת הנחה זו:
את משערכים בעבור כל וכל .
- שיטה זו לא מגדירה כיצד ללמוד את הפילוגים החד מימדיים.
- שיטה זו פותרת את בעיית הCurse of Dimenionality.
- הנחת החוסר תלות בין הרכיבים לרוב רחוקה מלהיות נכונה.
Linear Discriminant Analysis (LDA)
הנחות:
- מפולגים נורמאלית.
- לכל הפילוגים אותה מטריצת covariance.
נניח כי מקבל את סט הערכים , ונשתמש בסימונים הבאים:
- - תת-המדגם המקיים .
- - התוחלות של הפילוגים הנורמאלים.
- - מטריצת הcovariance של הפילוגים. (מטריצה אחת בעבור כל ה פילוגים).
שיערוך MLE של פרמטרי המודלים נותן:
Linear Discriminant Analysis (LDA) - המשך
הפרדה לינארית
בעבור המקרה של סיווג בינארי (סיווג לשני מחלקות) וzero-one loss מתקבל:
כאשר:
נשים לב כי תנאי ההחלטה שבין שני התחומים הינו לינארי, ומכאן מקבל האלגוריתמם את שמו
Quadric Discriminant Analysis (QDA)
הנחות:
- הפילוגים הינם פילוגים נורמאלייים לכל ערך של .
QDA דומה מאד לLDA רק ללא ההנחה השניה.
משערך MLE נותן:
(כעת יש בעבור כל ערך של , והוא מחושב על פי תת-המדגם המתאים.
משטח הפרדה ריבועי
בעבור המקרה של סיווג בינארי (סיווג לשני מחלקות) וzero-one loss מתקבל:
כאשר:
במקרה זה, משטח ההפרדה נתון על ידי פונקציה ריבועית ומכאן האלגוריתם מקבל את שמו.
תרגיל 6.1 - MAP
ביום טוב, עומרי כספי קולע בהסתברות מהקו. ביום רע, הוא קולע בהסתברות מהקו. מהימים הם ימים טובים עבור עומרי.
ביום מסויים זרק עומרי זריקות וקלע מתוכם. מאמנו של עומרי צריך לזהות האם מדובר ביום טוב או רע של השחקן (ולהשאיר אותו או להחליף אותו בהתאמה).
מהו חוק ההחלטה אשר ממקסם את סיכויי המאמן לצדוק?
הניחו כי בהינתן המידע של האם יום מסויים הוא טוב או לא, ההסברות לקלוע זריקות שונות הינה הסתברות בלתי תלויה.
תרגיל 6.1 - MAP - פתרון
נגדיר את המשתנים האקראיים והפילוגים שלהם:
- - האם קלע או לא. (0-החטיא, 1-קלע)
- - האם יום טוב או לא. (0-יום לא טוב, 1-יום טוב).
על פי הנתונים בשאלה:
תרגיל 6.1 - MAP - פתרון - המשך
- בעיית MAP
- פרמטר בפילוג .
- החזאי האופטימאלי של הינו:
בעבור נקבל:
בעבור נקבל:
תרגיל 6.1 - MAP - פתרון - המשך 2
בעבור נקבל:
בעבור נקבל:
לכן החיזוי האופטימאלי יהיה:
תרגיל 6.2
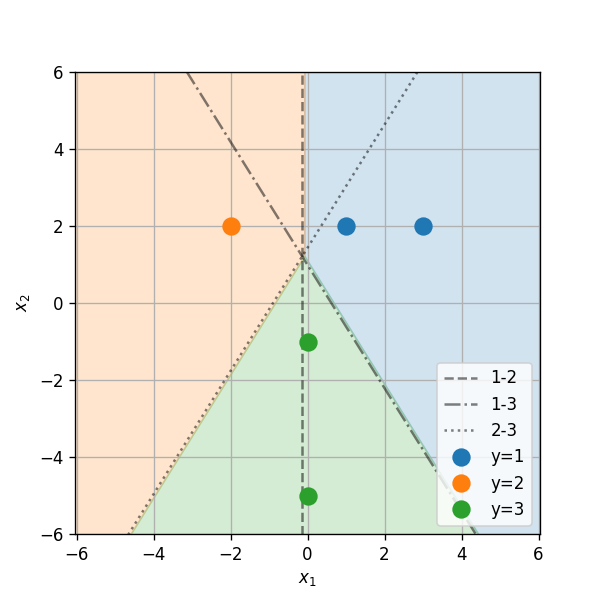
בסוואנה חיים שלושה זני פילים אשר נמצאים בסכנת הכחדה. ידוע כי כל אחד משלושת הזנים ניזון מצמחיה מעט שונה ועל מנת לשמר את אוכלוסיית הפילים מעוניינים לפזר להם אוכל ברחבי הסוואנה. בכדי למקסם את האפקטיביות של פעולה זו מעוניינים לשערך בכל נקודת חלוקה מהו הזן שהכי סביר להמצא באותה נקודה על מנת להתאים את סוג המזון לזן זה.
הפילוג של זני הפילים על פני הסוואנה אינו ידוע אך נתונות לנו התצפית הבאה של הקואורדינטות בהם נצפו הפילים:
| Type | X_1 | X_2 |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 3 | 2 |
| 2 | -2 | 2 |
| 3 | 0 | -1 |
| 3 | 0 | -5 |
השתמש במסווג LDA על מנת לבנות חזאי אשר ישערך את הזן הזפוץ ביותר בכל קואורדינטה.
תרגיל 6.2 - פתרון
| Type | X_1 | X_2 |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 3 | 2 |
| 2 | -2 | 2 |
| 3 | 0 | -1 |
| 3 | 0 | -5 |
סימונים:
- הקאורדינטה. לדוגמא:
- הזן. לדוגמא:
- אוסף כל התצפיות של שבהם הזן הוא . לדוגמא:
תרגיל 6.2 - פתרון - המשך
| Type | X_1 | X_2 |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 3 | 2 |
| 2 | -2 | 2 |
| 3 | 0 | -1 |
| 3 | 0 | -5 |
נחשב את הפילוג הא-פריורי של כל אחד מן הזנים:
תרגיל 6.2 - פתרון - המשך 2
| Type | X_1 | X_2 |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 3 | 2 |
| 2 | -2 | 2 |
| 3 | 0 | -1 |
| 3 | 0 | -5 |
נחשב את הפרמטרים של שלושת הפילוגים הנורמאלים:
תרגיל 6.2 - פתרון - המשך 3
נחשב את מטריצת covariance המשותפת של הפילוגים:
דרך נוחה לחשב את הסכום בביטוי זה הינה באופן הבא. נגדיר את המטריצה של התצפיות לאחר חיסור של התוחלת המתאימה לכל זן:
תרגיל 6.2 - פתרון - המשך 4
ניתן להראות בקלות כי ניתן לכתוב את הסכום בביטוי ל באופן הבא:
תרגיל 6.2 - פתרון - המשך 5
נשתמש כעת בפילוגים שאותם שיערכנו על מנת לבנות את החזאי. האיזור שבו זן 1 הינו הזן הסביר ביותר הינו האיזור שבו מתקיים:
נחשב את התנאי הראשון
תרגיל 6.2 - פתרון - המשך 6
זוהי למעשה הפרדה לשני תחומים על ידי הקו הבא:
כאשר:
מכאן שהקו המפריד בין זן 1 ל זן 2 נתון על ידי:
תרגיל 6.2 - פתרון - המשך 7
באופן דומה ניתן לחשב גם את שני קווי ההפרדה האחרים (בין 1 ל 3 ובין 2 ל 3):
בעיה מעשית
המדגם: Breast Cancer Wisconsin
נעבוד שוב עם המדגם של דגימות התא לאבחון סרטן שד. (את המדגם המקורי ניתן למצוא פה, בקורס נעבוד עם הגרסא הזו)
השדות במדגם
להלן 10 השורות הראשונות במדגם:
| id | diagnosis | radius_mean | texture_mean | perimeter_mean | area_mean | smoothness_mean | compactness_mean | concavity_mean | concave points_mean | ... | radius_worst | texture_worst | perimeter_worst | area_worst | smoothness_worst | compactness_worst | concavity_worst | concave points_worst | symmetry_worst | fractal_dimension_worst | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 842302 | M | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.30010 | 0.14710 | ... | 25.38 | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 |
| 1 | 842517 | M | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.08690 | 0.07017 | ... | 24.99 | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 |
| 2 | 84300903 | M | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.19740 | 0.12790 | ... | 23.57 | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 |
| 3 | 84348301 | M | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.24140 | 0.10520 | ... | 14.91 | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 |
| 4 | 84358402 | M | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.19800 | 0.10430 | ... | 22.54 | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 |
| 5 | 843786 | M | 12.45 | 15.70 | 82.57 | 477.1 | 0.12780 | 0.17000 | 0.15780 | 0.08089 | ... | 15.47 | 23.75 | 103.40 | 741.6 | 0.1791 | 0.5249 | 0.5355 | 0.1741 | 0.3985 | 0.12440 |
| 6 | 844359 | M | 18.25 | 19.98 | 119.60 | 1040.0 | 0.09463 | 0.10900 | 0.11270 | 0.07400 | ... | 22.88 | 27.66 | 153.20 | 1606.0 | 0.1442 | 0.2576 | 0.3784 | 0.1932 | 0.3063 | 0.08368 |
| 7 | 84458202 | M | 13.71 | 20.83 | 90.20 | 577.9 | 0.11890 | 0.16450 | 0.09366 | 0.05985 | ... | 17.06 | 28.14 | 110.60 | 897.0 | 0.1654 | 0.3682 | 0.2678 | 0.1556 | 0.3196 | 0.11510 |
| 8 | 844981 | M | 13.00 | 21.82 | 87.50 | 519.8 | 0.12730 | 0.19320 | 0.18590 | 0.09353 | ... | 15.49 | 30.73 | 106.20 | 739.3 | 0.1703 | 0.5401 | 0.5390 | 0.2060 | 0.4378 | 0.10720 |
| 9 | 84501001 | M | 12.46 | 24.04 | 83.97 | 475.9 | 0.11860 | 0.23960 | 0.22730 | 0.08543 | ... | 15.09 | 40.68 | 97.65 | 711.4 | 0.1853 | 1.0580 | 1.1050 | 0.2210 | 0.4366 | 0.20750 |
במדגם 569 שורות (דגימות).
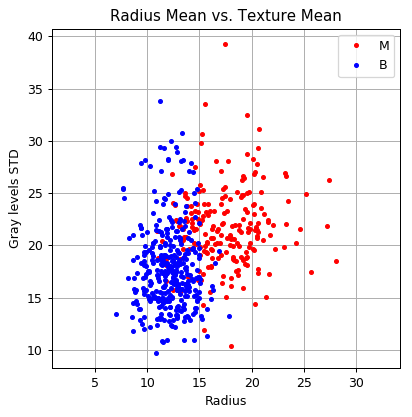
לשם הפשטות (וויזואליזציה) אנו נעבוד תחילה רק עם התווית ושני השדות הבאים:
- diagnosis - התווית של הדגימה: M = malignant (סרטני), B = benign (בריא)
- radius_mean - רדיוס התא הממוצע בדגימה
- texture_mean - סטיית התקן הממוצעת של רמת האפור בצבע של כל תא בדגימה.
(בהמשך נעבוד עם יתר השדות)
השדות במדגם - המשך
הפילוג של נתונים אלו נראה כך:
תזכורת לבעיה: חיזוי האם תא הינו סרטני או לא
אנו מעוניינים לעזור לצוות הרפואי לבצע אבחון נכון של דגימות לדגימות סרטניות (malignant) או בריאות (benign) על סמך הנתונים המספריים שמחושבים לכל דגימה.
באופן פורמאלי:
- - ערכי התצפית של דגימה מסויימת.
- - התווית הבינארית של האם הדגימה סרטנית או לא. (0-בריא, 1-סרטני)
נהיה מעוניינים למצוא את פונקציית החיזוי אשר ממזערת את:
(zero-one loss)
הפרשה של סט בחן
- לשם שיערוך ביצועיו של החזאי נפריש 20% מהמדגם לסט בחן (test set).
(במודלים שאיתם נעבוד בתרגול זה אין hyper-parameters ולכן לא יהיה לנו צורך בסט אימות (validataion set))
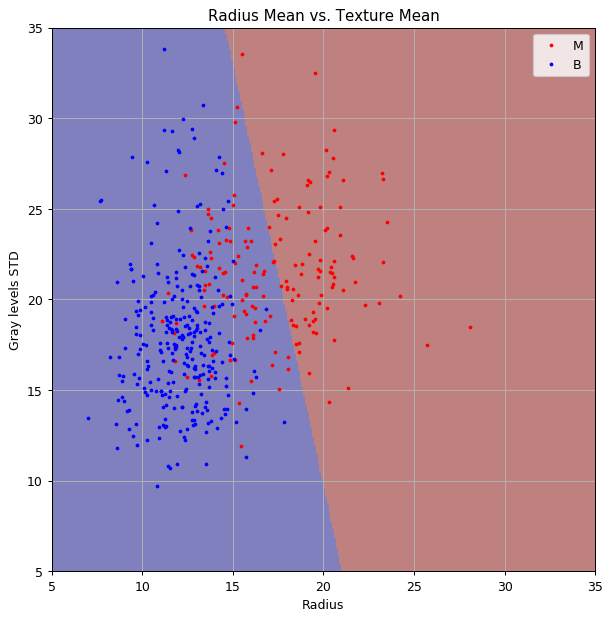
שיטה 1: LDA.
נבנה חזאי על ידי שימוש בLDA.
שיטה 1: LDA - המשך
החזאי המקבל הינו:
כאשר:
שיטה 1: LDA - המשך 2
נשרטט את הפילוגים הנורמאלים המתקבלים ואת קו ההפרדה הליניארי על גבי הנתונים:
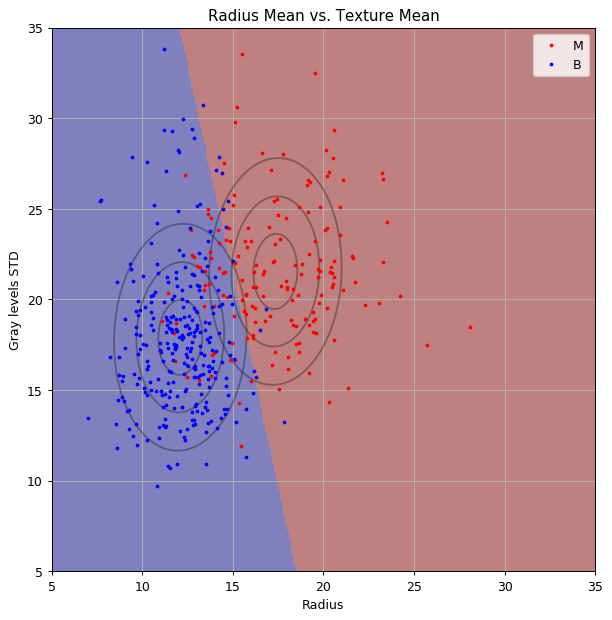
שיטה 1: LDA - המשך 3
הערכת ביצועים
נשערך את ביצועי החזאי על ידי חישוב הסיכון האמפירי המתקבל על סט הבחן.
הסיכון המשוערך המתקבל הינו: 0.096
✍️ תרגיל 6.3
א) הציעו שיטה להעריך את מידת הודאות של החיזוי על סמך המודל שקיבלנו.
ב) כיצד היה משתנה החזאי במידה והיינו יודעים כי הסיכוי הא-פריוירי של דגימה להיות סרטנית הינה 5% (ולא כמו הפילוג המופיע במדגם)
✍️ תרגיל 6.3 א
הציעו שיטה להעריך את מידת הודאות של החיזוי על סמך המודל שקיבלנו.
פתרון
אלגוריתם גנרטיבי -> שיערכנו מודל ההסתברותי המלא ->
נוכל לשערך את ההסתברות לקבל תווית מסויימת בהניתן התצפיות.
הסיכוי של דגימה נתונה להיות סרטנית נתון על ידי:
כאשר:
- , ו הם הפרמטרים שכבר שיערכנו.
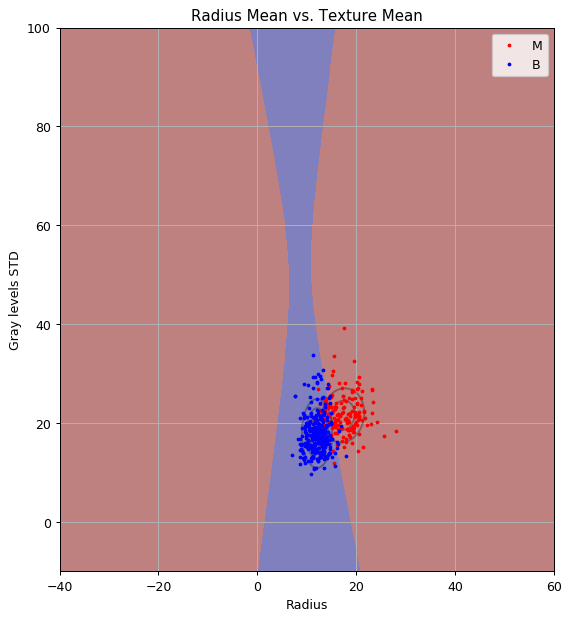
✍️ תרגיל 6.3 ב
כיצד היה משתנה החזאי במידה והיינו יודעים כי הסיכוי הא-פריוירי של דגימה להיות סרטנית הינה 5% (ולא כמו הפילוג המופיע במדגם)
פתרון
נוכל להשתמש בפילוג הידוע של במקום לשערך אותו. (כל שאר החישוב יהיה זהה).
במקרה של LDA, פילוג זה מופיע רק באיבר של פונקצייית החיזוי, אשר מגדיר את המיקום של משטח ההפרדה.
נשתמש כעת ב:
✍️ תרגיל 6.3 ב - המשך
ונקבל את פונקציית החיזוי הבאה:
קו ההפרדה זז לימין.
הפילוג הא-פריורי מקטין את ההסתברות שדגימה מסויימת הינה סרטנית, שמתבטא באופן דומה גם בסיכוי הפוסטריורי. לכן איזור גדול יותר ממופה כעת לתווית של “לא סרטני”.
שיטה 2: QDA
נבנה חזאי על ידי שימוש בQDA.
נחשב מטריצת covariance בעבור כל אחת מהתוויות בנפרד (שאר הפרמטרים לא משתנים).
החזאי המקבל הינו:
כאשר:
שיטה 2: QDA - המשך
נשרטט את הפילוגים הנורמאלים המתקבלים ואת קו ההפרדה על גבי הנתונים:
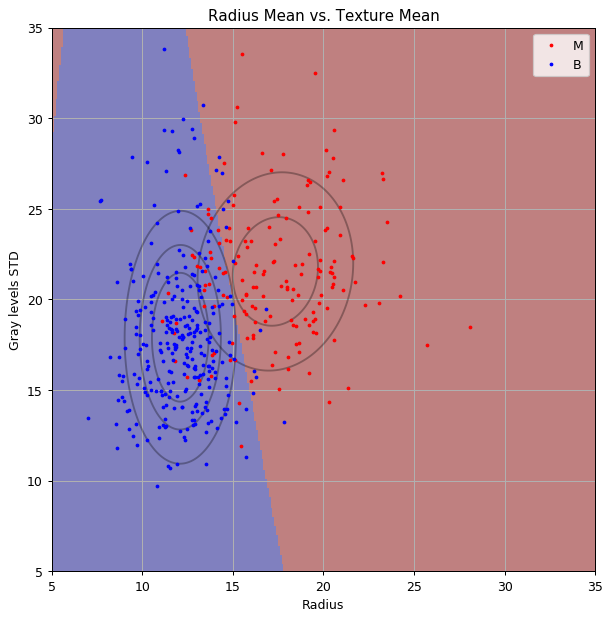
הסיכון המשוערך על סט הבחן הינו: 0.088 (קיבלנו שיפור קל בביצועים)
הגדלת כמות השדות בוקטור התצפיות
נחזור על תהליך של חיזוי בשיטת QDA כאשר אנו לוקחים בכל פעם את השדות הראשונים במדגם.
נשרטט את הסיכון המתקבל על סט האימון ועל סט הבחן כתלות ב:
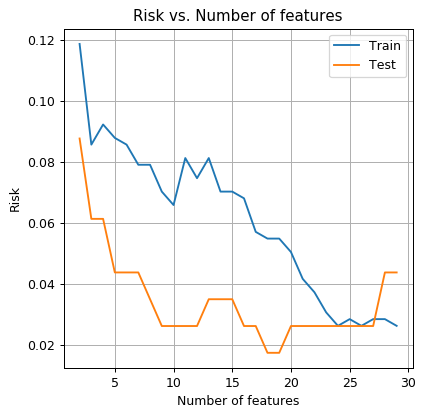
תרגיל 6.4
כיצד תסבירו את העובדה כי מנקודה מסויימת הסיכון על סט הבחן הולך ונעשה גרוע ככל שאנו מגדילים את כמות השדות? מהי כמות הפרמטרים במודל כתלות ב (מספר השדות)? מה גודלו של סט האימון?
הציעו מניפולציה אותה ניתן לעשות למדגם על מנת לבנות חזאי אשר כן משתמש במידע מכל השדות אך עם מספר פרמטרים מוגבל.
תרגיל 6.4 - פתרון
- זוהי דוגמא קלסית להתאמת יתר (overfitting).
- ככל שמספר השדות גדל, מספר הפרמטרים של המודל גדל והמודל יכול לייצג תלויות יותר ויותר מורכבות.
- בQDA מספר הפרמטרים הינו בערך , במקרה של 30 שדות יש במודל בערך 900 פרמטרים בעוד שסט האימון יש דגימות.
- ככלל אצבע, נרצה לרוב שמספר הפרמטרים במודל שלנו יהיה קטן בלפחות סדר גודל אחד ממספר הדגמים בסט האימון (נכון חלקית).
דרך אחת להתמודד עם בעיה זו הינה לבצע הורדת מימד לוקטור התצפיות בשיטות כגון PCA.
תרגיל 6.6 - פונקציית הפסד לא סימטרית
נסתכל על בעיית החיזוי הבאה.
ידוע הפילוג המשותף של שני משתנים אקראיים ו , כאשר הוא משתנה בינארי. כמו כן נתונה לנו פונקציית ההפסד הבאה:
מצאו ביטוי לחזאי האופטימאלי של בהינתן אשר ממזער את פונקציית הסיכון המתאימה לפונקציית ההפסד הנתונה.
תרגיל 6.6 - פונקציית הפסד לא סימטרית - המשך
פתרון
בעבור נקבל:
ובעבור נקבל:
תרגיל 6.6 - פונקציית הפסד לא סימטרית - המשך 2
פתרון
מכאן שהחזאי האופטימאלי יהיה: